


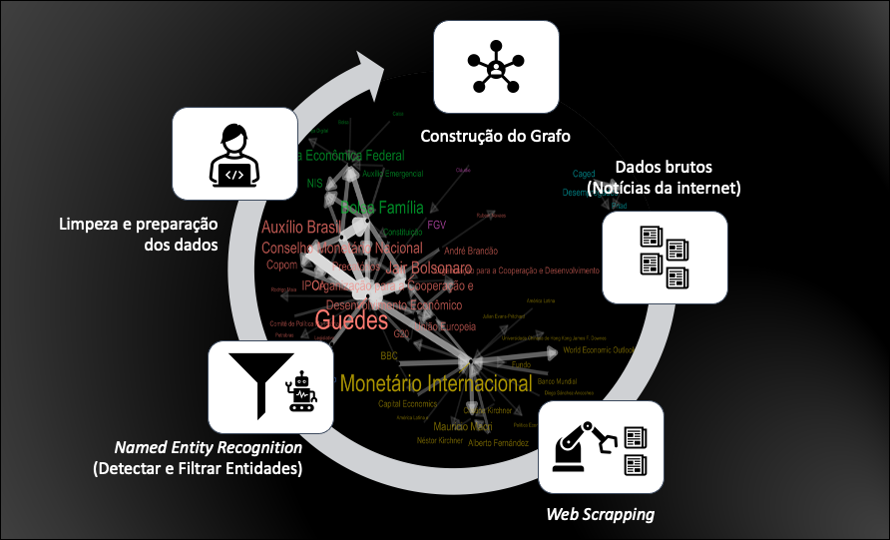






















Solução Final - Porto Seguro Data Challenge [3º lugar]
Confira a estratégia aplicada para a competição de machine learning do Porto Seguro hospedada no Kaggle

Em Agosto e 2021 a Porto Seguro lançou um desafio no Kaggle que consistia em estimar a propensão de aquisição de novos produtos. Tratava-se de um problema de classificação e foi bem desafiador principalmente por 2 motivos: