




































Ajustando Modelos Bayesianos com JAGS
Introdução à inferência bayesiana com implementação prática em R usando JAGS e MCMC. Distribuições a priori, verossimilhança e amostragem de Gibbs.

Inferência bayesiana
Quando estamos falando de Inferência nosso objetivo normalmente é tentar verificar alguma informação sobre uma quantidade desconhecida.
Para isso devemos utilizar toda informação disponível, seja ela objetiva ou subjetiva (isto é, vinda de umam amostra ou de algum conhecimento préveo ou intuitivo)
Segundo o ponto de vista Bayesiano essa informação subjetiva também será incorporada na análise graças ao teorema de bayes.
Como no ponto de vista Bayesiano atribuímos aleatoriedade ao parâmetro, nossa “crença” será representada por uma distribuição de probabilidade (ou modelo probabilístico)
Teorema de bayes: \[ p(\theta|x)=\frac{p(x,\theta)}{p(x)}=\frac{p(x|\theta)p(\theta)}{p(x)} \]
onde:
- \(p(x|\theta)\): função de verossimilhança (modelo)
- \(p(\theta)\): distribuição a priori
- \(p(x)\): distribuição marginal de \(x\).
A estimação muitas vezes envolve o cálculo de integrais nada simples analiticamente porém, alguns algorítimos como o amostrador de Gibbs pode relizar aproximações muito relevantes.
Modelo linear bayesiano
Para entender como funciona o modelo bayesiano, primeiramente vamos começar com algo bem simples, suponha:
\[ Y_i \sim N(\mu_i,\tau) \] onde \(\mu\) é definido como \(\mu_i= X \mathbf{\beta}\).
Incialmente vamos considerar que não existe relação nenhuma, então utilizaremos a priori:
\[ \beta \sim N(0,\tau_{\beta}) \]
onde \(\tau\) é conhecido.
Nem sempre é uma tarefa simples determinar a distribuição posteri de um modelo bayesiano e é neste ponto que o pacote jagsserá bastante útil (existem outras alternativas como o WinBugs, OpenBugs, Stan, mas aqui resolvi trazer apenas o jags por possuir vantagens bem interessantes.)
Jags
O pacote R2jags é exatamente o que seu nome significa: “Just Another Gibbs Sampler”. Possui as mesmas funcionalidades do nosso querido OpenBugs possibilitando também que seja utilizado inteiramente dentro do ambiente R.
Assim como o OpenBugs, ele também trabalha chamando o software oficial que precisa ser baixado no site.
Para começar a utilizar basta baixar o pacote e acessá-lo na biblioteca:
library(R2jags)Declarando o modelo
A base de dados que será utilizada para ajustar o modelo será a base nativa do R chamada trees:
X<-trees[,1:2] #Matriz de variáveis explanatórias
Y<- trees[,3] #Vetor da variável resposta
p <- ncol(X) #p é o número de parâmetros do modelo (nesse caso é o número de colunas)
n <- nrow(X) #n é o número de observações do modeloO modelo deve estar declarado e salvo em um arquivo .txt (ou mesmo um outro arquivo .r) da seguinte maneira:
### Declarando o modelo Bayesiano
sink("linreg.txt")
cat("
model {
# Prioris
for(j in 1:p)
{
beta[j] ~ dnorm(mu.beta, tau.beta)
}
sigma ~ dunif(0, 100)
tau <- 1/ (sigma * sigma)
# Verossimilhança
for (i in 1:n) {
y[i] ~ dnorm(mu[i], tau)
mu[i] <- inprod(X[i,], beta)
}
}
",fill=TRUE)
sink()Uma vez que o modelo esta declarado, é a hora de nomear os parametros da função que fará o ajuste do modelo
#Parametros da Priori
mu.beta <- 0
tau.beta <- 0.001
#Set Working Directory
wd <- getwd()
# Junte os dados em uma lista
win.data <- list(X=X,y=Y,p=p,n=n,mu.beta=mu.beta,tau.beta=tau.beta)
# Função de inicialização
inits <- function(){ list(beta=rnorm(p), sigma = rlnorm(1))}
# Os parametros que desejamos estimar
params <- c("beta","sigma","tau")
# Caracteristicas do MCMC
n.burnin <- 500 #Número de iterações que serão descartadas
n.thin <- 10 #para economizar memória e tempo de computação se n.iter for grande
n.post <- 5000
n.chains <- 3 #Número de cadeias
n.iter <- n.burnin + n.thin*n.post #Número de iteraçõesImplementando o modelo
Após ter em mãos todos esses resultados, já podemos ajustar o modelo com o comando jags(), veja:
bayes.mod.fit <-jags(data = win.data,
inits = inits,
parameters = params,
model.file = "linreg.txt", # O arquivo "linreg.txt" deve estar no mesmo diretório
n.iter = n.iter,
n.thin=n.thin,
n.burnin=n.burnin,
n.chains=n.chains,
working.directory=wd,DIC = T)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 31
## Unobserved stochastic nodes: 3
## Total graph size: 166
##
## Initializing modelprint(bayes.mod.fit, dig = 3)## Inference for Bugs model at "linreg.txt", fit using jags,
## 3 chains, each with 50500 iterations (first 500 discarded), n.thin = 10
## n.sims = 15000 iterations saved
## mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
## beta[1] 5.045 0.435 4.183 4.757 5.043 5.324 5.916 1.001 15000
## beta[2] -0.478 0.078 -0.633 -0.527 -0.477 -0.427 -0.324 1.001 15000
## sigma 6.448 0.904 4.995 5.805 6.335 6.970 8.502 1.001 15000
## tau 0.025 0.007 0.014 0.021 0.025 0.030 0.040 1.001 15000
## deviance 201.924 2.682 198.881 199.970 201.244 203.149 208.856 1.001 7200
##
## For each parameter, n.eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor (at convergence, Rhat=1).
##
## DIC info (using the rule, pD = var(deviance)/2)
## pD = 3.6 and DIC = 205.5
## DIC is an estimate of expected predictive error (lower deviance is better).Com os resultados em mãos podemos avaliar o ajuste do modelo, o jags nos fornece os intervalos de credibilidade e o Rhat, que é a convergência da cadeia, a princípio vamos apenas considerar o fato de que quanto mais próximo de 1, melhor são as estimativas.
Não vou me extender neste post com a interpretação do modelo pois o objetivo esta sendo mostrar a funcionalidade do jags em conjunto com o R.
Diagnósticos do modelo com mcmcplots
Para o diagnóstico do modelo podemos utilizar o pacote mcmcplots que fornece de maneira bem agradável os resultados gerados pelo amostrador, primeiramente vamos carregar o pacote:
library(mcmcplots)Em seguida precisar informar para o R que o resultado do algorítimo se trata de um objeto mcmc, portanto:
bayes.mod.fit.mcmc <- as.mcmc(bayes.mod.fit)
summary(bayes.mod.fit.mcmc)##
## Iterations = 1:49991
## Thinning interval = 10
## Number of chains = 3
## Sample size per chain = 5000
##
## 1. Empirical mean and standard deviation for each variable,
## plus standard error of the mean:
##
## Mean SD Naive SE Time-series SE
## beta[1] 5.04490 0.435344 3.555e-03 3.555e-03
## beta[2] -0.47754 0.077588 6.335e-04 6.335e-04
## deviance 201.92383 2.682384 2.190e-02 2.144e-02
## sigma 6.44763 0.903646 7.378e-03 7.359e-03
## tau 0.02542 0.006784 5.539e-05 5.524e-05
##
## 2. Quantiles for each variable:
##
## 2.5% 25% 50% 75% 97.5%
## beta[1] 4.18250 4.75721 5.04333 5.32437 5.91642
## beta[2] -0.63255 -0.52732 -0.47726 -0.42674 -0.32376
## deviance 198.88143 199.97019 201.24393 203.14881 208.85648
## sigma 4.99470 5.80492 6.33492 6.96990 8.50193
## tau 0.01383 0.02058 0.02492 0.02968 0.04008O pacote nos fornece alguns tipos de gráficos para diagnóstico
caterplot(bayes.mod.fit.mcmc) #Observando todas as estimativas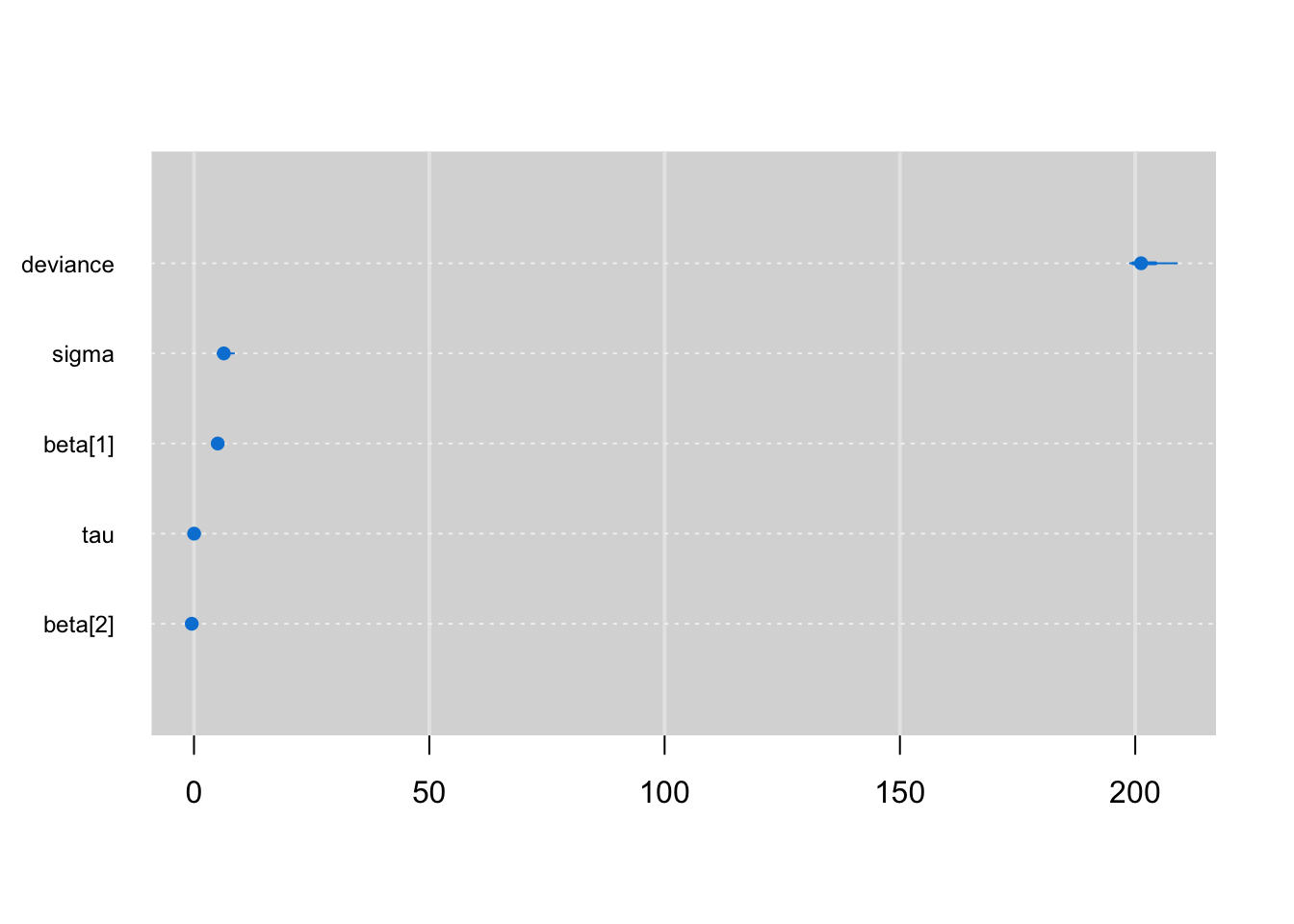
caterplot(bayes.mod.fit.mcmc,parms = params) #Observando as estimativas de todos os parâmetros menos o desvio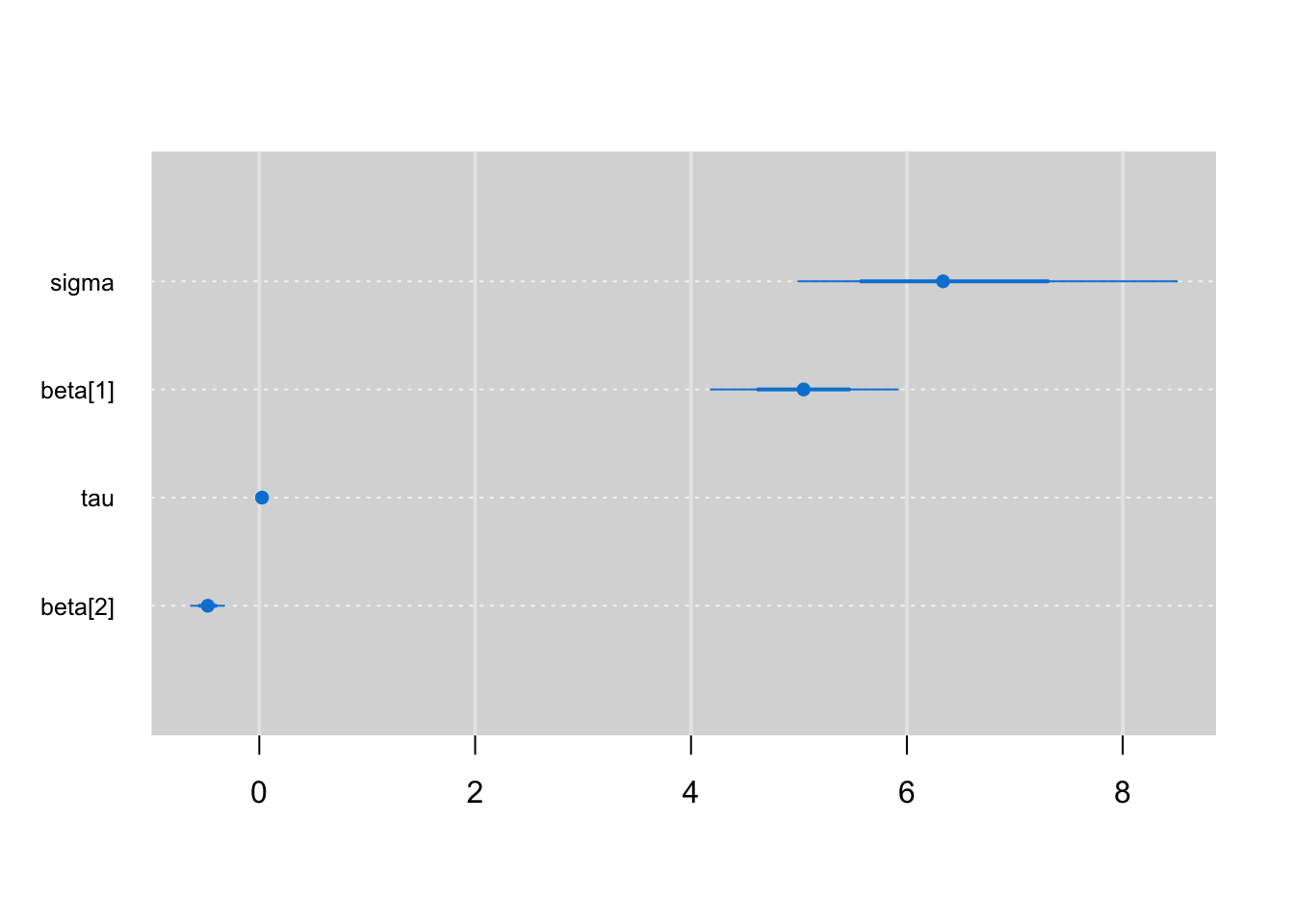
denplot(bayes.mod.fit.mcmc) #Densidade das estimativas de cada cadeia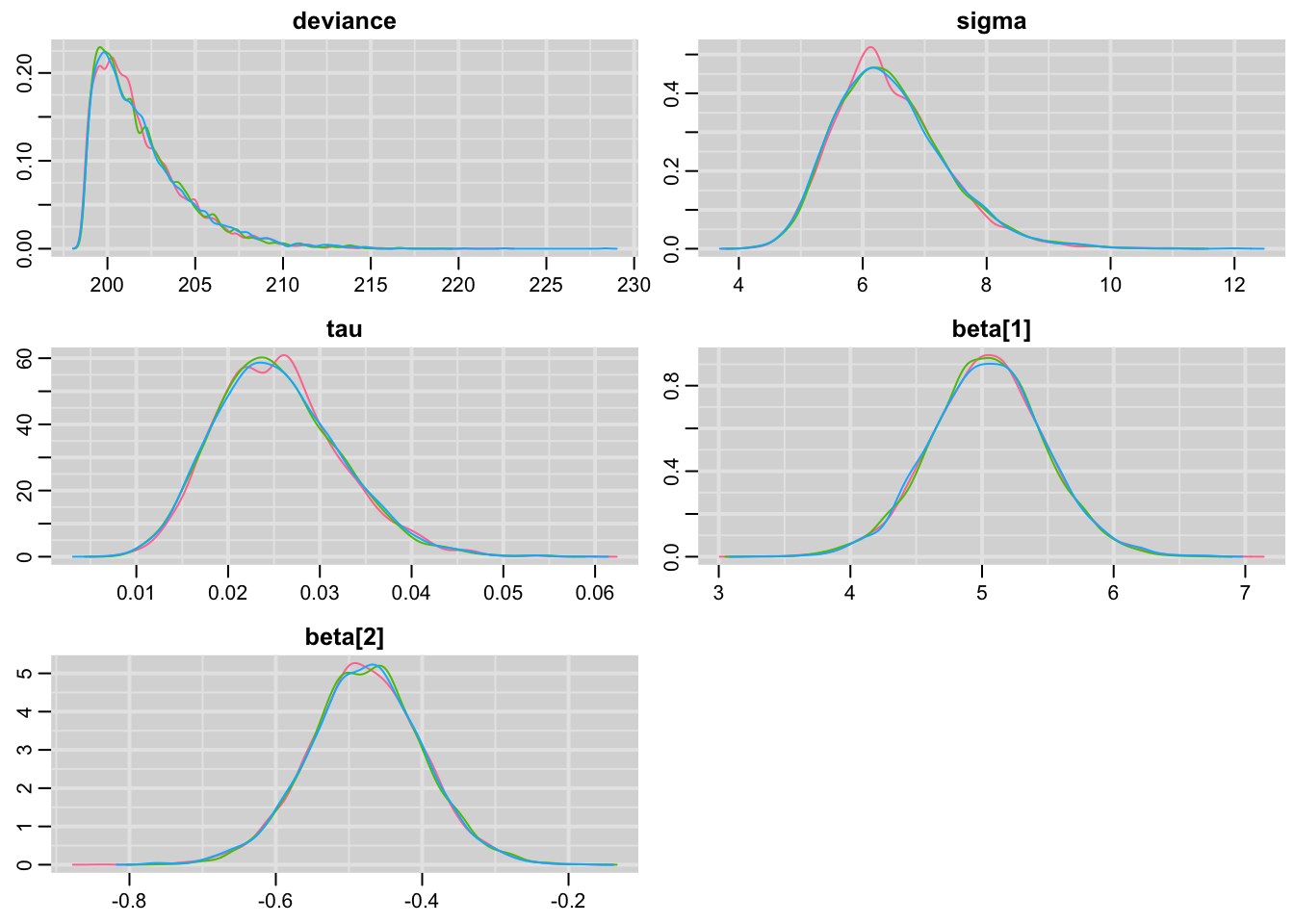
traplot(bayes.mod.fit.mcmc,greek = T) #Avaliando a convergência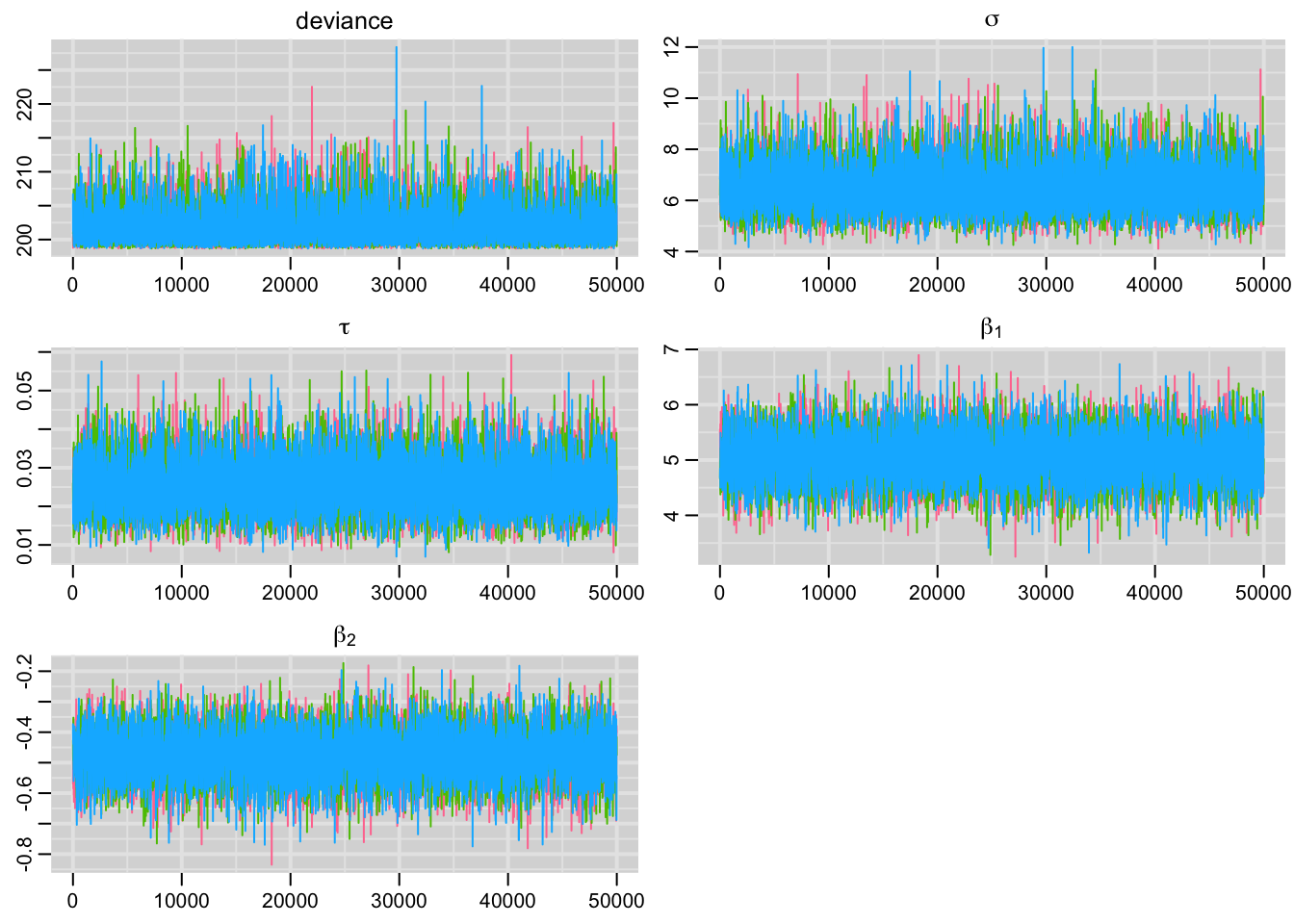
E por fim, para diagnósticos rápidos, pode produzir arquivos html com traço, densidade e autocorrelação.
O comando traça tudo em uma página e os arquivos serão exibidos em seu navegador de internet padrão.
mcmcplot(bayes.mod.fit.mcmc)Vai retornar um relatório resumido para todos os parâmetros como nesta imagem da internet como:
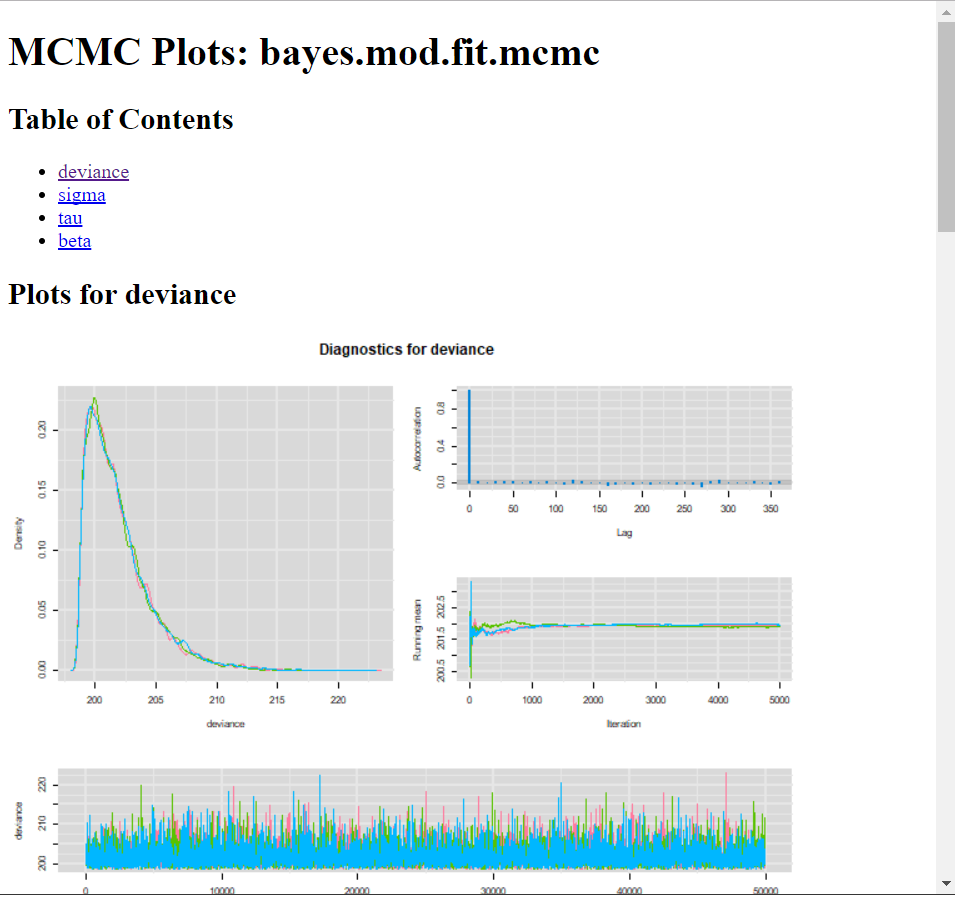
Como o objetivo do post é trazer a funcionalidade do pacote, vou apenas deixar ilustrado quais são algumas das funções mais comumente utilizadas para avaliar estatísticamente o desempenho dos modelos.
Diagnosticos estatísticos do modelo:
#Mais diagnosticos:
gelman.plot(bayes.mod.fit.mcmc)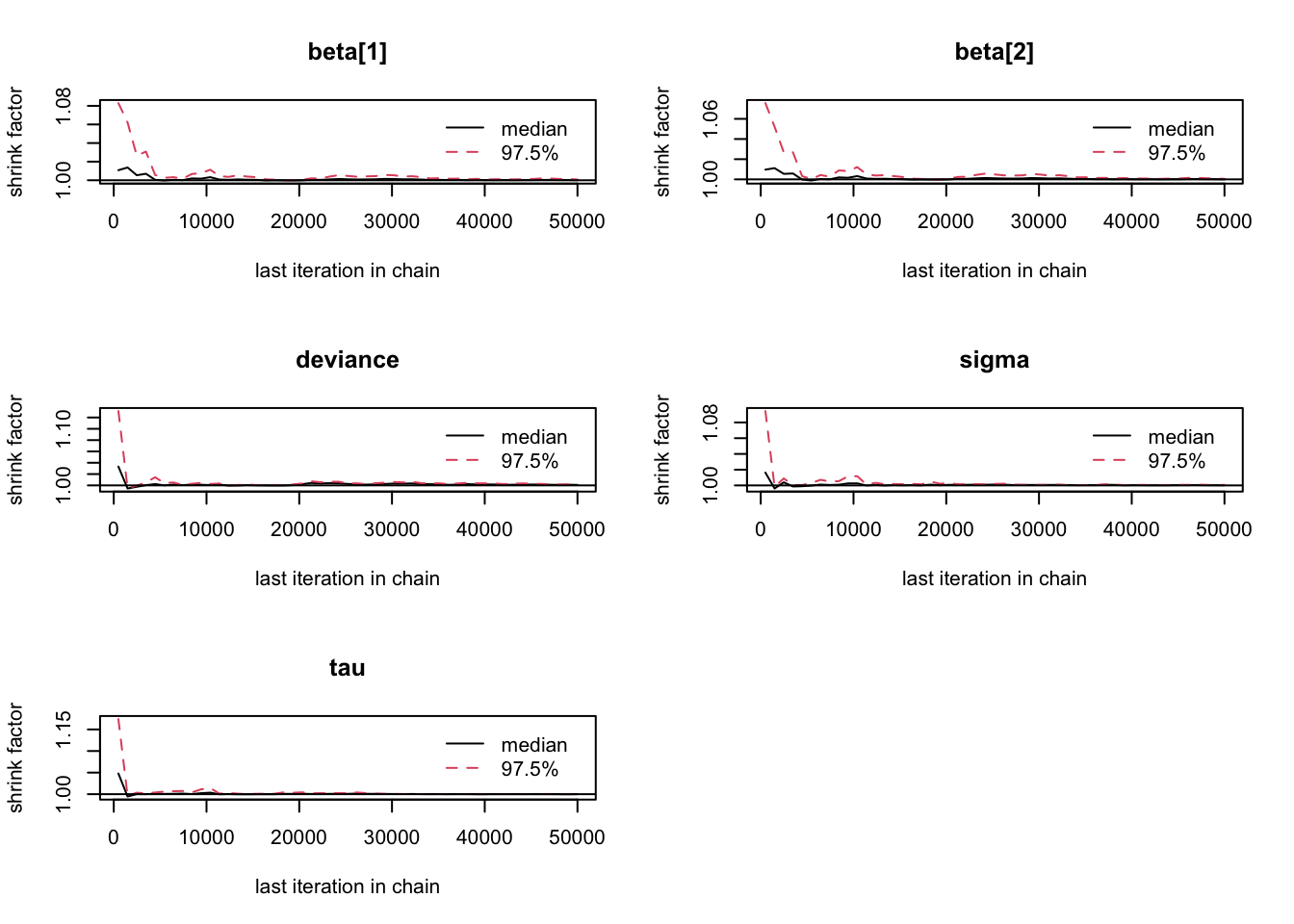
geweke.diag(bayes.mod.fit.mcmc)## [[1]]
##
## Fraction in 1st window = 0.1
## Fraction in 2nd window = 0.5
##
## beta[1] beta[2] deviance sigma tau
## -1.6717 1.1790 -0.4485 0.1854 -0.6815
##
##
## [[2]]
##
## Fraction in 1st window = 0.1
## Fraction in 2nd window = 0.5
##
## beta[1] beta[2] deviance sigma tau
## 0.37278 -0.36960 -0.24342 -0.08007 0.30725
##
##
## [[3]]
##
## Fraction in 1st window = 0.1
## Fraction in 2nd window = 0.5
##
## beta[1] beta[2] deviance sigma tau
## -0.15725 0.19911 -0.08445 -0.34043 0.35357geweke.plot(bayes.mod.fit.mcmc)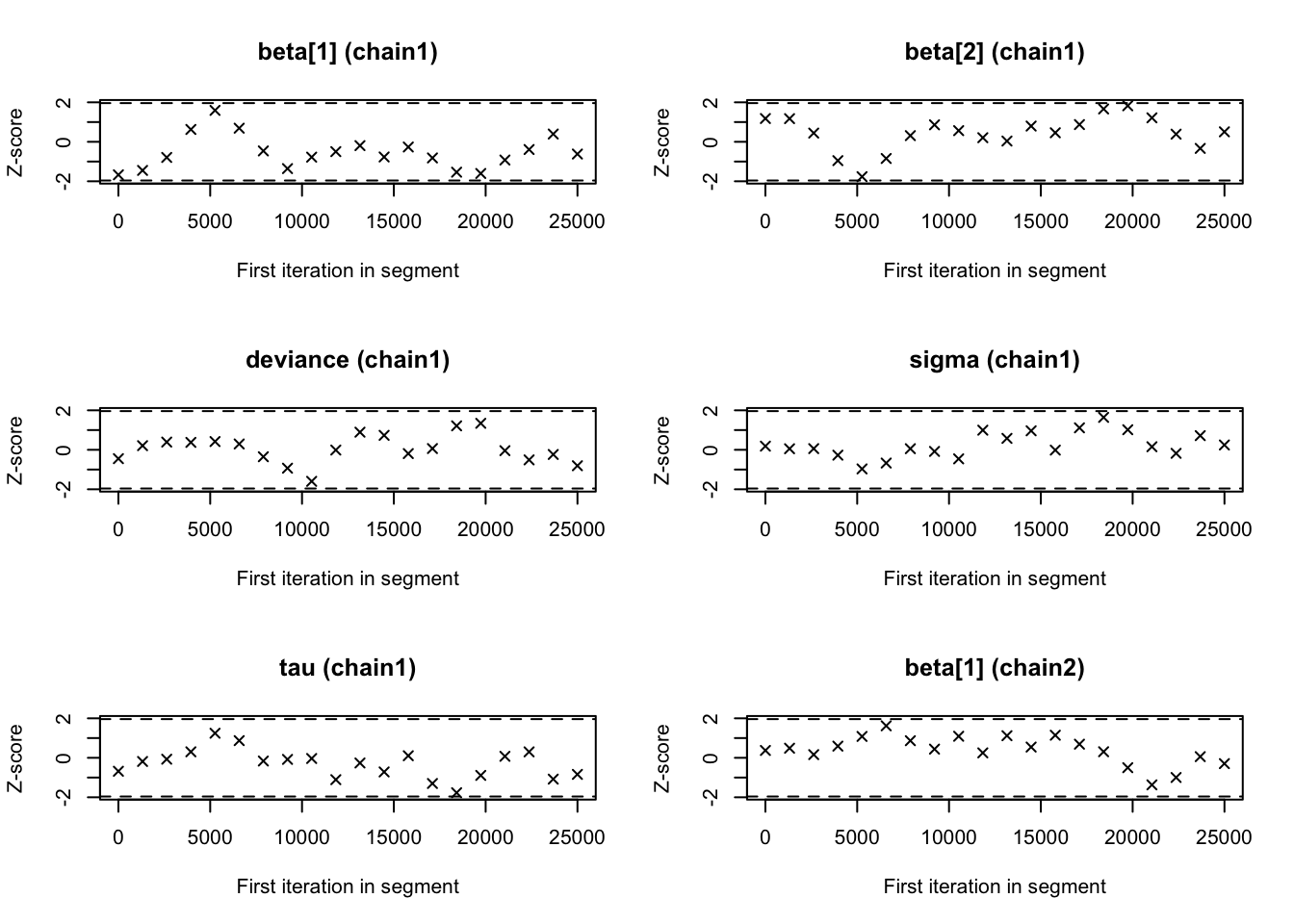
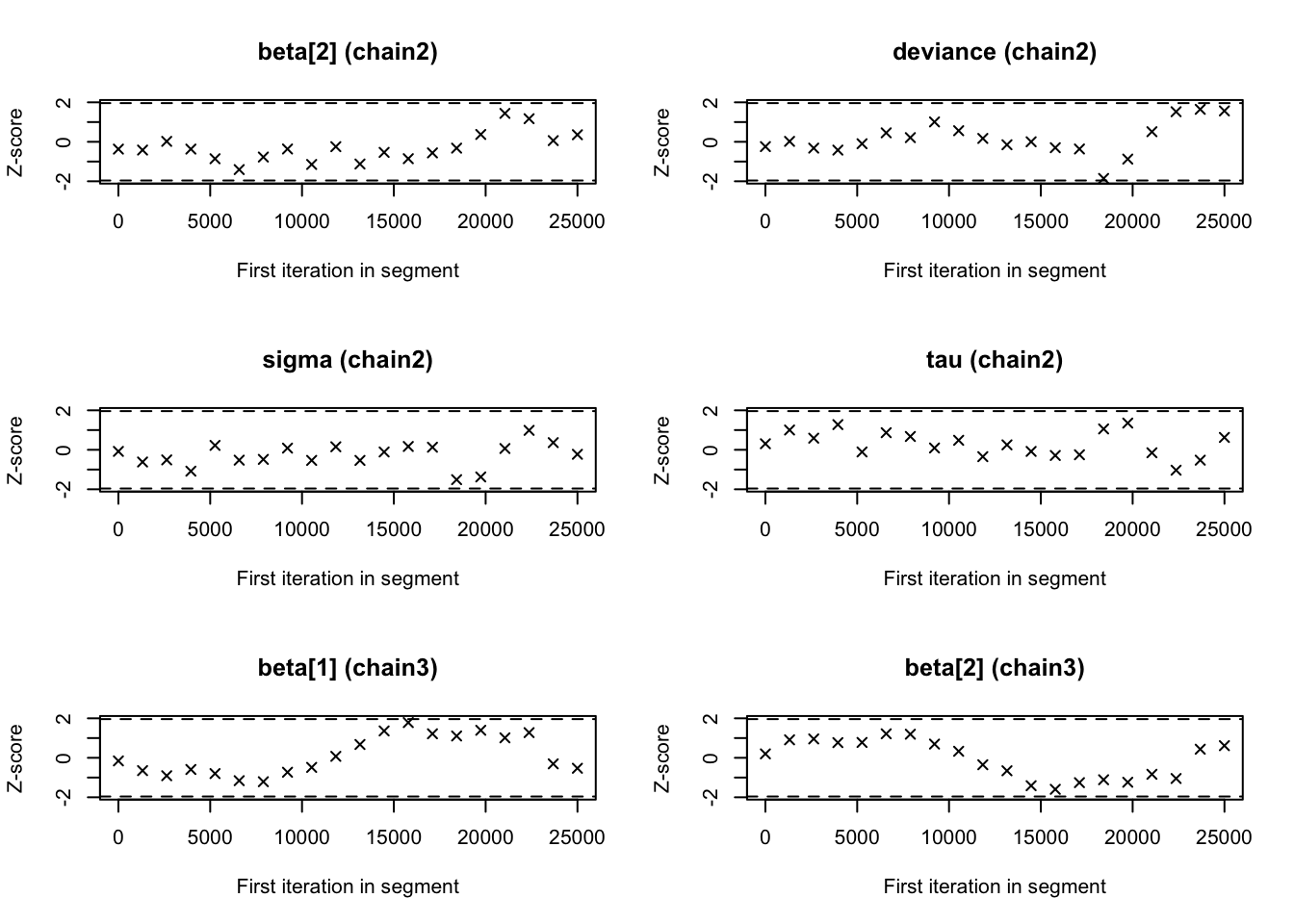
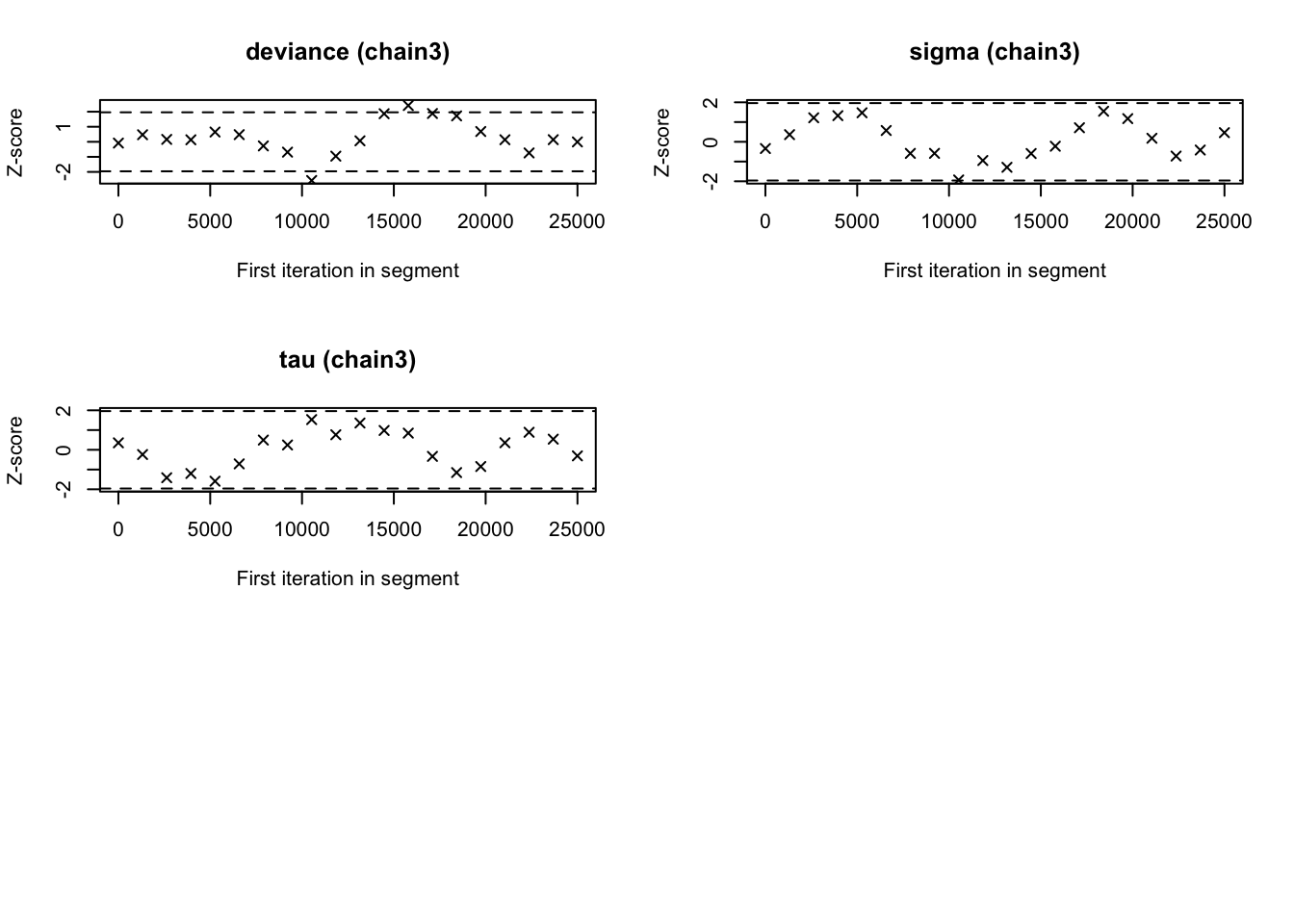
raftery.diag(bayes.mod.fit.mcmc)## [[1]]
##
## Quantile (q) = 0.025
## Accuracy (r) = +/- 0.005
## Probability (s) = 0.95
##
## Burn-in Total Lower bound Dependence
## (M) (N) (Nmin) factor (I)
## beta[1] 20 39950 3746 10.70
## beta[2] 20 36200 3746 9.66
## deviance 20 37410 3746 9.99
## sigma 20 38030 3746 10.20
## tau 20 36800 3746 9.82
##
##
## [[2]]
##
## Quantile (q) = 0.025
## Accuracy (r) = +/- 0.005
## Probability (s) = 0.95
##
## Burn-in Total Lower bound Dependence
## (M) (N) (Nmin) factor (I)
## beta[1] 20 38030 3746 10.20
## beta[2] 20 36800 3746 9.82
## deviance 20 37410 3746 9.99
## sigma 20 37410 3746 9.99
## tau 20 35610 3746 9.51
##
##
## [[3]]
##
## Quantile (q) = 0.025
## Accuracy (r) = +/- 0.005
## Probability (s) = 0.95
##
## Burn-in Total Lower bound Dependence
## (M) (N) (Nmin) factor (I)
## beta[1] 20 37410 3746 9.99
## beta[2] 20 38030 3746 10.20
## deviance 20 37410 3746 9.99
## sigma 30 40620 3746 10.80
## tau 20 39300 3746 10.50heidel.diag(bayes.mod.fit.mcmc)## [[1]]
##
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.292
## beta[2] passed 1 0.455
## deviance passed 1 0.733
## sigma passed 1 0.881
## tau passed 1 0.816
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.0481 0.012089
## beta[2] passed -0.4780 0.002155
## deviance passed 201.8829 0.073069
## sigma passed 6.4367 0.024544
## tau passed 0.0255 0.000187
##
## [[2]]
##
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.246
## beta[2] passed 1 0.249
## deviance passed 1 0.967
## sigma passed 1 0.950
## tau passed 1 0.770
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.0386 0.011955
## beta[2] passed -0.4765 0.002134
## deviance passed 201.9023 0.068414
## sigma passed 6.4571 0.025014
## tau passed 0.0253 0.000188
##
## [[3]]
##
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.657
## beta[2] passed 1 0.690
## deviance passed 1 0.544
## sigma passed 1 0.813
## tau passed 1 0.873
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.0480 0.012156
## beta[2] passed -0.4781 0.002163
## deviance passed 201.9863 0.076685
## sigma passed 6.4491 0.025385
## tau passed 0.0254 0.000188Diagnostico de convergencia rapida: superdiag
Uma função muito conveniente para analisar representações numéricas de diagnósticos em um ajuste é o pacote superdiag de Tsai, Gill e Rapkin, 2012 que trás uma série de estatísticas para avaliar o desempenho dos ajustes do modelo.
library(superdiag)
superdiag(bayes.mod.fit.mcmc, burnin = 100)## Number of chains = 3
## Number of iterations = 5000 per chain before discarding the burn-in period
## Burn-in period = 100 per chain
## Sample size in total = 14703
##
## ****************** The Geweke diagnostic: ******************
## Windows:
## chain 1 chain 2 chain 3
## From start 0.1 0.5420 0.2999
## From stop 0.5 0.3511 0.6893
##
## Z-scores:
## chain 1 chain 2 chain 3
## beta[1] -1.85586 0.3331 -1.66699
## beta[2] 1.57605 -0.2271 1.53584
## deviance 0.02463 0.3356 -1.14324
## sigma -0.15363 -0.8820 -0.33962
## tau -0.09745 0.9937 0.01232
##
## *************** The Gelman-Rubin diagnostic: ***************
## Potential scale reduction factors:
## Point est. Upper C.I.
## beta[1] 1.0001 1.001
## beta[2] 1.0000 1.000
## deviance 1.0009 1.002
## sigma 1.0002 1.001
## tau 0.9999 1.000
##
## Multivariate psrf: 1.0005
##
## ************* The Heidelberger-Welch diagnostic ************
## Chain 1:
## epsilon=0.1, alpha=0.05
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.1576
## beta[2] passed 1 0.2864
## deviance passed 1 0.8399
## sigma passed 1 0.8207
## tau passed 1 0.7405
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.04671 0.012211
## beta[2] passed -0.47775 0.002177
## deviance passed 201.89097 0.074094
## sigma passed 6.43566 0.024772
## tau passed 0.02549 0.000189
##
## Chain 2:
## epsilon=0.079, alpha=0.1
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.3032
## beta[2] passed 1 0.3259
## deviance passed 1 0.9562
## sigma passed 1 0.7462
## tau passed 1 0.5362
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.03850 0.0120853
## beta[2] passed -0.47646 0.0021574
## deviance passed 201.90084 0.0693125
## sigma passed 6.45467 0.0252168
## tau passed 0.02536 0.0001894
##
## Chain 3:
## epsilon=0.054, alpha=0.005
## Stationarity start p-value
## test iteration
## beta[1] passed 1 0.5489
## beta[2] passed 1 0.5665
## deviance passed 1 0.5038
## sigma passed 1 0.8038
## tau passed 1 0.8898
##
## Halfwidth Mean Halfwidth
## test
## beta[1] passed 5.04719 0.0122925
## beta[2] passed -0.47794 0.0021858
## deviance passed 201.98956 0.0775537
## sigma passed 6.44893 0.0256817
## tau passed 0.02544 0.0001937
##
## *************** The Raftery-Lewis diagnostic ***************
## Chain 1:
## Convergence eps = 0.001
## Quantile (q) = 0.025
## Accuracy (r) = +/- 0.005
## Probability (s) = 0.95
##
## Burn-in Total Lower bound Dependence
## (M) (N) (Nmin) factor (I)
## beta[1] 30 40170 3746 10.70
## beta[2] 20 36340 3746 9.70
## deviance 20 38200 3746 10.20
## sigma 20 38200 3746 10.20
## tau 20 36950 3746 9.86
##
## Chain 2:
## Convergence eps = 5e-04
## Quantile (q) = 0.25
## Accuracy (r) = +/- 0.001
## Probability (s) = 0.99
##
## You need a sample size of at least 1244044 with these values of q, r and s
##
## Chain 3:
## Convergence eps = 0.005
## Quantile (q) = 0.25
## Accuracy (r) = +/- 5e-04
## Probability (s) = 0.999
##
## You need a sample size of at least 8120675 with these values of q, r and s
##
## ************* The Hellinger distance diagnostic ************
## Between chains:
## Min Max
## beta[1] 0.01735 0.02915
## beta[2] 0.02015 0.02620
## deviance 0.03155 0.03413
## sigma 0.01858 0.02731
## tau 0.01538 0.02810
##
## Within chain 1:
## 980 1960 2940 3920
## beta[1] 0.05231 0.03952 0.04017 0.04259
## beta[2] 0.04261 0.05034 0.04320 0.04782
## deviance 0.05880 0.04060 0.06297 0.04311
## sigma 0.03871 0.03667 0.06465 0.04285
## tau 0.03668 0.03996 0.03633 0.04083
##
## Within chain 2:
## 980 1960 2940 3920
## beta[1] 0.03098 0.04075 0.04281 0.03887
## beta[2] 0.03050 0.03770 0.03887 0.04216
## deviance 0.04541 0.03992 0.03390 0.04730
## sigma 0.04660 0.03876 0.03090 0.02866
## tau 0.03648 0.03773 0.02967 0.03589
##
## Within chain 3:
## 980 1960 2940 3920
## beta[1] 0.03356 0.03988 0.03146 0.02986
## beta[2] 0.03425 0.04729 0.03175 0.03219
## deviance 0.05894 0.03553 0.05018 0.04509
## sigma 0.04392 0.04245 0.03858 0.03760
## tau 0.04089 0.03458 0.04512 0.03047Para finalizar, outra função que pode ser útil pata atualizando o modelo, se necessário - por exemplo, se não houver convergência ou pouca convergencia:
bayes.mod.fit.upd <- update(bayes.mod.fit, n.iter=1000)
bayes.mod.fit.upd <- autojags(bayes.mod.fit)Muito a estudar
Assim como toda a Estatística, inferência bayesiana não funciona se a teoria não for aplicada corretamente. É uma ferramenta muito poderosa e necessita ser usada com cautela pois demanda bastante o uso de metodologias estatísticas.
Como dizia o tio Ben: “grandes poderes trazem grandes responsabilidades” então vamos tomar cuidado com os resultados que encontramos.


{kind=link}
Share this post
Twitter
LinkedIn
Email