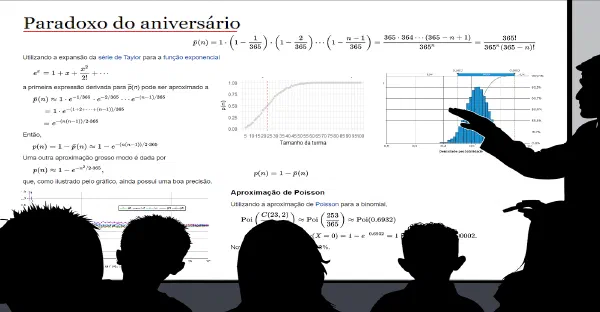
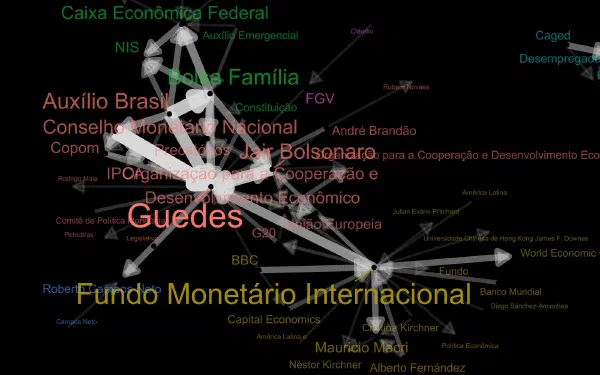
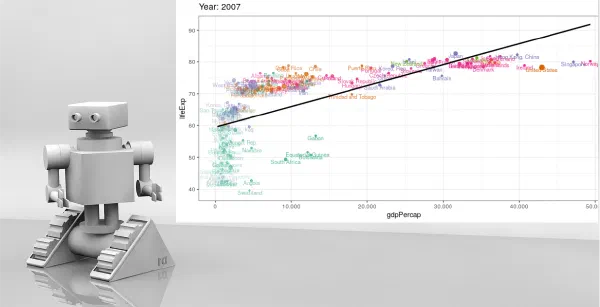
Fellipe Gomes
Data Science Specialist @ Accenture | Kaggle Master
Formado em Estatística e Probabilidade, atuo como Cientista de Dados com foco em Machine Learning e Inteligência Artificial desde 2017. Criei este blog para compartilhar soluções, técnicas e ferramentas que fazem parte da minha jornada.
Mentoria · vagas limitadas
Estou abrindo poucas vagas de mentoria gratuita em Data Science e IA.
Sessões pelo ADPList. Garanta a sua.
Agende uma mentoria →