
































Com que frequência ocorrem acidentes na ponte Rio-Niterói?
Com os dados públicos da PRF e um pouco de Estatística buscaremos respostas para esta e outras perguntas relacionadas ao número de acidentes na Ponte Rio-Niterói.

Perguntas
Estudar em outra cidade têm suas vantagens e desvantagens, durante toda a graduação atravessei Baía de Guanabara pela Ponte Presidente Costa e Silva, (popularmente conhecida como Ponte Rio–Niterói) assim como todas as pessoas que fazem esse trajeto diariamente e diante de tanta beleza natural com a vista panorâmica da Baía como os espetáculos proporcionados pelo pôr do sol, os pássaros ou a beleza inegável do Pão de Açúcar também é notável a beleza fruto da maior habilidade humana: a criatividade. Temos o cristo, todos aqueles grandes barcos, o Porto do Rio de Janeiro com todas aquelas obras de Engenharia, ou até mesmo a própria Ponte, que por si só já é intrigante.
Em contrapartida, dentre as desvantagens está a enorme frequência de engarrafamentos, o custo, o tempo gasto no trajeto e ao refletir sobre a velocidade dos carros na travessia da Ponte e a quantidade de acidentes que ocorrem na me deparei com os seguinte questionamentos:
O número de acidentes na ponte é diário?
O número de acidentes na ponte têm diminuído?
A instalação das câmeras de segurança diminuiu o número de acidentes?
Em janeiro de 2018 anunciava-se no jornal: “radares da Ponte Rio-Niterói começam a multar” e como já faz algum tempo que a ponte é monitorada com câmeras de segurança surge a suspeita se o número de acidentes têm diminuído e na vontade de tirar minhas próprias conclusões recorri ao que há de mais abundante por ai: os dados e com o uso de técnicas simples de Estatística iniciei minha “investigação” para obter possíveis respostas para essas perguntas.
Pacotes utilizados nesta análise:
library(grid) # textGrob()
library(dplyr) # Manipulacao dos dados
library(purrr) # Programacao Funcional
library(stringr) # Manipulacao de strings
library(magrittr) # Pipes
library(leaflet) # Mapa interativo
library(leaflet.extras) # + leaflet
library(ggplot2) # graficos elegantes
library(lubridate) # manipulacao de data
library(data.table) # fred()
library(forecast) # tslm()
library(ggfortify) # autoplot()
library(gridExtra) # + ggplot2
library(zoo) # rollmean
library(broom) # tidy() augment() glance()
library(knitr) # kable()
library(kableExtra) # scroll_box
library(formattable) # color_bar()Fonte dos dados
Os dados para realizar esta pesquisa foram obtidos no site da Polícia Rodoviária Federal, que disponibiliza uma sessão de Dados Abertos que segundo o site: “não possui restrição de licenças, patentes ou mecanismos de controle, de modo a estarem livremente disponíveis para serem utilizados e redistribuídos à vontade”. Na sessão de Acidentes é possível encontrar os registros de acidentes no formato csv ao longo dos anos.
Discussão: Para saber se de fato o número de acidentes na ponte Rio-Niterói ocorre diariamente seria necessário que todos os casos fossem registrados ou elaborar alguma forma de fazer inferência para obter significância estatística para esta resposta baseado na amostra de ocorrências registradas. Ainda é possível que ocorram subnotificações pois pode ser que alguns casos como uma leve batida entre dois carros não tenham sido registrados pela PRF.
Reflexão: Uma sugestão para contornar esse problema de subnotifação (caso de fato exista) poderia ser o desenvolvimento de um algorítimo de Inteligência Artificial baseado em Deep Learning para captar através das imagens das câmeras de segurança a ocorrência dos acidentes, classifica-los e armazenar em uma base de dados de forma automatizada além de notificar às autoridades..
Dada as circunstâncias, vejamos o que os dados disponibilizados pela PRF têm à revelar. Após baixar todos os dados, bastou fazer a leitura com os comandos:
# Importar / Arrumar / Limpar
base <-
paste0("datatran",2008:2018,"/","datatran",2008:2018,".csv") %>%
map(~.x %>%
fread(sep = ";",dec=",")%>%
mutate(km = as.character(km),
br = as.character(br)) %>%
mutate_if(is.character,
~.x %>%
enc2native() %>%
abjutils::rm_accent() %>%
tolower() %>%
str_replace_all("/","-") %>%
str_replace_all(",","\\.")
) %>%
mutate(data_inversa = if_else(is.na(dmy(data_inversa)),
ymd(data_inversa),
dmy(data_inversa)) ,
km = as.numeric(km),
br = as.numeric(br),
id = as.character(id),
dia_semana = str_remove_all(dia_semana,"-feira")
) %>%
filter(br==101 & km>=321 & km<334) %>%
.[str_detect(.$municipio,"(niteroi|rio de janeiro)"),]
)
# Salvar base arrumada:
saveRDS(base, 'base.RDS')Nota: A única pasta que tinha a base com nome diferente das demais foi no ano de 2016, do qual foi preciso renomear o arquivo datatran2016_atual.csv para datatran2016.csv.
Diante de tantos dados, foi necessário fazer um filtro para obter apenas os dados da ponte Rio- Niterói.
Segundo o Google, o “endereço” da ponte é BR-101, Km 321-334, portanto foi aplicado um filtro que levasse em conta essa informação.
Análises preliminares
Com a base de dados arrumada e salva em no objeto base.RDS fica mais fácil fazer análises rápidas depois de reiniciar o R e a leitura dos dados também será mais veloz.
base <- readRDS("base.RDS")Primeiramente, um breve resumo dos dados com algumas informações gerais dos últimos 10 anos:
base %>%
map_df( ~.x %>%
select(dia_semana,classificacao_acidente, mortos, feridos, veiculos)) %>%
map_if(is.character,as.factor) %>%
bind_cols() %>%
SmartEDA::ExpCatViz(target=NULL, fname=NULL, margin=2, Page = c(2,2)) ## $`0`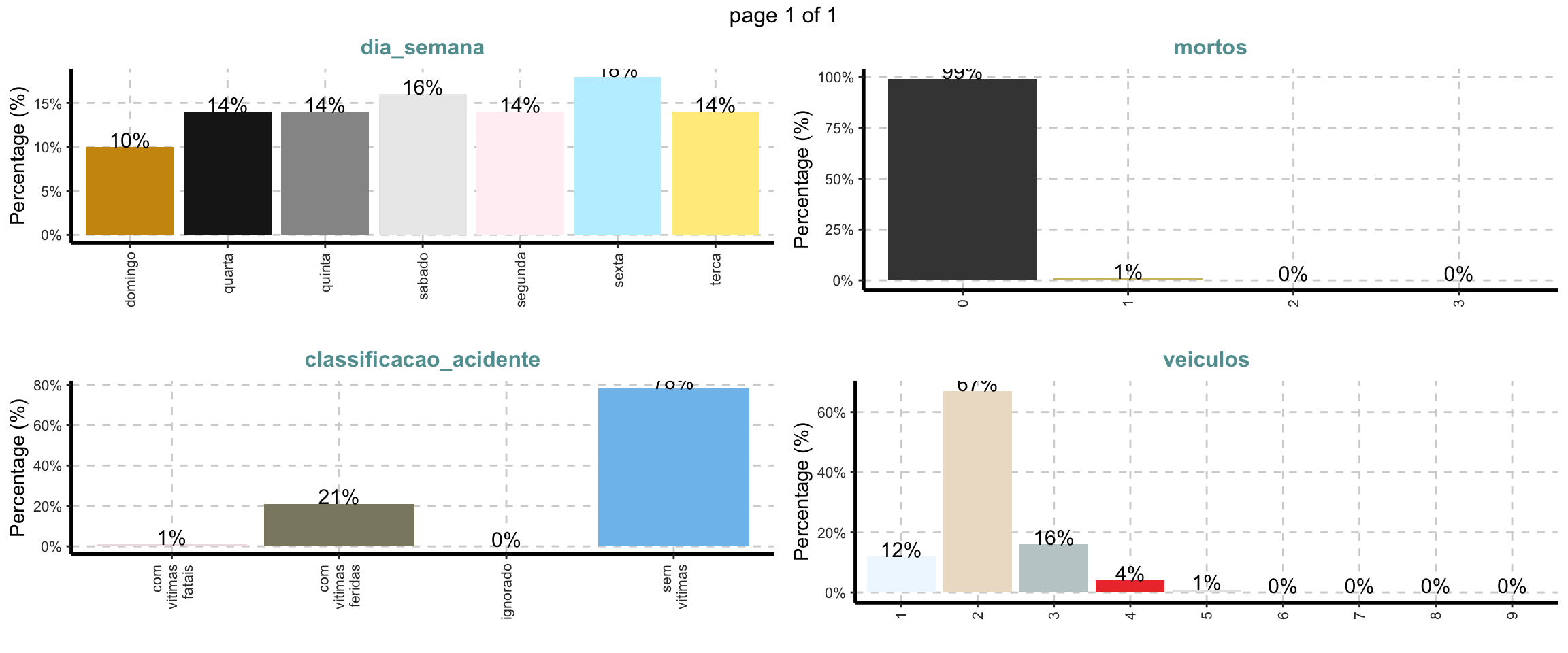
Nota-se que o maior número de acidentes ocorre na sexta-feira, praticamente todos os acidentes não tiveram mortos e em 78% dos acidentes não houveram vítimas. A maioria dos acidentes foi colisão entre dois carros.
Os tipos de acidentes que ocorreram foram:
base %>%
map_df( ~.x %>%
select(causa_acidente,
tipo_acidente)) %>%
map_if(is.character,as.factor) %>%
as_tibble %>%
group_by(causa_acidente) %>%
dplyr::summarise(n=n()) %>%
mutate(n = color_bar("lightgrey")(n)) %>%
kable(escape = F) %>%
kable_styling("hover",full_width = F) %>%
scroll_box( height = "200px")| causa_acidente | n |
|---|---|
| agressao externa | 1 |
| animais na pista | 4 |
| avarias e-ou desgaste excessivo no pneu | 5 |
| condutor dormindo | 4 |
| defeito mecanico em veiculo | 210 |
| defeito mecanico no veiculo | 26 |
| defeito na via | 9 |
| desobediencia a sinalizacao | 48 |
| desobediencia as normas de transito pelo condutor | 9 |
| dormindo | 58 |
| falta de atencao | 1697 |
| falta de atencao a conducao | 146 |
| falta de atencao do pedestre | 4 |
| ingestao de alcool | 59 |
| ingestao de alcool | 5 |
| mal subito | 4 |
| nao guardar distancia de seguranca | 677 |
| nao guardar distancia de seguranca | 39 |
| objeto estatico sobre o leito carrocavel | 3 |
| outras | 5118 |
| pista escorregadia | 5 |
| restricao de visibilidade | 2 |
| ultrapassagem indevida | 21 |
| velocidade incompativel | 62 |
| velocidade incompativel | 5 |
Mapa
Ao investigar a base nota-se que apenas os últimos dois anos (2018 e 2017) informam as coordenadas geográficas, portando para criar o mapa com o pacote leaflet foram selecionados apenas os dados referentes ao ano de 2018 e 2017:
base[10:11] %>%
map_df(~.x %>%
select(id, data_inversa, horario, br,km,
causa_acidente, tipo_acidente,
latitude, longitude) %>%
mutate(latitude = as.numeric(latitude),
longitude = as.numeric(longitude) )
) %>%
leaflet() %>%
addTiles() %>%
addMarkers(~longitude, ~latitude,
clusterOptions = markerClusterOptions(),
label = ~paste0(data_inversa,"-",horario,"\n Causa: ",causa_acidente,"\nTipo: ",tipo_acidente))%>%
addResetMapButton()%>%
addProviderTiles(providers$OpenStreetMap.Mapnik)Note que existem diversas ocorrências que apresentaram coordenadas geográficas fora dos limites da Ponte o que sugere que a amostra selecionada pode conter informações das redondezas. Estas informações serão avaliadas em conjunto com os dados referentes aos 13km da BR-101 que selecionamos.
Série temporal
Segundo @Morettin:
Def.: Uma série temporal é qualquer conjunto de observações ordenadas no tempo
Os objetivos da análise de séries temporais são, em geral:
- Investigar o mecanismo gerador da série temporal
- Fazer previsões de valores futuros da série (podem ser a curto prazo ou a longo prazo)
- Descrever apenas o comportamento da série, neste caso a construção do gráfico, a verificação da existência de tendências, ciclos e variações sazonais, a construção de histogramas e diagramas de dispersão etc podem ser ferramentas úteis
- Procurar periodicidade relevante nos dados
Etimologicamente (prae e videre), a palavra previsão sugere que se quer ver uma coisa antes que ela exista. Alguns autores preferem a palavra predição, para indicar algo que deverá existir no futuro. Ainda outros utilizam o termo projeção porém nosso objetivo neste post não será ajustar um modelo preditivo e sim um modelo descritivo que possibilite estudar o comportamento da série.
Após tomar uma intuição de como ocorrem os acidentes de maneira espacial na amostra, para responder a pergunta “O número de acidentes é diário?” precisamos obter a informação temporal dos dados e a melhor forma de visualizar este comportamento inicialmente é com um gráfico.
Número de acidentes por dia nos últimos 10 anos
Veja a seguir o número de acidentes, por id, diariamente e duas curvas de médias móveis com k = 30 e com k = 30*6 :
g1 <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente) ) %>%
dplyr::group_by(data_inversa)%>%
dplyr::summarise(n=n())%>%
mutate(rMM=rollmean(n,30, na.pad=TRUE, align="left")) %>%
mutate(rMY=rollmean(n,30*6, na.pad=TRUE, align="left")) %>%
tidyr::gather(medida,valor,n:rMY) %>%
ggplot(aes(x=data_inversa, y=valor,col=medida)) +
geom_line() +
scale_colour_manual(name="Legenda:",values=c("black","red","blue"),
labels = c('Acidentes','Médias móveis k=30', 'Médias móveis k=30*6')) +
theme_bw() +
labs(y= 'Número de acidentes',
x = 'Data',
subtitle = "Por dia",
title= 'Número de acidentes na Ponte Rio-Niterói',
caption = "Fonte dos dados:\nhttps://www.prf.gov.br/portal/dados-abertos/acidentes\nhttps://gomesfellipe.github.io/",col="") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_y_continuous(breaks=seq(0,15,1))
g1 +
scale_x_date(date_breaks = '6 months',limits = as.Date(c("2008-02-01","2018-12-01")),
expand = c(0.01,0.01)) +
theme(legend.position = c(0.85,0.7),
legend.background = element_rect(fill=alpha('lightgrey', 0.2)))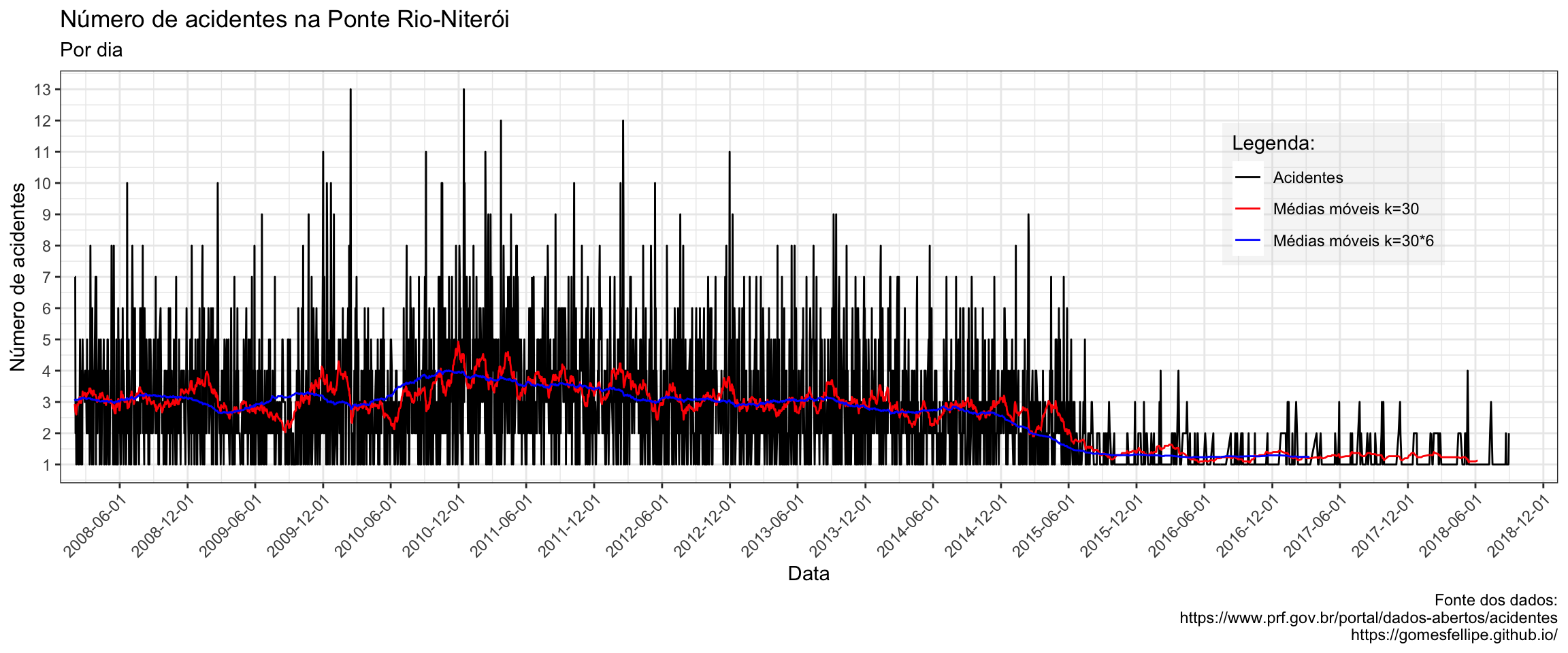
Este gráfico esta um pouco carregado com a informação levando em conta o número de acidentes por dia mas mesmo assim já é possível notar algumas informações como:
- Existem diversos dias que não houveram acidentes registrados pela PRF (diversos pontos tocam o eixo x)
- No ano de 2015 houve uma grotesca diminuição no registros do número de acidentes (o que será que aconteceu?)
A primeira pergunta parece ter sido respondida: O número de acidentes não parece ter sido diário nos últimos 10 anos segundo esses dados (e supondo que não houve subnotificação).
Já a hipótese levantada com a segunda pergunta parece ser verdadeira pois o comportamento dos dados sugerem ter havido a diminuição no número de acidentes.
Veja a seguir outra rápida análise exploratória para checar como se distribuem os número de acidentes ano longo dos anos e dos meses com alguns box-plots:
bp1 <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente) ) %>%
dplyr::group_by(data_inversa)%>%
dplyr::summarise(n=n()) %>%
tidyr::gather(medida,valor,n) %>%
ggplot(aes(x=factor(year(data_inversa)), y=valor,col=medida)) +
geom_jitter(col="darkgrey",alpha=0.3)+
geom_boxplot(col="black",alpha=0.3)+
theme_bw() +
labs(y= 'Número de acidentes',x="") +
theme(axis.text.x = element_text(angle = 30, hjust = 1)) +
scale_y_continuous(breaks=seq(0,15,1))+
geom_vline(xintercept = 8.5, linetype="dotted",
color = "red", size=1.5) +
annotate("label",y = 7, x = 8.5,
label = "Comportamentos \n diferentes",
size = 4, colour = "red",hjust=0.1)
bp2 <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente)) %>%
filter(year(data_inversa)<2016) %>%
dplyr::group_by(data_inversa) %>%
dplyr::summarise(n=n()) %>%
tidyr::gather(medida,valor,n) %>%
ggplot(aes(x=factor(months(data_inversa),
levels = months(base[[1]]$data_inversa) %>% unique),
y=valor,col=medida)) +
geom_jitter(col="darkgrey",alpha=0.3)+
geom_boxplot(color="black",alpha=0.3)+
theme_bw() +
labs(y= 'Número de acidentes',
title = 'Dados de 2008 até 2015',x="", col="") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_y_continuous(breaks=seq(0,15,1))+
theme(legend.position = c(0.85,0.7))
bp3 <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente) ) %>%
filter(year(data_inversa)>=2016) %>%
dplyr::group_by(data_inversa) %>%
dplyr::summarise(n=n()) %>%
tidyr::gather(medida,valor,n) %>%
ggplot(aes(x=factor(months(data_inversa),
levels = months(base[[1]]$data_inversa) %>% unique),
y=valor,col=medida)) +
geom_jitter(col="darkgrey",alpha=0.3)+
geom_boxplot(color="black",alpha=0.3)+
theme_bw() +
labs(y= '',
title = 'Dados de 2016 até 2018',x="",col="") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_y_continuous(breaks=seq(0,15,1))+
theme(legend.position = c(0.85,0.7))
bp2 <- arrangeGrob(bp2,bp3,ncol=2)grid.arrange(bp1,bp2,
top = "Boxplots do número de acidentes na Ponte Rio-Niterói",
bottom = textGrob("Fonte dos dados:\nhttps://www.prf.gov.br/portal/dados-abertos/acidentes\nhttps://gomesfellipe.github.io/",
gp = gpar(fontface = 3, fontsize = 9),
hjust = 1,x = 1 )) 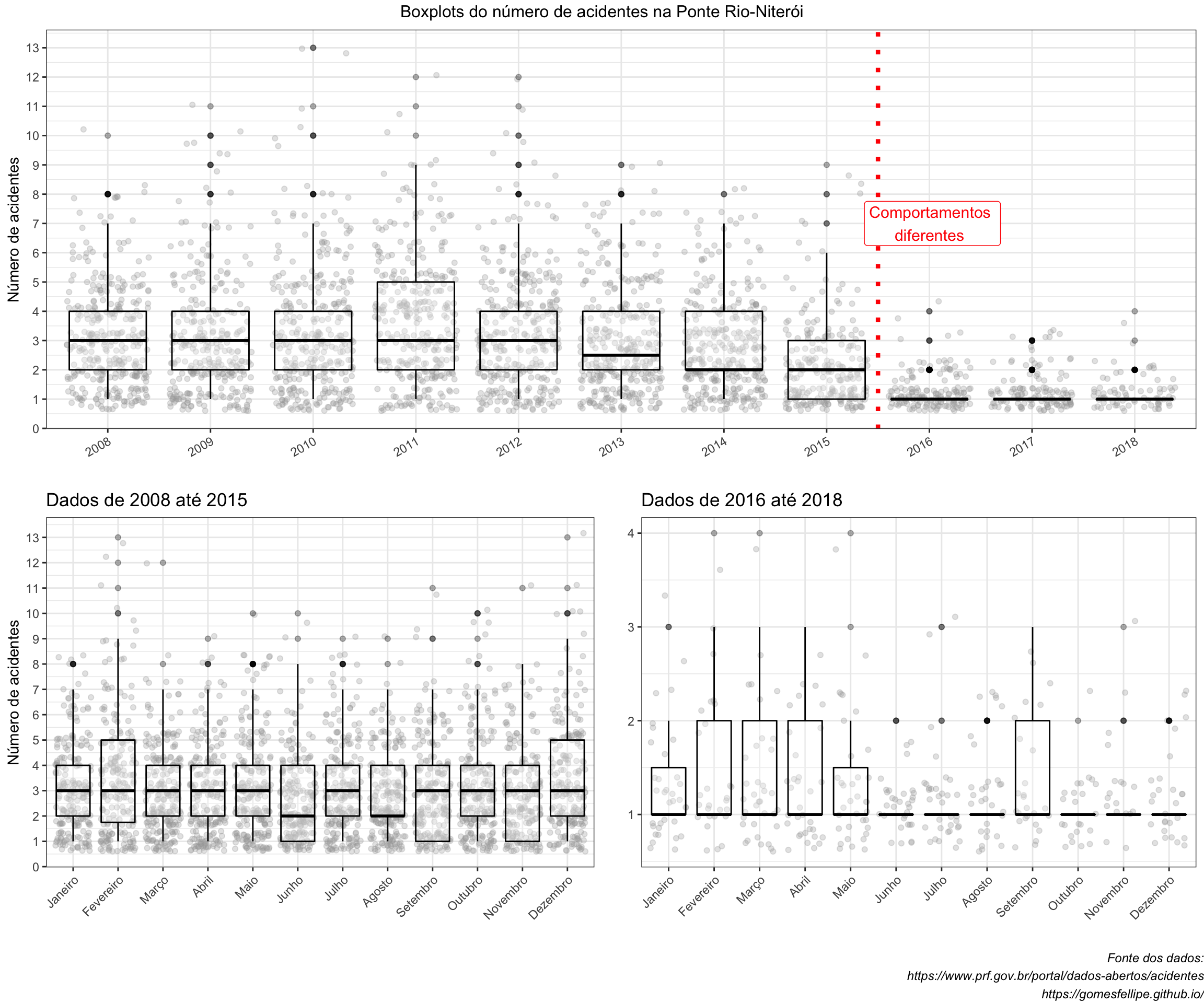
É possível notar que antes de 2016 todos aos boxplots apresentaram medianas parecidas enquanto que após o ano de 2016 parece haver mais acidentes apenas nos primeiros meses do ano.
Para responder a última pergunta vamos analisar com mais detalhes a série para entender melhor seu comportamento.
Número de acidentes por dia nos últimos 10 anos agrupados por ano
Veja a mesma informação do gráfico do número de acidentes na Ponte Rio-Niterói por dia, porém separado para cada ano:
g1 +
facet_wrap( ~ year(data_inversa), scales = "free_x") +
ggtitle("Número de acidentes na Ponte Rio-Niterói de acordo com o ano, por dia") +
scale_x_date(date_breaks = '1 month') +
theme(legend.position = c(0.85, 0.1))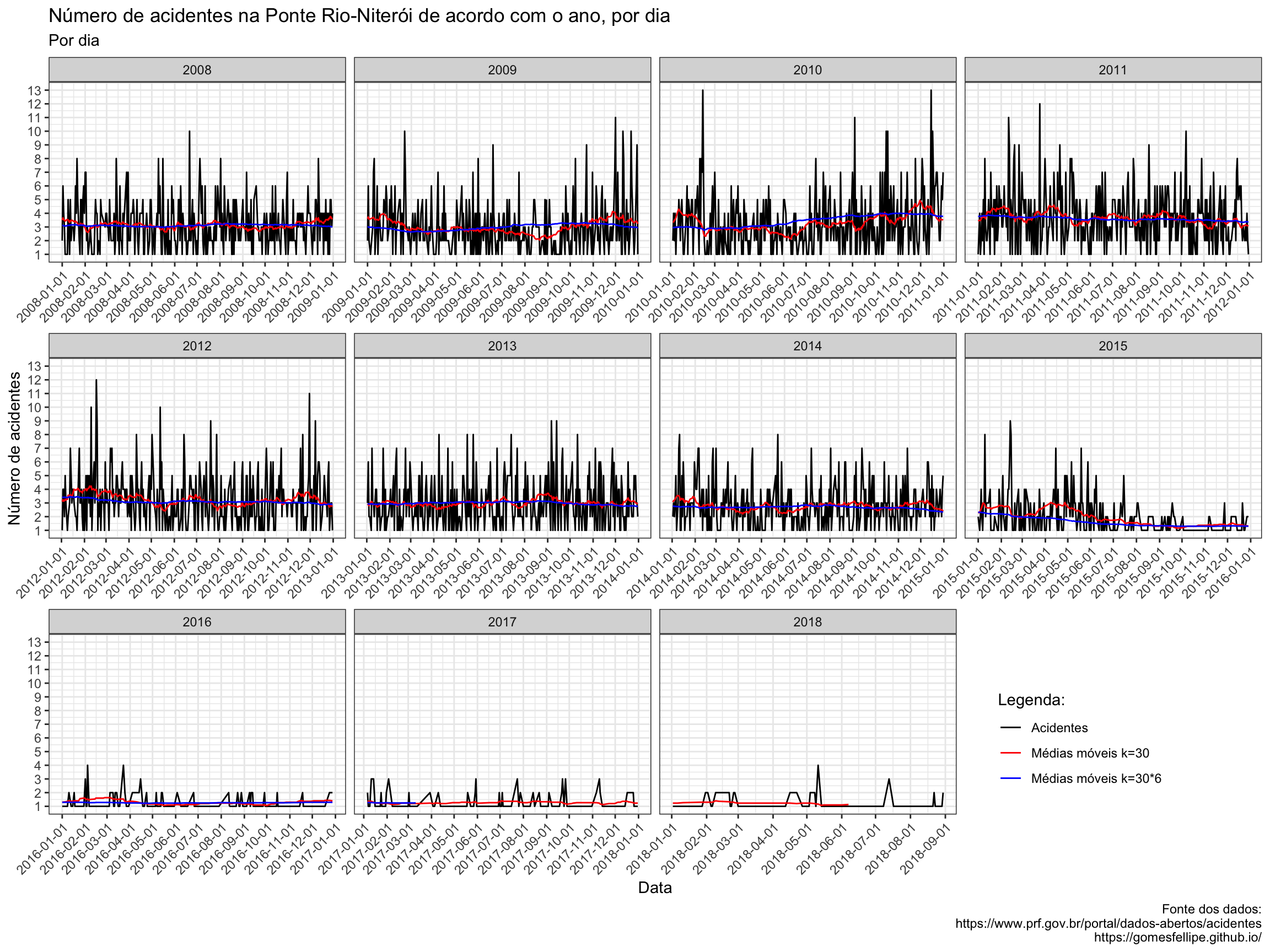
Agora ficou evidente que a partir do ano de 2015 o número de acidentes na Ponte Rio-Niterói foi reduzido e manteve-se abaixo do número médio registrado nos anos anteriores.
Mas o que aconteceu em 2015?
Já que em 2015 houve este comportamento tão brusco resolvi procurar no Google por notícias de acidentes na Ponte Rio-Niterói neste período e em uma breve pesquisa me deparei com a seguinte notícia:

Essa afirmação na manchete, que houve “redução de quase 60% após o videomonitoramento” é intrigante e seria interessante conseguir achar algum resultado concordante.
Na notícia " Monitoramento com câmeras ajuda a reduzir acidentes na Ponte Rio-Niterói " um inspetor da PRF faz a seguinte declaração:
“(…) Ajuda a amplificar o nosso poder de visualização das infrações que são cometidas. Concequentemente reduz o numero de acidentes por conta da presença quase que em todo trecho, ao mesmo tempo, da PRF”
Número de acidentes por mês nos últimos 10 anos agrupados
Como o gráfico ficou carregado ao levar em consideração o número de acidentes ao longo dos dias, a mesma informação será agrupada por mês.
Vejamos visualmente os dados fornecidos pela PRF e o dia em que a notícia foi atualizada:
g2 <-
base %>%
map_df(~.x
%>% select(id, data_inversa, causa_acidente, tipo_acidente) %>%
mutate_if(is.character,~ dmy(.x) )) %>%
group_by(month=floor_date(data_inversa, "1 month")) %>%
summarise(n = n()) %>%
ggplot(aes(x=month, y=n)) +
geom_line() +
geom_point() +
theme_bw() +
labs(y= 'Número de acidentes',
x = 'Data',
title= 'Número de acidentes na Ponte Rio-Niterói',
subtitle = "Por mês",
caption = "Fonte dos dados: \nhttp://glo.bo/210j8gF \nhttps://www.prf.gov.br/portal/dados-abertos/acidentes\nhttps://gomesfellipe.github.io/") +
scale_y_continuous(breaks=seq(0,150,25))
g2 +
geom_segment(x = as.Date("2015-11-13"), xend = as.Date("2015-11-13"),
y=0,yend=100, linetype="dashed", col="red") +
geom_text(aes(y = 100, x = as.Date("2015-11-13"),
label = "G1 em 17/11/2015 :\n\"Monitoramento com câmeras\n ajuda a reduzir acidentes\n na Ponte Rio-Niterói\"") ,hjust=-0.1) +
scale_x_date(date_breaks = '6 month') +
theme(axis.text.x = element_text(angle = 45, hjust = 1))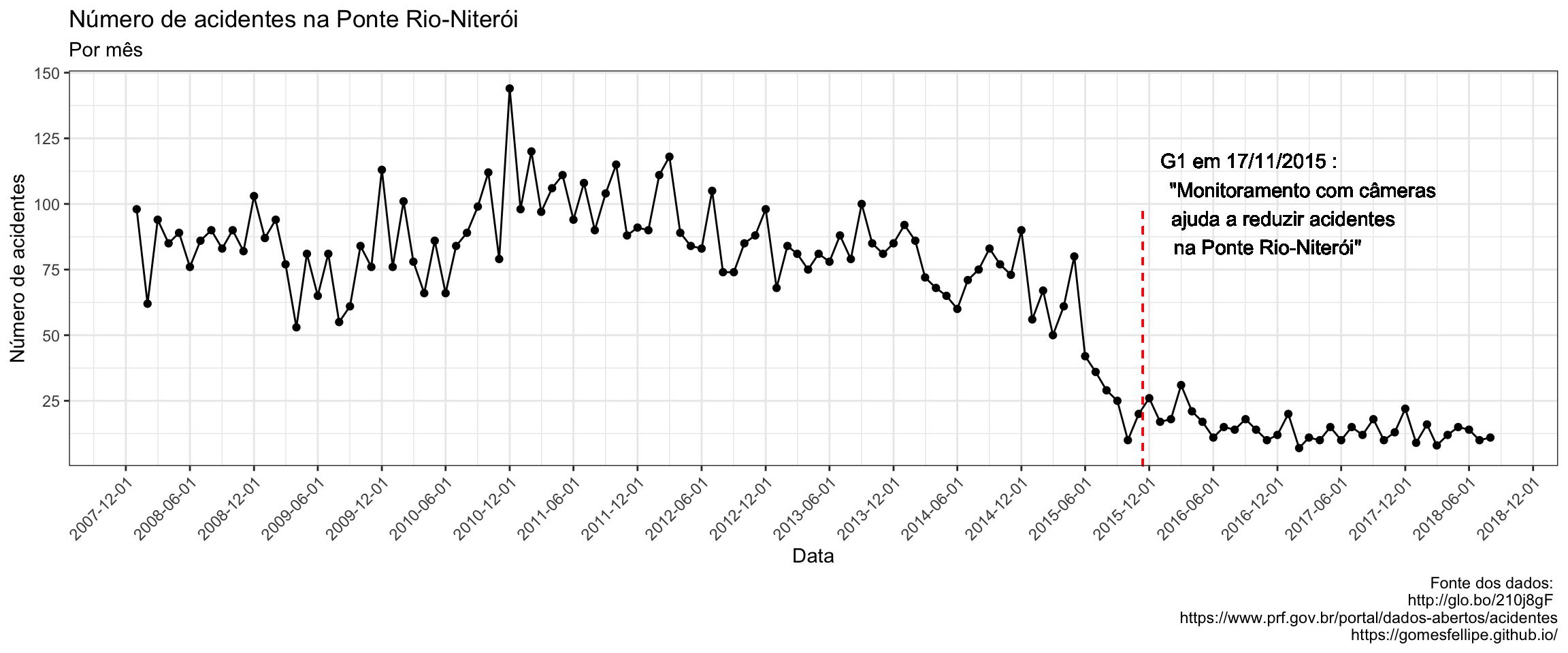
De fato, visualmente é possível notar uma aparente diminuição no ano do qual a notícia foi divulgada mas será que é possível identificar algum tipo de tendência a partir destes dados?
Número de acidentes por mês nos últimos 10 anos agrupados por ano
Vejamos a seguir o gráfico separado por cada ano para comparar o comportamento dos dados:
g2 +
# geom_smooth(method = "lm", se = F, aes(col = "blue")) +
facet_wrap( ~ year(month), scales = "free_x") +
scale_colour_manual(name=" ", values=c("blue"),labels=c("Regressão Linear")) +
theme(legend.position = c(0.88,0.20))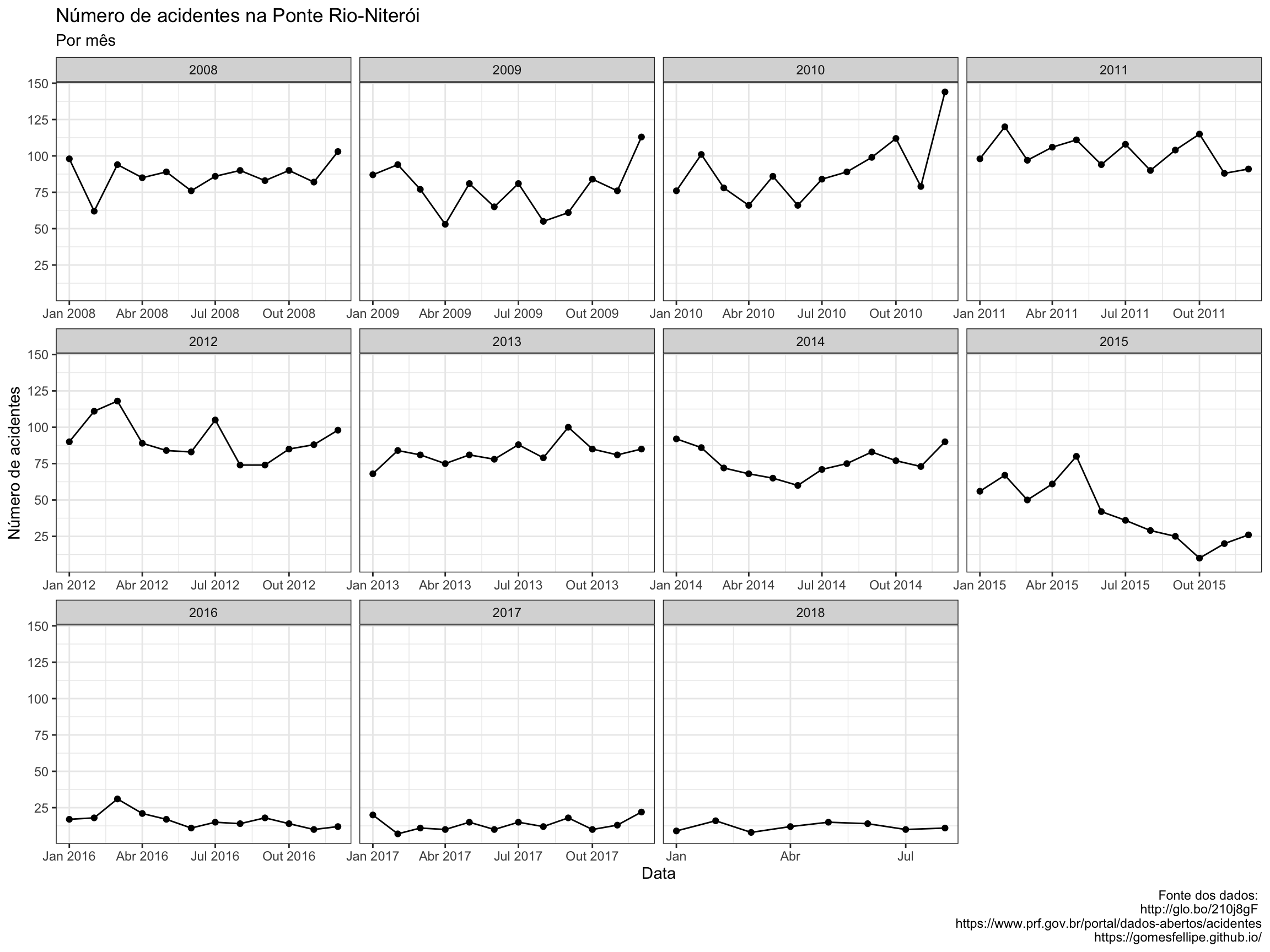
Neste gráfico vemos que dos anos de 2008 à 2014 os dados se comportam de forma parecida em torno de 100 à 75 acidentes. Porém em 2015 o número de acidentes termina por volta de 25 e este número se mantém ao longo dos anos.
Ajuste do modelo descritivo
Para entender melhor essa tendência apresentada em 2015 será ajustado modelo de regressão linear simples conforme metodologia apresentada em @tend, que utilizam o tempo como variável explicativa e entender qual foi a variação do número de acidentes médios por mês.
O método utilizado para avaliar a tendência consiste em um ajuste de tendência em função do tempo (\(t\)) com um modelo de regressão linear de maneira que:
\[ Y_{i} = \beta_0 + \beta_1 t_i + \epsilon_{i} \]
em que:
- \(Y_i\): Tendência para o número de acidentes médios por mês no instante \(i\)
- \(t_i\): i-ésimo instante de tempo
- \(\beta_0\): Intercepto do modelo (valor de \(Y_i\) quando \(t_i=0\))
- \(\beta_1\): Inclinação da reta ajustada (efeito da variável \(t_i\))
- \(\epsilon_i \sim N(0,\sigma^2)\) onde \(\sigma^2\) é constante
Este modelo de regressão linear mede a variação da tendência para diferentes valores de intervalo de tempo na faixa de interesse. O ajuste é interpretado de acordo com a inclinação da reta formada pelos diferentes valores de referência em relação a respectiva tendência pode não ser o melhor método para a previsão mas pode ajudar a entender o comportamento da série como análise descritiva.
to_lm <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente)%>%
mutate_if(is.character,~ dmy(.x) )) %>%
group_by(data_inversa=floor_date(data_inversa, "1 month")) %>%
summarise(n = n()) %>%
filter(data_inversa >= "2015-01-01" & data_inversa < "2016-01-01")
y <- to_lm %$% n %>% ts(start = c(2015, 01, 01))
g2 +
geom_smooth(method='lm',se=F,aes(col=I("darkred"))) +
geom_smooth(data=to_lm, aes(x=data_inversa, y=n,col=I("blue")), method = "lm",se=F) +
scale_colour_manual(name=NULL, values=c("red","blue","darkred"),labels=c(
"Regressão Linear para 2015",
"Regressão Linear para todo período",
"Notícia"
)) +
theme(legend.position = c(0.2,0.18)) +
geom_segment(x = as.Date("2015-11-13"), xend = as.Date("2015-11-13"),
y=0, yend=100, linetype="dashed", aes(col=I("red"))) +
geom_text(aes(y = 100, x = as.Date("2015-11-13"),
label = "G1 em 17/11/2015 :\n\"Monitoramento com câmeras\n ajuda a reduzir acidentes\n na Ponte Rio-Niterói\" ") ,hjust=-0.1) +
scale_x_date(date_breaks = '6 month') +
theme(axis.text.x = element_text(angle = 45, hjust = 1),
legend.background = element_rect(fill=alpha('lightgrey', 0.2)))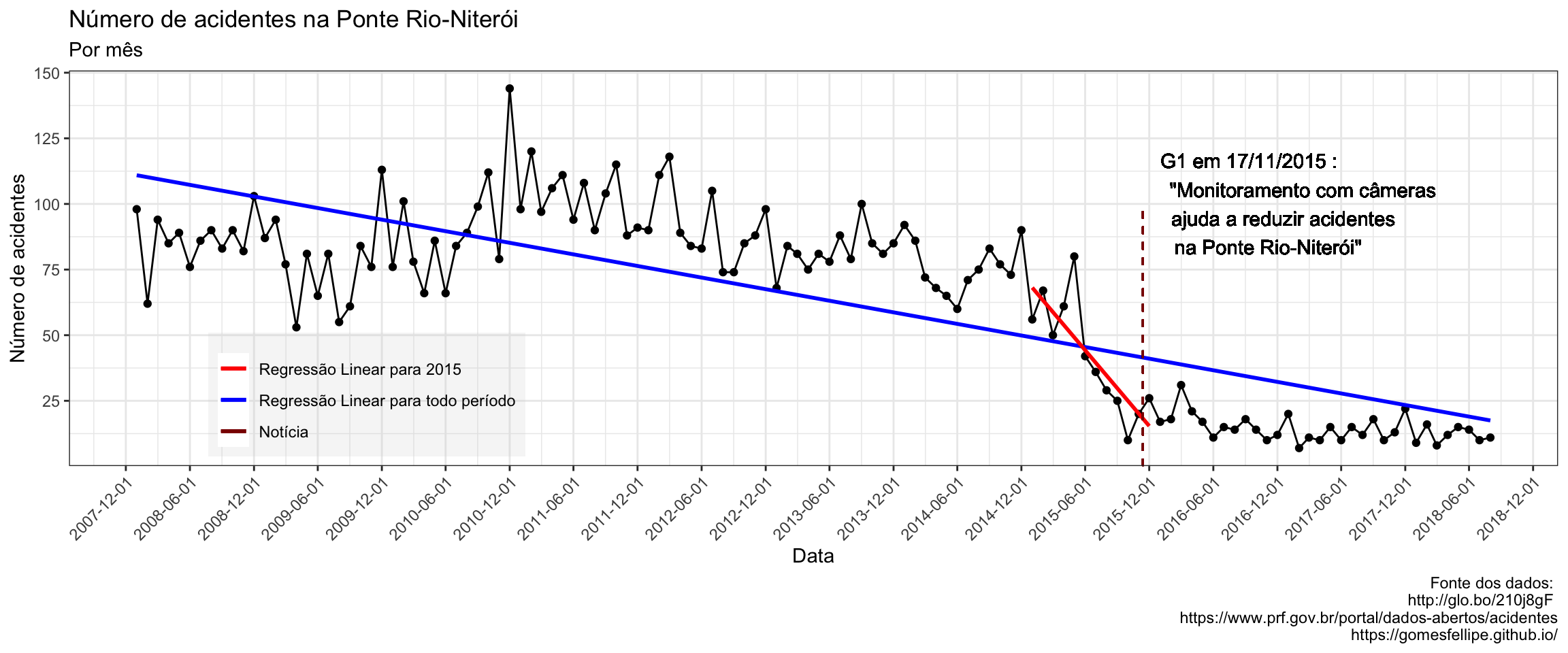
Antes de conferir os resultados do ajuste do modelo, veja o resultado para o teste de sequências (Wald-Wolfowitz) que tem como hipótese alternativa \(H_1:\) existe tendência na série
randtests::runs.test(y)##
## Runs Test
##
## data: y
## statistic = -3.0277, runs = 2, n1 = 6, n2 = 6, n = 12, p-value =
## 0.002465
## alternative hypothesis: nonrandomnessAo nível de significância de \(\alpha :\) 0.05 rejeita-se a hipótese nula de que esta série não apresenta tendência no período selecionado (2015).
Outra hipótese importante para conferir é sobre a normalidade da variável resposta, a seguir será aplicado o teste de Shapiro-wilk que tem como hipótese nula de que os dados possuem distribuição normal:
shapiro.test(y)##
## Shapiro-Wilk normality test
##
## data: y
## W = 0.9702, p-value = 0.9129De acordo com este teste, não existem evidências estatísticas para se rejeitar a hipótese da normalidade dos dados, portanto, para uma análise mais detalhada o modelo ajustado no período de 2015 pode ser obtido da seguinte maneira:
fit <- tslm(y ~ trend, data = y) Com o modelo está salvo no objeto fit, sua informação será incrementada no gráfico da regressão de 2015 para facilitar o entendimento dos resultados:
g1 <-
base %>%
map_df(~.x%>% select(id, data_inversa, causa_acidente, tipo_acidente)) %>%
group_by(data_inversa=floor_date(data_inversa, "1 month")) %>%
dplyr::summarise(n=n()) %>%
ggplot(aes(x=data_inversa, y=n)) +
geom_line() +
theme_bw() +
labs(y= 'Número de acidentes',
x = 'Data',
subtitle = "Por dia",
title= 'Número de acidentes na Ponte Rio-Niterói',
caption = "Fonte dos dados:\nhttp://glo.bo/210j8gF\nhttps://www.prf.gov.br/portal/dados-abertos/acidentes\nhttps://gomesfellipe.github.io/") +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_y_continuous(breaks=seq(0,100,25)) +
annotate("text", x=as.Date("2015-08-13"), y = 75,
label = paste("Modelo teórico: Yi = β^0 + β1 ti + ei:\nEstimador do Nº de acidentes =",round(fit$coefficients[1],2),round(fit$coefficients[2],2),"* Mês"))
t <-
fit %>%
tidy() %>%
bind_cols(r2=c(glance(fit)[[1]] %>% round(4),"-"),
confint_tidy(fit)) %>%
mutate_if(is.numeric,~ round(.x,4)) %>%
mutate(term = c("Intercepto", "Tendência")) %>%
set_names(c("Coef.", "Estimativa", "Erro Padrão", "Estatística", "Valor P", "R²","Lim. Inf.", "Lim. Sup."))
# Funcao auxiliar para colorir a celula
g <- tableGrob(t,rows = NULL)
find_cell <- function(table, row, col, name="core-fg"){
# Fonte:
# https://cran.r-project.org/web/packages/gridExtra/vignettes/tableGrob.html
l <- table$layout
which(l$t==row & l$l==col & l$name==name)
}
ind <- find_cell(g, 3, 2, "core-bg")
g$grobs[ind][[1]][["gp"]] <- gpar(fill="darkolivegreen1", col = "darkolivegreen4", lwd=5)
g1 +
scale_x_date(date_breaks = '1 months',
limits = as.Date(c("2015-01-01","2015-12-01")),
expand = c(0.01,0.01)) +
geom_smooth(data=to_lm, aes(x=data_inversa, y=n), method = "lm",col="red",se=F)+
annotation_custom(grob = g , ymax=220,xmin=as.Date("2015-04-01"))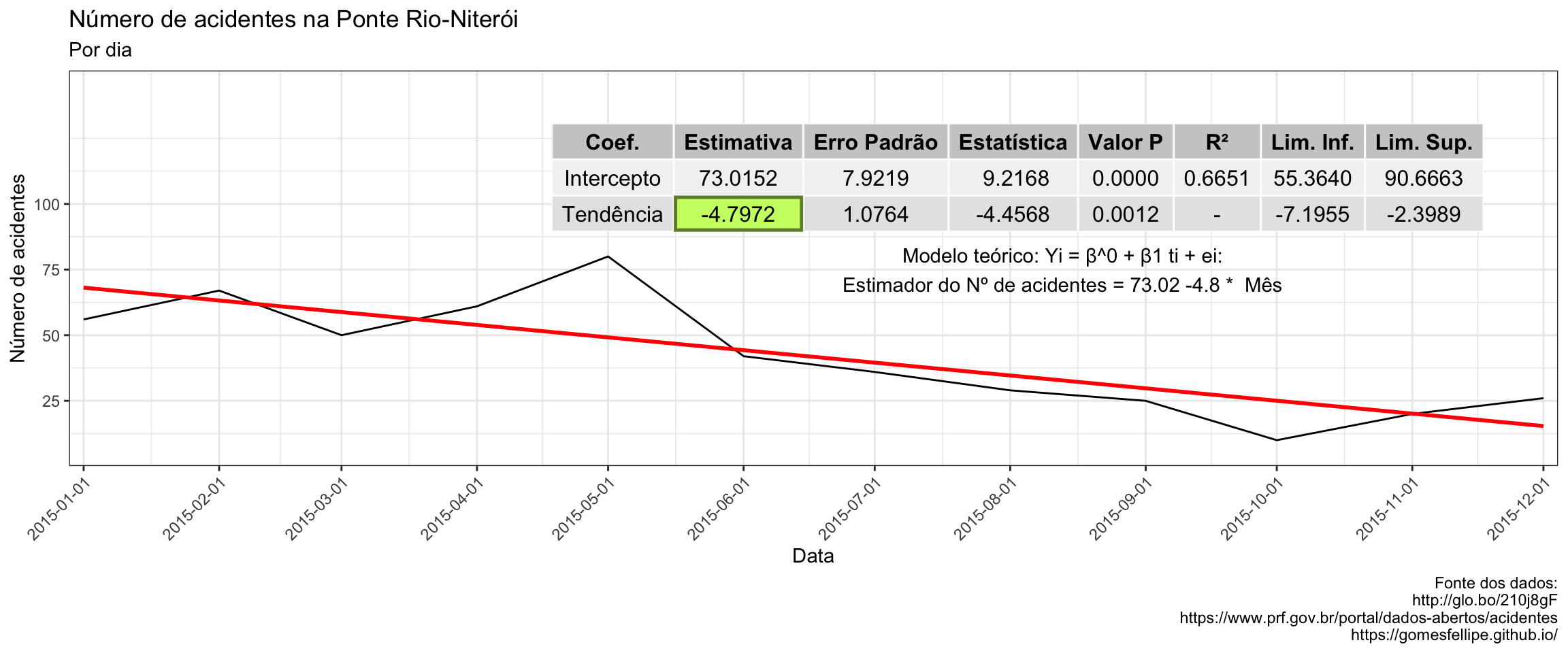
Nota-se que o coeficiente estimado para determinar a variação do número de acidentes ao aumentar a variável explicativa trend em uma unidade se apresenta de maneira significante, isto quer dizer que parece existir relação linear estatisticamente significante entre o mês da observação e a variável resposta.
Além disso é possível notar que para cada aumento de uma unidade da tred (ou seja, no decorrer de 1 mês), o valor esperado no número de acidentes observados naquele mês diminui em aproximadamente 4.7972.
Como -4.7972 x 12 = -57.5664 então o número de acidentes esperados decresce para aproximadamente 57.57% do valor original conforme a variável tred aumentou em 12 unidades (em 1 ano).
Veja o resultado para o teste de Shapiro - wilk para avaliar a hipótese de normalidade dos resíduos do modelo, os resíduos padronizados(quociente entre o resíduo e a estimativa do seu desvio padrão) e os resíduos studentizados, que levam em conta o \(h\) (medida de alavancagem ou " leverage") em sua medida:
bind_cols(
residuals = fit$residuals,
rstandard = rstandard(fit),
rstudent = rstudent(fit)
) %>%
map_dbl(~shapiro.test(.x)$p.value) %>%
tidy() %>%
set_names(c("Medida", "Valor p")) %>%
kable(escape = F) %>%
kable_styling("hover",full_width = F)| Medida | Valor p |
|---|---|
| residuals | 0.1166788 |
| rstandard | 0.1801799 |
| rstudent | 0.0058696 |
Não existem evidências para rejeitar a hipótese de que os resíduos do modelo e os resíduos padronizados seguem distribuição normal. Já para os resíduos studentizados rejeita-se a hipótese de normalidade e como o valor de R² não foi muito alto (66.51%), indicando que a reta ajustada explica parcialmente a variação dos dados então pode ser interessante estudar com mais detalhes qual foi a influência do número de acidentes em cada mês no ajuste do modelo calculando as medias de influência para cada observação do modelo.
Uma observação é considerada influente caso sua exclusão no ajuste do modelo de regressão cause uma mudança substancial na análise de regressão e para identificar essas observações serão utilizadas as mesmas medidas utilizadas no post que fiz sobre Pacotes do R para avaliar o ajuste de modelos.
De maneira visual e com medidas de influência do valor observado para cada mês no ajuste do modelo:
t1 <- influence.measures(fit) %$%
infmat %>%
as_tibble() %>%
map_df(~.x %>% round(4)) %>%
mutate(mes = 1:12) %>%
select(mes,everything()) %>%
set_names(c("Mês","DF β1","DF β2"," DFFit"," CovRatio"," D.Cook"," h"))
g <- tableGrob(t1,rows = NULL)
ind <- map_dbl(1:7, ~find_cell(g, 6, .x, "core-bg"))
walk(ind, function(i) g$grobs[i][[1]][["gp"]] <<-
gpar(fill = "darkolivegreen1", col = "darkolivegreen1", lwd = 5)
)
# g2 <-
# ggplot2::autoplot(fit, print=F,suppressMessages=T) +
# theme_bw()
#
# gn <- arrangeGrob(g2[[1]], g2[[2]], g2[[3]], g2[[4]], g2[[5]], g2[[6]])
#
# grid.arrange(gn, g, ncol=2)
grid.arrange(g)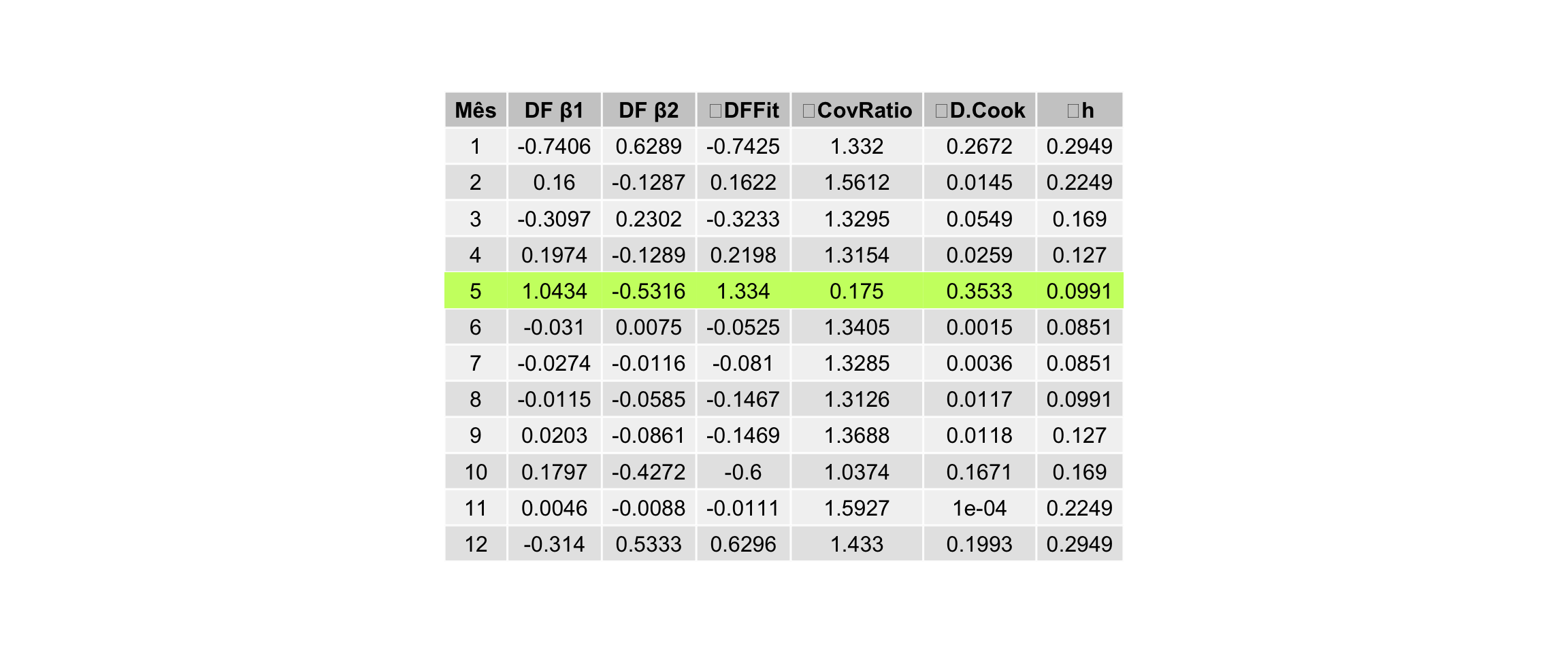
A tabela apresenta um resumo das medidas de inflencia de cada variável, segundo @gauss:
- DF Beta: Alteração no vetor estimado β ao se retirar o i-ésimo ponto da análise
- DF Fit: Alteração provocada no valor ajustado pela retirada da observação i
- CovRatio: Expressa o relação de covariância
- D.Cook: Medida de afastamento das estimativas ao retirar i e também considera o resíduo estudentizado internamente
- h: Elementos da diagonal da matriz H
É possível notar que no mês 5 (Maio) foi o mês que provocaria a maior alteração provocada no valor ajustado após sua retirada. Outra medida importante é a Distância de Cook que indica o quão atípica a observação \(i\) se apresenta no ajuste do modelo combinando os resíduos estudentizados e as medidas de alavancagem possibilitando examinar observações que influenciam bastante as estimativas dos parâmetros.
Em geral, se \(D_i>1\) o ponto é excessivamente influente mas como no geral as observações apresentaram valor muito inferior a 1 então a eliminação de qualquer uma dessas variáveis não vai alterar substancialmente as estimativas dos parâmetros porém nós podemos examinar quaisquer observações cujo \(D_i\) seja muito maior em relação aos demais valores estimados para \(D_i\) com mais cuidado para entender qual foi foi sua influência no ajuste do modelo:
# Como a funcao augment do broom nao parece mais suportar o modelo ajustado por tslm, vamos ajustar na mão o modelo com a tendencia para criar o gráfico:
to_lm <- to_lm %>% mutate(trend = 1:nrow(.))
fit_lm <- lm(y ~ trend, data = to_lm)
fit_lm %>%
broom::augment() %>%
mutate(col = if_else(.resid==max(.resid), T, F))%>%
mutate(trend = factor(months(base[[1]]$data_inversa) %>% unique,
levels = months(base[[1]]$data_inversa) %>% unique) ) %>%
ggplot(aes(x=trend,y=.resid,col=col,label=trend)) +
geom_point() +
geom_label(vjust = -0.25) +
theme_bw() +
scale_y_continuous(limits=c(-20,35),breaks = seq(-20,35,5)) +
scale_color_manual(values=c("black", "red")) +
geom_hline(yintercept = 0,linetype="dashed",col="red") +
theme(legend.position="none") +
labs(y="Resíduos", x="Valores ajustados", title="Resíduos vs Ajuste")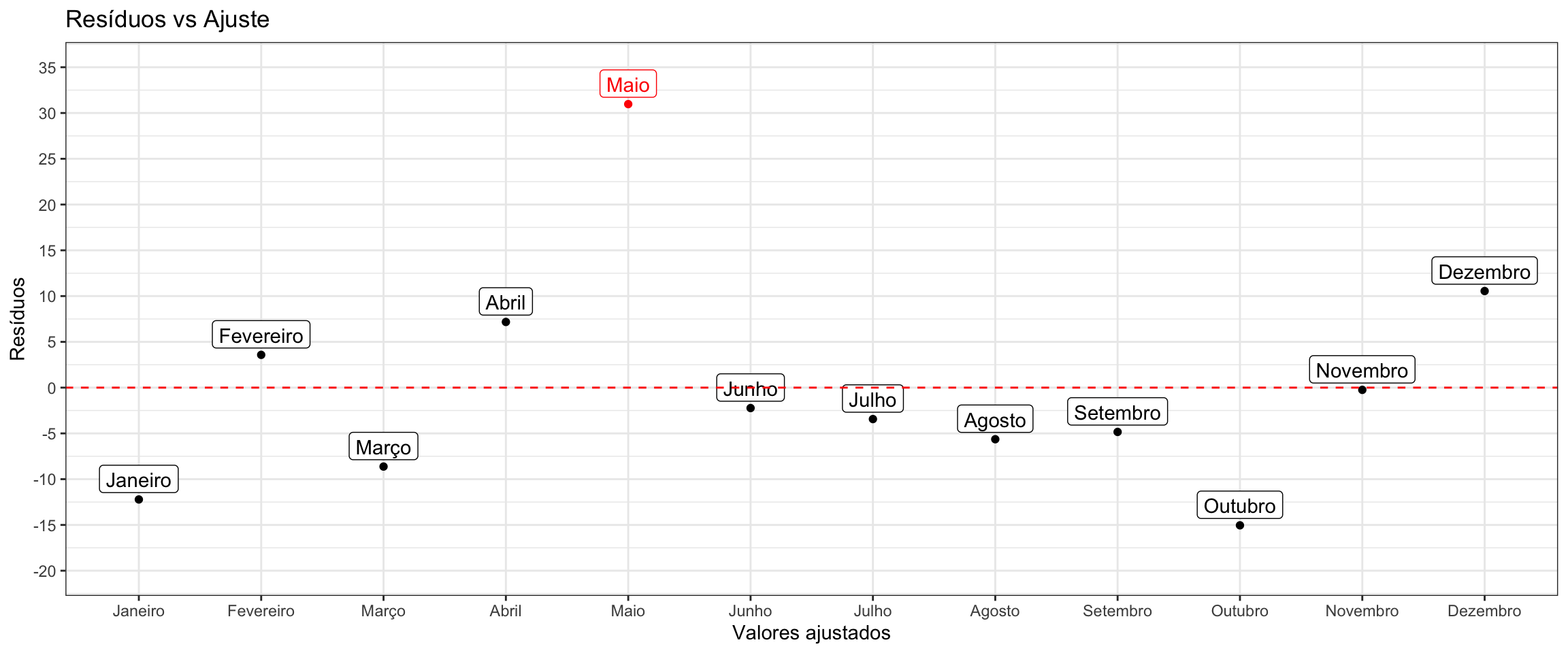
De fato o valor ajustado para o mês de maior é muito diferente do valor real observado, o que implica que houve um comportamento atípico que pode ser confirmado ao voltar no gráfico da série temporal e constatar um comportamento diferente (o número de acidente aumentou em relação ao anterior) e fugindo da tendência geral dos dados.
Próximos passos 
Uma das outras idéias que tive para a analisar estes dados conforme avançava com o estudo foi de cruza-los com o fluxo de carros na ponte para ter uma ideia de proporção mas essa ideia fica como sugestão para quem também tiver curiosidade sobre este assunto pois a intensão deste post é fazer uma análise de caráter introdutório para mostrar como é possível obter insights através dos dados com o uso da Estatística.
Além disso gostaria de incentivar todo o pessoal que gosta de dados e tiverem dúvidas sobre questões da vida, o universo e tudo mais a procurarem sempre por respostas mas tomar muito cuidado ao tirar conclusões! Este, por exemplo, foi um estudo de caráter introdutório e descritivo e obviamente existe uma porção de outras maneiras de estudar estes dados e como estamos diante de tanta abundância, basta uma pergunta que a investigação pode ser iniciada e se sempre temos a resposta para tudo nosso cérebro nunca entra “no modo de busca”. É importante sempre questionar respostas!
Referências
Notícia do G1: Monitoramento com câmeras ajuda a reduzir acidentes na Ponte Rio-Niterói

Share this post
Twitter
LinkedIn
Email