




































Análise de Sentimentos com um "ChatGPT" de Código Aberto
Como executar localmente o LLM pré-treinado de código aberto Llama2 para realizar uma análise de sentimentos em Python

Por que Análise de Sentimentos?
Compreender os sentimentos por trás de grandes volumes de texto tornou-se essencial, pois em um mundo cada vez mais digitalizado, a capacidade de compreender as respostas e emoções em larga escala das pessoas diante de produtos, eventos ou tópicos específicos não é apenas valiosa por fornecer insights, mas também se tornou uma necessidade para alavancar negócios e tornar-se cada vez mais competitivo.
Análise de sentimento, também chamada de mineração de opinião, é o campo de estudo que analisa as opiniões, sentimentos, avaliações, apreciações, atitudes e emoções das pessoas em relação a entidades como produtos, serviços, organizações, indivíduos, questões, eventos, tópicos e seus atributos. Liu 2020
Por que Large Language Models?
A abordagem comum para resolver problemas de NLP envolviam a aplicação de text mining, embeddings como word2vec e GloVe (Global Vectors for Word Representation) e técnicas de Machine Learning, onde modelos como Random Forest, SVM, Naive Bayes, KNN, Ensembles e até mesmo Regressão eram frequentemente utilizados para classificar textos. Além disso, o uso de redes neurais recorrentes (RNNs) sempre foi uma alternativa valiosa, especialmente em situações que demandavam o processamento de dados sequenciais, sendo a LSTM (Long Short-Term Memory) uma variante eficaz para lidar com o desafio conhecido como vanishing gradient.
Já no cenário atual de modelos pré-treinados, o BERT (Bidirectional Encoder Representations from Transformers) também teve bastante destaque nesse domínio antes da ascensão do ChatGPT, demonstrando a viabilidade como um método gerador de texto e mostraram o poder que as redes neurais têm para gerar longas sequências de texto que antes pareciam inatingíveis.
![]() GPT-3 supera seus antecessores em termos de contagem de parâmetros
GPT-3 supera seus antecessores em termos de contagem de parâmetros
Embora já existam há algum tempo, os LLMs ganharam a mídia através do ChatGPT, interface de chat da OpenAI para modelos LLM GPT-3 lançado em 2020, com 175 milhões de parâmetros, que já teve uma série de avanços significativos nos últimos anos como seu irmão maior, o GPT-4 lançado em 2023 conta com incríveis 100 trílhões de parâmetros.
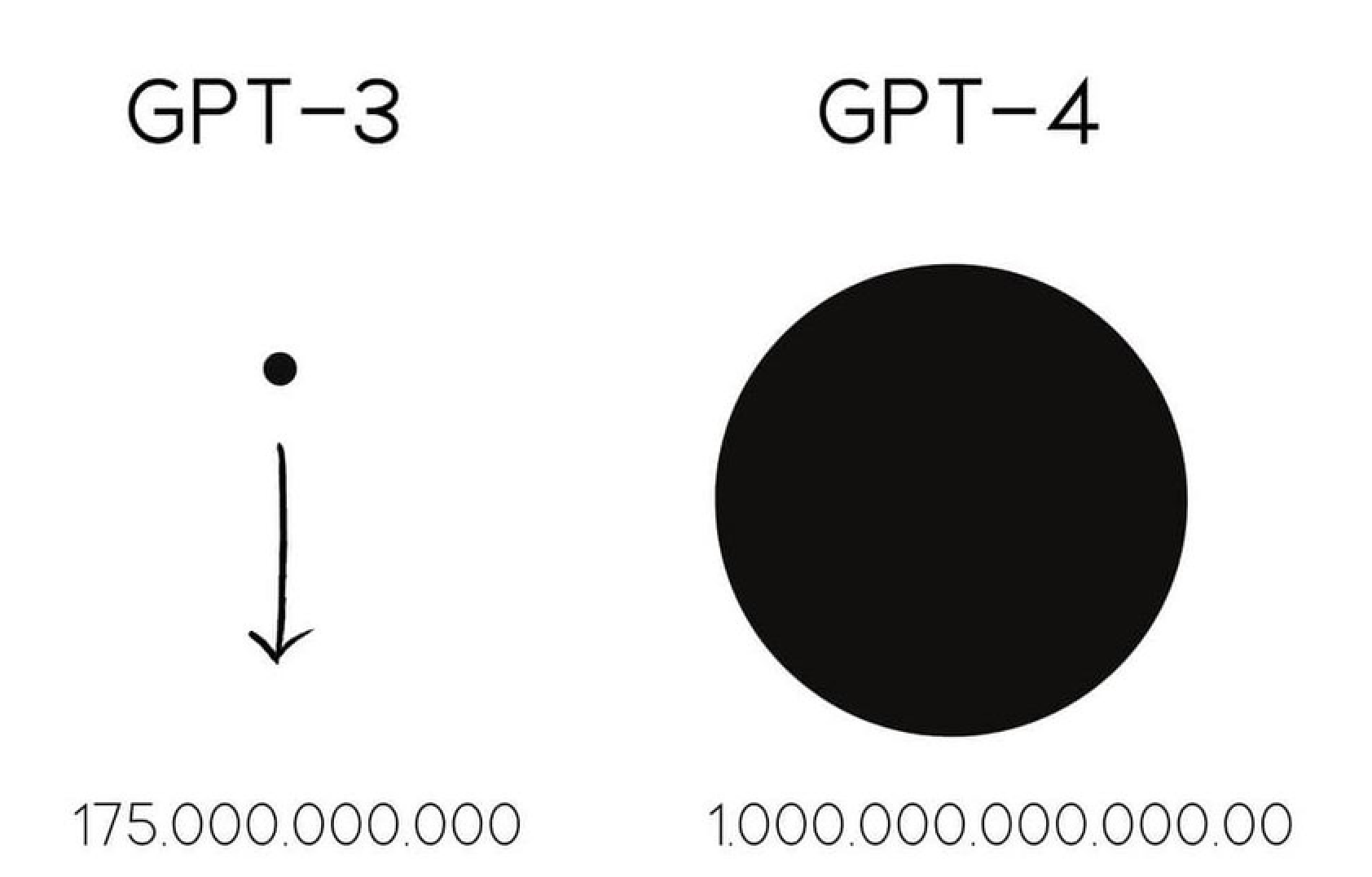 The comparison between GPT-3 and GPT-4 based on the number of parameters used in their architecture
The comparison between GPT-3 and GPT-4 based on the number of parameters used in their architecture
Modelos com mais de 100 bilhões de parâmetros já podem ser considerados muito grandes, com conhecimento mundial muito rico. Esses modelos maiores conseguem “aprender” ainda mais informações sobre muitas coisas sobre fisica, filosofia, ciência, programação, etc sendo cada vez mais úteis para ajudar em tarefas que envolvam conhecimento profundo ou raciocinio complexo, sendo um bom “parceiro” para brainstorming.
⚠️ Atenção! Afirmar que maiores modelos são sempre melhores não é verdade. O tempo de processamento, latência e o custo também irão aumentar, por isso abordagens alternativas também devem ser consideradas.
Como funcionam os LLMs?
Os LLMs são modelos de Machine Learning que usam algoritmos de Deep Learning para processar e compreender a linguagem natural, gerando texto de maneira eficaz. Esses modelos são treinados com grandes volumes de dados da internet, adquirindo a capacidade de identificar padrões na composição de palavras e frases. A idéia básica por trás desses modelos é que são capazes de gerar texto prevendo repetidamente a próxima palavra oferecendo resultados rápidos e diversas aplicações práticas em várias áreas
Aplicações
Diferentemente de uma ferramenta de busca como o Google, o ChatGPT não recupera informações, mas cria frases e textos completos em tempo real com base no processamento de um imenso volume de dados, veja alguns exemplos de uso para diferentes tarefas:
✍️ Escrita:
- Colaboração em brainstorming, sugerindo nomes;
- Elaboração de templates para comunicados e e-mails;
- Tradução automática.
📖 Leitura:
- Revisão de textos;
- Sumarização de artigos extensos;
- Análise de sentimentos, possibilitando a criação de dashboards para acompnhamento ao longo do tempo.
💬 Conversa:
- Diálogos e aconselhamentos;
- Coaching de carreira;
- Planejamento de viagens; Sugestões de receitas;
- Conversação interativa com documentos PDF;
- Atendimento ao cliente;
- Realização de pedidos.
O que faremos aqui?
Nosso objetivo aqui é realizar uma análise de sentimentos para classificar sentenças como positivas ou negativas utilizando algum LLM pré-treinado. Embora a OpenAI já tenha sido uma organização sem fins lucrativos que lançava seus projetos como código aberto, desde o lançamento do ChatGPT ela se tornou uma empresa que mantém a propriedade de seus códigos fonte. Isso significa que apesar da facilidade de criar aplicações, modelos mais poderosos e relativamente baratos, desenvolvedores de IA não podem modificar o GPT-3 para atender às nossa necessidades específicas ou incorporá-lo em seus próprios projetos de maneira livre e gratuita. Portanto teremos de recorrer à alternativas não tão(*) open source como o Llama 2 da Meta que permite total controle sobre o modelo, rodar em nosso próprio computador/servidor e nós dá o controle sobre a privacidade dos nossos dados.
(*) “Código aberto” 🤔 Não é totalmente código aberto pois por mais que a Meta tenha disponibilizado o modelo treinado para uso livre, ele não compartilha os dados de treinamento do modelo ou o código usado para treiná-lo.
Mãos a obra!
Iniciar ambiente de trabalho
Primeiramente vamos carregar todas as dependencias necessárias para executar os códigos a seguir:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from PIL import Image
from nltk.corpus import stopwords
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
from llama_cpp import Llama
from tqdm.notebook import tqdm
tqdm.pandas()Carregar dados
Utilizaremos uma versão traduzida do dataset IMdb para o português, um conjunto de dados do Internet Movie Database (IMDB), que é uma das maiores e mais abrangentes bases de dados online sobre filmes e programas de televisão.
#Importar todo conjunto de dados
df = pd.read_csv('input/imdb-reviews-pt-br.csv', index_col='id')
# Obter amostra de tamanho 100
_, df = train_test_split(df, test_size=100, random_state=42, shuffle=True)Informações gerais
Esse dataset inclui avaliações e críticas de filmes feitas por usuários do IMDB, bem como informações sobre os próprios filmes, como título, ano de lançamento, gênero, etc. Para nossa finalidade para tarefa de análise de sentimentos, utilizaremos os seguintes dados:
| id | text_en | text_pt | sentiment |
|---|---|---|---|
| 12534 | This was unusual: a modern-day film which… | Isso era incomum: um filme moderno que era… | pos |
| 35447 | Some of my old friends suggested me to wat… | Alguns dos meus velhos amigos sugeriram qu… | neg |
| 20281 | What a pleasure. This is really a parody. … | Que prazer. Isto é realmente uma paródia. S… | pos |
| … | … | … | … |
| 34241 | WOW!I just was given this film from a frie… | WOW! Acabei de receber este filme de um am… | neg |
| 12896 | This film offers many delights and surprise… | Este filme oferece muitas delícias e surp… | pos |
| 19748 | Over the years Ive watched this movie many… | Ao longo dos anos, assisti a esse filme mu… | pos |
Onde:
id: Identificador;text_en: texto em inglês;text_pt: texto em português;sentiment: rótulo do texto, que pode serposouneg.
Análise Exploratória
Distribuição dos sentimentos na amostra
Primeiro vamos entender como ficou distribuída a proporção dos sentimentos na amostra coletada:
Clique aqui para ver o código do gráfico
# Contagem absoluta
contagem_absoluta = df['sentiment'].value_counts()
# Contagem relativa
contagem_relativa = df['sentiment'].value_counts(normalize=True) * 100
# Criar gráfico de barras
fig, ax = plt.subplots(figsize=(6, 4))
barras = plt.bar(contagem_absoluta.index, contagem_absoluta, color=['green', 'red'])
# Adicionar texto nas barras
for barra, abs_value, rel_value in zip(barras, contagem_absoluta, contagem_relativa):
yval = barra.get_height()
ax.text(barra.get_x() + barra.get_width()/2, yval, f'{abs_value} ({rel_value:.1f}%)',
ha='center', va='bottom', color='black', fontsize=12)
# Adicionar rótulos e título
plt.xlabel('Sentimento', fontsize=14)
plt.ylabel('Frequência absoluta', fontsize=14)
plt.title('Quantidade de textos de cada sentimento \nem uma amostra de tamanho 100', fontsize=16, x=0.5, y=1.1)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# Remover bordas da parte superior e direita
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# Ajustar layout
plt.tight_layout()
# Salvar imagem
plt.savefig(f"img/freq_sentiment.png", bbox_inches='tight')
# Exibir o gráfico
plt.show()
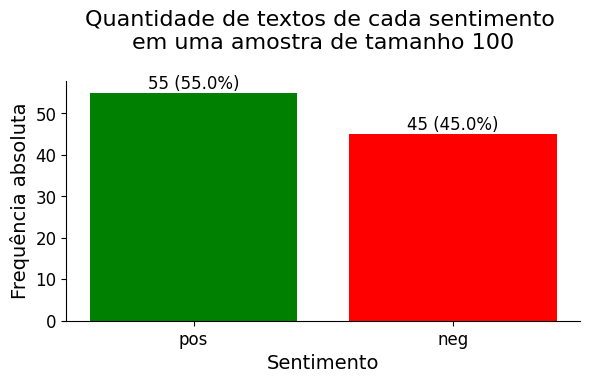
📌 Interpretação: Coletei uma amostra aleatória simples de tamanho n=100 de todas as reviews que contém aproximadamente metade de cada sentimento para diminuir o tempo computacional de execução no meu computador.
Palavras mais frequentes para cada sentimento
Núvens de palavras das resenhas dos filmes que foram anotadas como positivos e como negativos nas duas linguas disponíveis no dataset:
Clique aqui para ver o código das Wordclouds
def generate_wordcloud(df, language='en'):
# Definir stopwords para o idioma escolhido
if language == 'en':
stop_words_pos = stop_words_neg = set(stopwords.words('english'))
stop_words_pos.update(["film", "movie", "one"])
stop_words_neg.update(["character", "like", "really", "make", "see"])
elif language == 'pt':
stop_words_pos = stop_words_neg = set(stopwords.words('portuguese'))
stop_words_pos.update(["filme", "filmes", "todo", "tão", "pode", "todos"])
stop_words_neg.update(["filme", "filmes", "todo", "tão", "filme", "coisa", "realmente"])
else:
raise ValueError("Language must be 'en' or 'pt'.")
# Concatenar textos positivos e negativos
txt_pos = " ".join(review for review in df[df.sentiment == 'pos'][f'text_{language}'])
txt_neg = " ".join(review for review in df[df.sentiment == 'neg'][f'text_{language}'])
# Carregar máscaras de imagem
mask_pos = np.array(Image.open(f"img/pos.png"))
mask_neg = np.array(Image.open(f"img/neg.png"))
# Gerar nuvens de palavras positivas e negativas
wordcloud_positivo = WordCloud(
stopwords=stop_words_pos,
random_state=42,
background_color="white",
color_func=lambda *args, **kwargs: "green",
contour_color='black',
contour_width=1,
max_font_size=100,
min_font_size=15,
max_words=200,
mask=mask_pos
).generate(txt_pos)
wordcloud_negativo = WordCloud(
stopwords=stop_words_neg,
random_state=42,
background_color="white",
color_func=lambda *args, **kwargs: "red",
contour_color='black',
contour_width=1,
max_font_size=100,
min_font_size=15,
max_words=200,
mask=mask_neg
).generate(txt_neg)
# Configurações do plot
plt.figure(figsize=(7, 14))
# Plotar nuvem de palavras positivas
plt.subplot(1, 2, 1)
plt.imshow(wordcloud_positivo, interpolation='bilinear')
plt.axis('off')
plt.title('Positivo', fontsize=20, color='green')
# Plotar nuvem de palavras negativas
plt.subplot(1, 2, 2)
plt.imshow(wordcloud_negativo, interpolation='bilinear')
plt.axis('off')
plt.title('Negativo', fontsize=20, color='red')
# Ajustar layout
plt.tight_layout()
# Salvar a nuvem de palavras como imagem
plt.savefig(f"img/wordcloud_{language}.png", bbox_inches='tight')
# Exibir a nuvem de palavras
plt.show()
# Exemplo de uso para o idioma inglês
generate_wordcloud(df, language='en')
# Exemplo de uso para o idioma português
generate_wordcloud(df, language='pt')
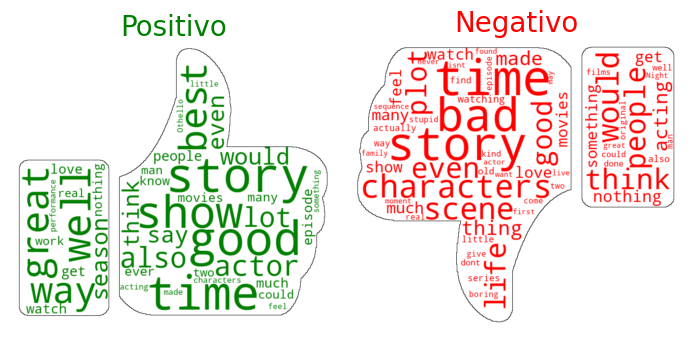
Núvem de palavras mais frequentes das resenhas em 🇺🇲 Inglês

Núvem de palavras mais frequentes das resenhas em 🇧🇷 Português
📌 Interpretação: Como esperado, mesmo com a mudança na língua, a frequência das palavras é exibida de maneira muito similar de acordo com cada sentimento.
Análise de Sentimentos
Família Llama 2 de Large Language Models (LLMs)
Nesta seção, exploraremos o Llama 2, um modelo de código aberto, e discutiremos as vantagens e desvantagens em relação aos LLMs de código fechado ou remotos.
Tamanho do modelo
Para saber qual modelo utilizar, primeiramente precisamos ter em mente algumas noções sobre a quantidade de parâmetros e tamanhos dos LLM. No geral:
1 Bilhão:
Bons em correspondência de padrões e algum conhecimento básico do mundo (como por exemplo classificar avaliações por sentimento)
10 Bilhões:
Maior conhecimento mundial, conhecem mais fatos esotéricos sobre o mundo e melhoram em seguir instruções básicas (bom para chatbot para pedidos de comida);
100+ Bilhões:
Muito grandes, com conhecimento mundial muito rico, saberão coisas sobre física, filosofia, ciência e assim por diante e serão melhores em raciocínios complexos (tarefas que envolvem conhecimento profundo ou raciocínio complexo, parceiro para brainstorming)
Para uma análise de sentimentos simples, não é necessário um modelo com 100 bilhões de parâmetros. Modelos menores, como os com 7 bilhões de parâmetros, podem ser suficientes e menos computacionalmente exigentes.
Código aberto ou fechado
Embora próximos, os LLMs de código aberto ainda não conseguem igualar o poder e a precisão dos aplicativos de código fechado disponíveis comercialmente, como GPT-4 e Bard (Gemini). Mesmo sendo menos poderosos, existem alguns prós e contras pelos quais podemos pesar na hora de escolher a melhor opção:
Open Source
- Total controle sobre o modelo
- Pode rodar em nosso próprio computador/servidor
- Controle sobre a privacidade dos dados
Closed
- Fácil de criar aplicações
- Maiores e mais poderosos
- Relativamente barato
- Existe um certo risco de depender do fornecedor
Utilizaremos a abordagem de código aberto por ser mais prática para fins de estudos, pois além de gratuita, não exige internet, registros ou chaves de API.
Uso remoto ou local
Podemos interagir com o modelo de linguagem grande (LLM) do Llama 2 via API da Hugging Face, seguindo as instruções do repositório oficial da Meta ou podemos baixar os arquivos do modelo em formato GGML para o Llama 2 7B Chat do Meta Llama 2. Os formatos GGML são utilizados para inferência de CPU + GPU usando o principamente o pacote llama-cpp-python.
Para mais informações sobre como configurar o modelo consulte este link
def load_llama_model(model_path="./input/llama-2-7b-chat.ggmlv3.q2_K.bin", language='en', seed=42):
# Determinar o tamanho da janela de contexto com base no idioma
if language == 'en':
context_window = df.text_en.map(len).max()
elif language == 'pt':
context_window = df.text_pt.map(len).max()
else:
raise ValueError("Language must be 'en' or 'pt'.")
# Carregar o modelo Llama
return Llama(model_path=model_path,
verbose=False,
n_ctx=context_window,
seed=seed)Para obter os melhores resultados, devemos ser o mais claro e específicos possível nas interações. Porém devemos iniciar com um prompt simples e rápido para ir direcionando o modelo na direção desejada e avaliando os resultados obtidos e ajustando gradualmente o prompt para refinar e aprimorar a resposta desejada
def classify_sentiment_llama(text, llama_model):
# Construir a prompt para o modelo Llama
prompt = f''' \
Q: Answer with just one word, \
does the following text express a \
positive or negative feeling? \
{text} \
A:'''
# Obter a saída do modelo Llama
output = llama_model(prompt, max_tokens=3)
return output["choices"][0]["text"]Com nosso prompt definido, já podemos carregar o modelo:
# Carregar o modelo Llama para o idioma desejado
llama_model = load_llama_model(language='en')## llama.cpp: loading model from ./llama-2-7b-chat.ggmlv3.q2_K.bin
## llama_model_load_internal: format = ggjt v3 (latest)
## llama_model_load_internal: n_vocab = 32000
## llama_model_load_internal: n_ctx = 4320
## llama_model_load_internal: n_embd = 4096
## llama_model_load_internal: n_mult = 256
## llama_model_load_internal: n_head = 32
## llama_model_load_internal: n_head_kv = 32
## llama_model_load_internal: n_layer = 32
## llama_model_load_internal: n_rot = 128
## llama_model_load_internal: n_gqa = 1
## llama_model_load_internal: rnorm_eps = 5.0e-06
## llama_model_load_internal: n_ff = 11008
## llama_model_load_internal: freq_base = 10000.0
## llama_model_load_internal: freq_scale = 1
## llama_model_load_internal: ftype = 10 (mostly Q2_K)
## llama_model_load_internal: model size = 7B
## llama_model_load_internal: ggml ctx size = 0.08 MB
## llama_model_load_internal: mem required = 2733.66 MB (+ 2160.00 MB per state)
## llama_new_context_with_model: kv self size = 2160.00 MB
## llama_new_context_with_model: compute buffer total size = 295.35 MBApós instanciar o modelo, basta aplicá-lo em nossa base de dados. (apliquei o mesmo modelo tanto para as reviews e português quanto em inglês).
df['sentiment_llm_en'] = df.text_en.progress_apply(lambda x: classify_sentiment_llama(x, llama_model))
Como este modelo é o mais básico e não alteramos nenhum parâmetro (como por exemplo temperature, que determina se o output será mais aleatório ou mais previsível) pode ser que a saída não saia padronizada e necessite de algum pós-processamento. Vejamos como foram os outputs do LLM:
Clique aqui para ver o código do gráfico
# Contagem da frequência das classificações
sentiment_llm_counts = df.groupby('sentiment').sentiment_llm_en.value_counts().reset_index(name='n')
# Organizar as categorias pela frequência total
order = df.sentiment_llm_en.value_counts().reset_index(name='n')
order = order.sort_values(by='n', ascending=False)['index']
# Configurações de estilo do seaborn
sns.set(style="whitegrid")
# Criar o gráfico de barras
plt.figure(figsize=(12, 4))
ax = sns.barplot(x=sentiment_llm_counts.sentiment_llm_en, y=sentiment_llm_counts.n, hue=sentiment_llm_counts.sentiment, order=order, palette=["red", "green"])
# Adicionar rótulos e título
plt.ylim([0, 25])
plt.xticks(fontsize=12, rotation=90)
plt.yticks(fontsize=12)
ax.set_xlabel('Anotação de sentimento das resenhas', fontsize=14)
ax.set_ylabel('Frequência', fontsize=14)
ax.set_title('Frequência dos sentimentos classificados pelo LLM em Inglês\nem relação aos sentimentos já anotados da base', fontsize=20)
# Adicionar anotações nas barras
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='baseline', fontsize=10, color='black', xytext=(0, 5),
textcoords='offset points')
plt.legend(loc="upper right", title = "Label real")
# Remover bordas da parte superior e direita
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.grid(False)
# Salvar a nuvem de palavras como imagem
plt.savefig(f"img/freq_class_llm_en.png", bbox_inches='tight')
# Exibir o gráfico
plt.show()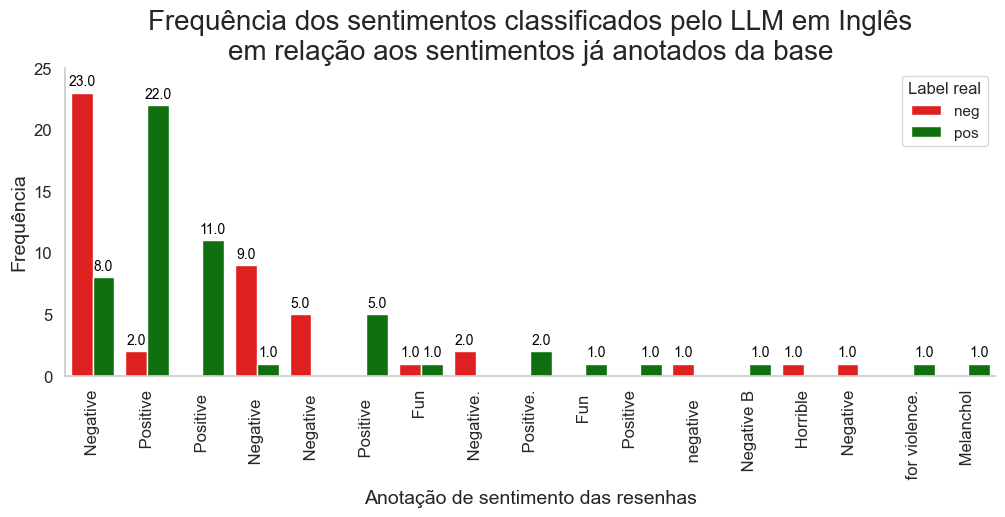
📌 Interpretação:
É possível observar que o modelo pré-treinado conseguiu reconhecer de maneira bastante coerente o sentimento dos trechos para as categorias pos e neg, porém, não vieram padronizadas exatamente como solicitamos ao modelo.
Como a saída não foi padronizada, vamos realizar algum pós-processamento para padronizar as classes como pos ou neg para possibilitar avaliar o desempenho do modelo com base em métricas de classificação.
conditions = [
(df.sentiment_llm_en.str.contains('(?i)(?:pos|fun)')),
(df.sentiment_llm_en.str.contains('(?i)(?:neg|horrible|melanchol)'))
]
pd.crosstab(df.sentiment, np.select(conditions, ['pos', 'neg'], default='other'))Com os outputs padronizados em duas classes, podemos verificar como foi a acurácia do modelo.
Desempenho
Como estamos diante de um problema de classificação, avaliaremos o desempenho do modelo com matrizes de confusão para entender a as taxas de acerto e calcular a acurácia pois o dataset é balanceado.
Clique aqui para ver o código do gráfico
# Matrizes de Confusão
conditions = [
(df.sentiment_llm_en.str.contains('(?i)(?:pos|fun|good|comedy)')),
(df.sentiment_llm_en.str.contains('(?i)(?:neg|melanchol|absurd|horrible)'))
]
cm_llm_en = confusion_matrix(df.sentiment, np.select(conditions, ['pos', 'neg'], default='other'))
accuracy_llm_en = accuracy_score(df.sentiment, np.select(conditions, ['pos', 'neg'], default='other'))
conditions = [
(df.sentiment_llm_pt.str.contains('(?i)(?:pos)')),
(df.sentiment_llm_pt.str.contains('(?i)(?:neg|horrível)'))
]
cm_llm_pt = confusion_matrix(df.sentiment, np.select(conditions, ['pos', 'neg'], default='other'))
accuracy_llm_pt = accuracy_score(df.sentiment, np.select(conditions, ['pos', 'neg'], default='other'))
# Configurações de estilo do seaborn
sns.set(font_scale=1.2)
plt.figure(figsize=(12, 5))
# Plotar Matriz de Confusão para o modelo de LLM em inglês
plt.subplot(1, 2, 1)
sns.heatmap(cm_llm_en, annot=True, fmt='d', cmap='binary', cbar=False, vmin=0, vmax=50,
xticklabels=['Negativo', 'Neutro', 'Positivo'], yticklabels=['Negativo', 'Neutro', 'Positivo'])
plt.title(f'Matriz de Confusão (Vader - Inglês)\nAcurácia: {accuracy_llm_en:.0%}', fontsize=22)
plt.xlabel('Previsto', fontsize=14)
plt.ylabel('Real', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# Plotar Matriz de Confusão para o modelo de LLM em português
plt.subplot(1, 2, 2)
sns.heatmap(cm_llm_pt, annot=True, fmt='d', cmap='binary', cbar=False,vmin=0, vmax=50,
xticklabels=['Negativo', 'Neutro', 'Positivo'], yticklabels=['Negativo', 'Neutro', 'Positivo'])
plt.title(f'Matriz de Confusão (Vader - Português)\nAcurácia: {accuracy_llm_pt:.0%}', fontsize=22)
plt.xlabel('Previsto', fontsize=14)
plt.ylabel('Real', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# Ajustar layout
plt.tight_layout()
# Salvar a nuvem de palavras como imagem
plt.savefig(f"img/cm_llm.png", bbox_inches='tight')
# Exibir o gráfico
plt.show()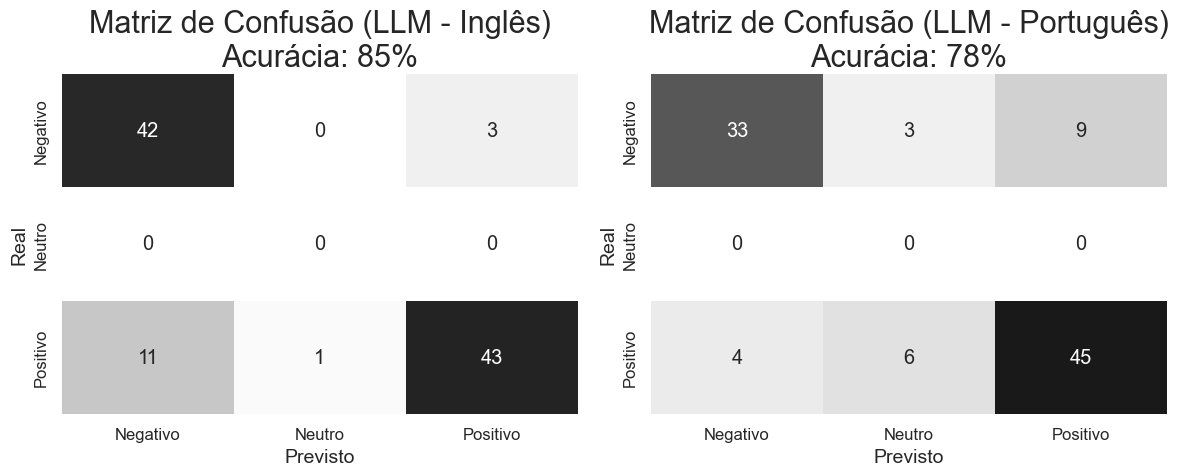
📌 Interpretação: A acurácia geral para a língua Inglesa foi superior quando aplicado o mesmo modelo para a língua portuguesa. Vale lembrar que este modelo foi treinado em Inglês e estamos utilizado a menor das opções.
O desempenho deste modelo é muito interessante, principalmente por já ser pré treinado, não sendo necessário gastar tanto tempo na sua construção mas para afirmar que este modelo é bom precisamos entender qual seria o resultado para resolver este problemas se utilizassemos a abordagem mais simples possível.
Vader
O VADER (Valence Aware Dictionary and sEntiment Reasoner) é uma abordagem mais simples e rápida em comparação aos LLMs. Não requer o treinamento de um modelo, mas depende de léxicos de palavras relacionadas a sentimentos. Pode ser facilmente utilizado via bibliotecas de código aberto em Python, como vaderSentiment para inglês e LeIA (Léxico para Inferência Adaptada) para português.
A abordagem é direta: no léxico (uma coleção de palavras), cada palavra já possui uma nota atribuída. Ao passar um documento (frase), retorna um dicionário com o escore de polaridade com base no escore das palavras no texto. O dicionário inclui o valor do sentimento geral normalizado (compound), variando de -1 (extremamente negativo) a +1 (extremamente positivo). Esse valor pode ser usado para descrever o sentimento predominante no texto, considerando os seguintes limites:
- Sentimento positivo:
compound>= 0.05 - Sentimento negativo:
compound<= -0.05 - Sentimento neutro: (
compound> -0.05) e (compound< 0.05)
Clique aqui para ver a função utilizada para classificar o sentimento com base no escore compound
# Função para classificar o sentimento com base no compound score
def classify_sentiment_vader(text, language='en'):
# Definir método que será utilizado
if language=='en':
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
elif language == 'pt':
from leia import SentimentIntensityAnalyzer
else:
raise ValueError("Language must be 'en' or 'pt'.")
# Instanciar a ferramenta para análise de sentimentos
analyzer = SentimentIntensityAnalyzer()
# Realiza a análise de sentimentos e obtém o compound score
compound_score = analyzer.polarity_scores(text)['compound']
# Classifica o sentimento com base no compound score
if compound_score >= 0.05:
return 'pos'
elif compound_score <= -0.05:
return 'neg'
else:
return 'neu'
# Criando uma nova coluna 'sentimento_vader'
df['sentiment_vader_en'] = df.text_en.apply(lambda x: classify_sentiment_vader(x, 'en'))
df['sentiment_vader_pt'] = df.text_pt.apply(lambda x: classify_sentiment_vader(x, 'pt'))A execução do código é bem rápida, sendo útil para referência como baseline ou em casos em que temos baixo recurso computacional e um grande volume de dados para classificar.
Desempenho
Como estamos diante de um problema de classificação, avaliaremos o desempenho do modelo com matrizes de confusão para entender a as taxas de acerto e calcular a acurácia pois o dataset é balanceado.
Clique aqui para ver o código do gráfico
# Matrizes de Confusão
cm_vader_en = confusion_matrix(df.sentiment, df.sentiment_vader_en)
cm_vader_pt = confusion_matrix(df.sentiment, df.sentiment_vader_pt)
# Acurácias
accuracy_vader_en = accuracy_score(df.sentiment, df.sentiment_vader_en)
accuracy_vader_pt = accuracy_score(df.sentiment, df.sentiment_vader_pt)
# Configurações de estilo do seaborn
sns.set(font_scale=1.2)
plt.figure(figsize=(12, 5))
# Plotar Matriz de Confusão para o método Vader em inglês
plt.subplot(1, 2, 1)
sns.heatmap(cm_vader_en, annot=True, fmt='d', cmap='binary', cbar=False,vmin=0, vmax=50,
xticklabels=['Negativo', 'Neutro', 'Positivo'], yticklabels=['Negativo', 'Neutro', 'Positivo'])
plt.title(f'Matriz de Confusão (Vader - Inglês)\nAcurácia: {accuracy_vader_en:.0%}', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.xlabel('Previsto', fontsize=14)
plt.ylabel('Real', fontsize=14)
# Plotar Matriz de Confusão para o método Vader em português
plt.subplot(1, 2, 2)
sns.heatmap(cm_vader_pt, annot=True, fmt='d', cmap='binary', cbar=False,vmin=0, vmax=50,
xticklabels=['Negativo', 'Neutro', 'Positivo'], yticklabels=['Negativo', 'Neutro', 'Positivo'])
plt.title(f'Matriz de Confusão (Vader - Português)\nAcurácia: {accuracy_vader_pt:.0%}', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.xlabel('Previsto', fontsize=14)
plt.ylabel('Real', fontsize=14)
# Ajustar layout
plt.tight_layout()
# Salvar a nuvem de palavras como imagem
plt.savefig(f"img/cm_vader.png", bbox_inches='tight')
# Exibir o gráfico
plt.show()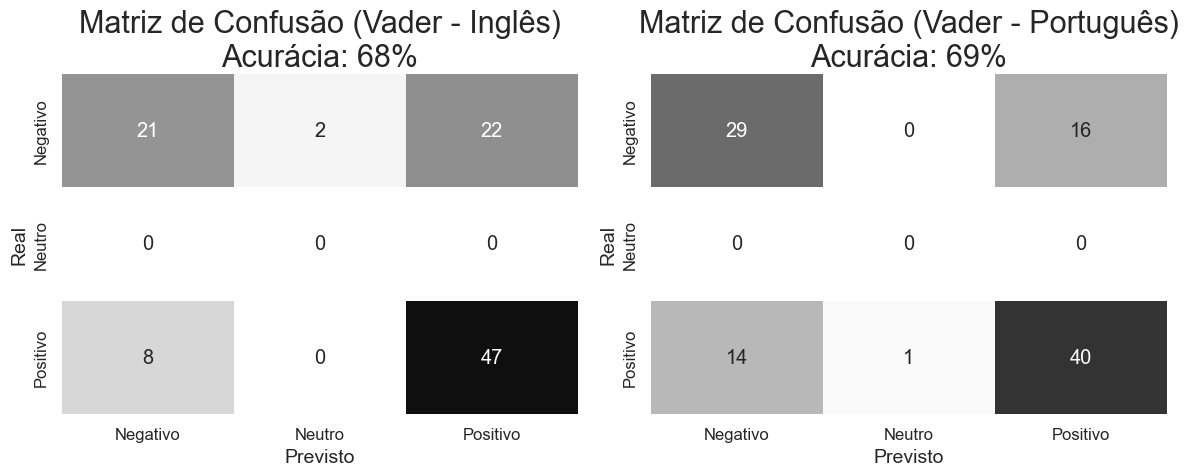
📌 Interpretação: A acurácia geral do método foi praticamente o mesmo para ambas as linguas. Na lingua inglesa observamos mais casos de falsos positivos (22%), já na lingua portuguesa observamos mais casos de falsos negativos (14%).
Essa abordagem é boa para ser utilizada como baseline pois quase todas as abordagens tradicionais de Machine Learning para a tarefa de análise de sentimentos necessitam de tempo para desenvolvimento, treino, validação e sustentação de modelos.
Resultado Final
Avaliamos o desempenho de ambas as abordagens para determinar se o uso do LLM justificou-se em comparação com a abordagem mais simples para a execução da tarefa de análise de sentimentos.
Clique aqui para ver o código do gráfico
models = (
"Inglês",
"Português",
)
weight_counts = {
"Vader": np.array([accuracy_vader_en,
accuracy_vader_pt]),
"LLM": np.array([accuracy_llm_en-accuracy_vader_en,
accuracy_llm_pt-accuracy_vader_pt]),
}
fig, ax = plt.subplots()
bottom = np.zeros(2)
colors=["#b4dbe6", "#024b7a"]
for (boolean, weight_count), col in zip(weight_counts.items(), colors):
p = ax.bar(models, weight_count, width=0.5, label=boolean, bottom=bottom, color=col)
bottom += weight_count
# Formatar eixos
plt.ylim([0, 1.1])
plt.xlabel('Idioma das resenhas dos filmes', fontsize=14)
plt.ylabel('Ganho de Acurácia', fontsize=14)
plt.title("Comparação do ganho de acurácia \ndo LLM em relação ao Vader", fontsize=16, x=0.5)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
# Legenda
ax.legend(loc="upper right", title='Método utilizado')
#specify order of items in legend
handles, labels = plt.gca().get_legend_handles_labels()
order = [1, 0]
plt.legend([handles[idx] for idx in order],[labels[idx] for idx in order])
accs=[x*100 for x in [accuracy_vader_en, accuracy_vader_pt, accuracy_llm_en, accuracy_llm_pt]]
for p, acc in zip(ax.patches, accs):
width, height = p.get_width(), p.get_height()
x, y = p.get_xy()
ax.text(x+width/2,
y+(height/2) - 0.01,
'{:.0f} %'.format(acc),
horizontalalignment='center',
verticalalignment='center',
color='white', fontsize=18)
# Adicionar setas e textos na figura
plt.arrow(0.3, 0.62, 0, 0.16,
head_width = 0.05,
width = 0.015,
color='black')
plt.text(0.2, 0.9, '+20,0%', fontsize = 20)
plt.arrow(0.7, 0.63, 0, 0.09,
head_width = 0.05,
width = 0.015,
color='black')
plt.text(0.6, 0.84, '+11,53%', fontsize = 20)
# Remover bordas da parte superior e direita
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(True)
ax.spines['left'].set_visible(True)
ax.grid(visible=None)
ax.set_facecolor('white')
# Ajustar layout
plt.tight_layout()
# Salvar a nuvem de palavras como imagem
plt.savefig(f"img/acc_comparation.png", bbox_inches='tight')
# Exibir o gráfico
plt.show()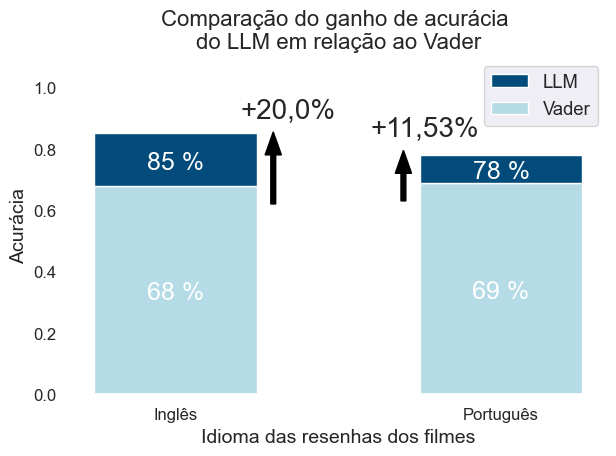
📌 Interpretação: A acurácia geral foi consideravelmente maior para o modelo Llama2 em ambas as línguas, mesmo sendo treinado principalmente em dados da língua inglesa.
Conclusão e Discussão
Os avanços tecnológicos na área são verdadeiramente impressionantes e evidenciam a rápida evolução da inteligência artificial. É importante estarmos sempre atentos a essas mudanças, pois a área de LLMs está em constante crescimento e melhorias significativas são desenvolvidas diariamente.
Em meio a tantos avanços, também é importante reconhecer as limitações desses modelos. Um dos desafios é o corte de conhecimento (knowledge cutoffs), o que significa que o modelo é treinado até uma determinada data, como 2022, portanto não possui conhecimento sobre eventos ou desenvolvimentos que ocorreram após essa data. Além disso, os LLMs estão sujeitos a “hallucinations”, ou seja, podem inventar informações em um tom muito confiante, o que pode levar a resultados imprecisos ou até mesmo prejudiciais.
Outras limitações incluem restrições no input e output dos modelos, o que pode tornar difícil lidar com grandes volumes de dados ou fornecer resultados completos de uma só vez. Além disso, os LLMs geralmente não funcionam bem com dados estruturados, como tabelas, e podem reproduzir vieses e toxicidade presentes na sociedade, o que levanta preocupações éticas e sociais importantes.
Portanto, enquanto exploramos esse vasto campo das redes neurais, é essencial abordar essas limitações e desenvolver soluções que permitam o uso ético e responsável dessas poderosas ferramentas de IA.


Share this post
Twitter
LinkedIn
Email