




































Brasil x Argentina, tidytext e Machine Learning
Aplicando técnincas de Text Mining como pacote tidy text para explorar a rivalidade entre Brasil e Argentina! Veja também como a análise de sentimentos pode ser divertida além de possíveis aplicações de machine learning

Brasil vs Argentina e Text Mining
A copa do mundo esta ai novamente e como não poderia ser diferente, com ela surgem novos quintilhões de bytes todos os dias, saber analisar esses dados é um grande desafio pois a maioria dessa informação se encontra de forma não estruturada e além do desafio de captar esses dados ainda existem mais desafios que podem ser ainda maiores, como o de processá-los e obter respostas deles.
Dada a rivalidade histórica entre Brasil e Argentina achei que seria interessante avaliar como anda o comportamento das pessoas do Brasil nas mídias sociais em relação a esses dois países. Para o post não ficar muito longo, escolhi que iria recolher informações apenas do Twitter devido a praticidade, foram coletados os últimos 4.000 tweets com o termo “brasil” e os últimos “4.000” tweets com o termo “argentina” no Twitter através da sua API com o pacote os twitteR e ROAuth. O código pode ser conferido neste link.
Análise de textos sempre foi um tema que me interessou muito, no final do ano de 2017 quando era estagiário me pediram para ajudar em uma pesquisa que envolvia a análise de palavras criando algumas nuvens de palavras. Pesquisando sobre técnicas de textmining descobri tantas abordagens diferentes que resolvi juntar tudo que tinha encontrado em uma única função (que será apresentada a seguir) para a confecção dessas nuvens, utilizarei esta função para ter uma primeira impressão dos dados.
Além disso, como seria um problema a tarefa de criar as nuvens de palavras só poderia ser realizada por alguém com conhecimento em R, na época estava começando meus estudo sobre shiny e como treinamento desenvolvi um app que esta hospedado no link: https://gomesfellipe.shinyapps.io/appwordcloud/ e o código esta aberto e disponível para quem se interessar no meu github neste link
Porém, após ler e estudar o livro Text Mining with R - A Tidy Approach por Silge; Robinson (2018) hoje em dia eu olho para trás e vejo que poderia ter feito tanto a função quanto o aplicativo de maneira muito mais eficiente portanto esse post trás alguns dos meus estudos sobre esse livro maravilhoso e também algum estudo sobre Machine Learning com o pacote caret
Importando a dados
Como já foi dito, a base de dados foi obtida através da API do twitter e o código pode ser obtido neste link.
library(dplyr)
library(kableExtra)
library(magrittr)
base <- read.csv("original_books.csv") %>% as_tibble()Nuvem de palavras rápida com função customizada
Para uma primeira impressão dos dados, vejamos o que retorna uma nuvem de palavras criada com a função wordcloud_sentiment() que desenvolvi antes de conhecer a “A Tidy Approach” para Text Mining:
devtools::source_url("https://raw.githubusercontent.com/gomesfellipe/functions/master/wordcloud_sentiment.R")
# Obtendo nuvem e salvando tabela num objeto com nome teste:
df <- wordcloud_sentiment(base$text,
type = "text",
sentiment = F,
excludeWords = c("nao",letters,LETTERS),
ngrams = 2,
tf_idf = F,
max = 100,
freq = 10,
horizontal = 0.9,
textStemming = F,
print=T)
Não poderia esquecer, além da nuvem, a função também retorna um dataframe com a frequência das palavras:
df %>% as_tibble()## # A tibble: 29,064 x 2
## words freq
## <chr> <chr>
## 1 = "2795"
## 2 brasil copa "2061"
## 3 copa mundo "1959"
## 4 hat trick "1327"
## 5 = hoje "1248"
## 6 hoje brasil "1215"
## 7 mundo " 852"
## 8 isl ndia " 820"
## 9 pra copa " 813"
## 10 estreia brasil " 782"
## # … with 29,054 more rowsE outra função interessante é a de criar uma nuvem a partir de um webscraping muito (muito mesmo) introdutório, para isso foi pegar todo o texto da página sobre a copa do mundo no Wikipédia, veja:
# Obtendo nuvem e salvando tabela num objeto com nome teste:
df_html <- wordcloud_sentiment("https://pt.wikipedia.org/wiki/Copa_do_Mundo_FIFA",
type = "url",
sentiment = F,
excludeWords = c("nao",letters,LETTERS),
ngrams = 2,
tf_idf = F,
max = 100,
freq = 6,
horizontal = 0.9,
textStemming = F,
print=T)
Essa função é bem “prematura,” existem infinitas maneiras de melhorar ela e não alterei ela ainda por falta de tempo.
A Tidy Approach
O formato tidy, em que cada linha corresponde a uma observação e cada coluna à uma variável, veja:

Agora a tarefa será simplificada com a abordagem tidy, além das funções do livro Text Mining with R utilizarei a função clean_tweets que adaptei inspirado nesse post dessa pagina: Quick guide to mining twitter with R quando estudava sobre textmining.
Arrumando e transformando a base de dados
Utilizando as funções do pacote tidytext em conjunto com os pacotes stringr e abjutils, será possível limpar e arrumar a base de dados.
Além disso serão removidas as stop words de nossa base, com a função stopwords::stopwords("pt") podemos obter as stopwords da nossa língua
library(stringr)
library(tidytext)
library(abjutils)
devtools::source_url("https://raw.githubusercontent.com/gomesfellipe/functions/master/clean_tweets.R")
original_books = base %>%
mutate(text = clean_tweets(text) %>% enc2native() %>% rm_accent())
#Removendo stopwords:
excludewords=c("[:alpha:]","[:alnum:]","[:digit:]","[:xdigit:]","[:space:]","[:word:]",
LETTERS,letters,1:10,
"hat","trick","bc","de","tem","twitte","fez",
'pra',"vai","ta","so","ja","rt")
stop_words = data_frame(word = c(stopwords::stopwords("pt"), excludewords))
tidy_books <- original_books %>%
unnest_tokens(word, text) %>%
anti_join(stop_words)Portando a base de dados após a limpeza e a remoção das stop words:
#Palavras mais faladas:
tidy_books %>% count(word, sort = TRUE) ## # A tibble: 3,900 x 2
## word n
## <chr> <int>
## 1 copa 6993
## 2 brasil 4164
## 3 argentina 3487
## 4 mundo 2030
## 5 hoje 1825
## 6 letras 1562
## 7 messi 1493
## 8 estreia 1107
## 9 est 866
## 10 isl 828
## # … with 3,890 more rows#Apos a limpeza, caso precise voltar as frases:
original_books = tidy_books%>%
group_by(book,line)%>%
summarise(text=paste(word,collapse = " "))Palavras mais frequentes
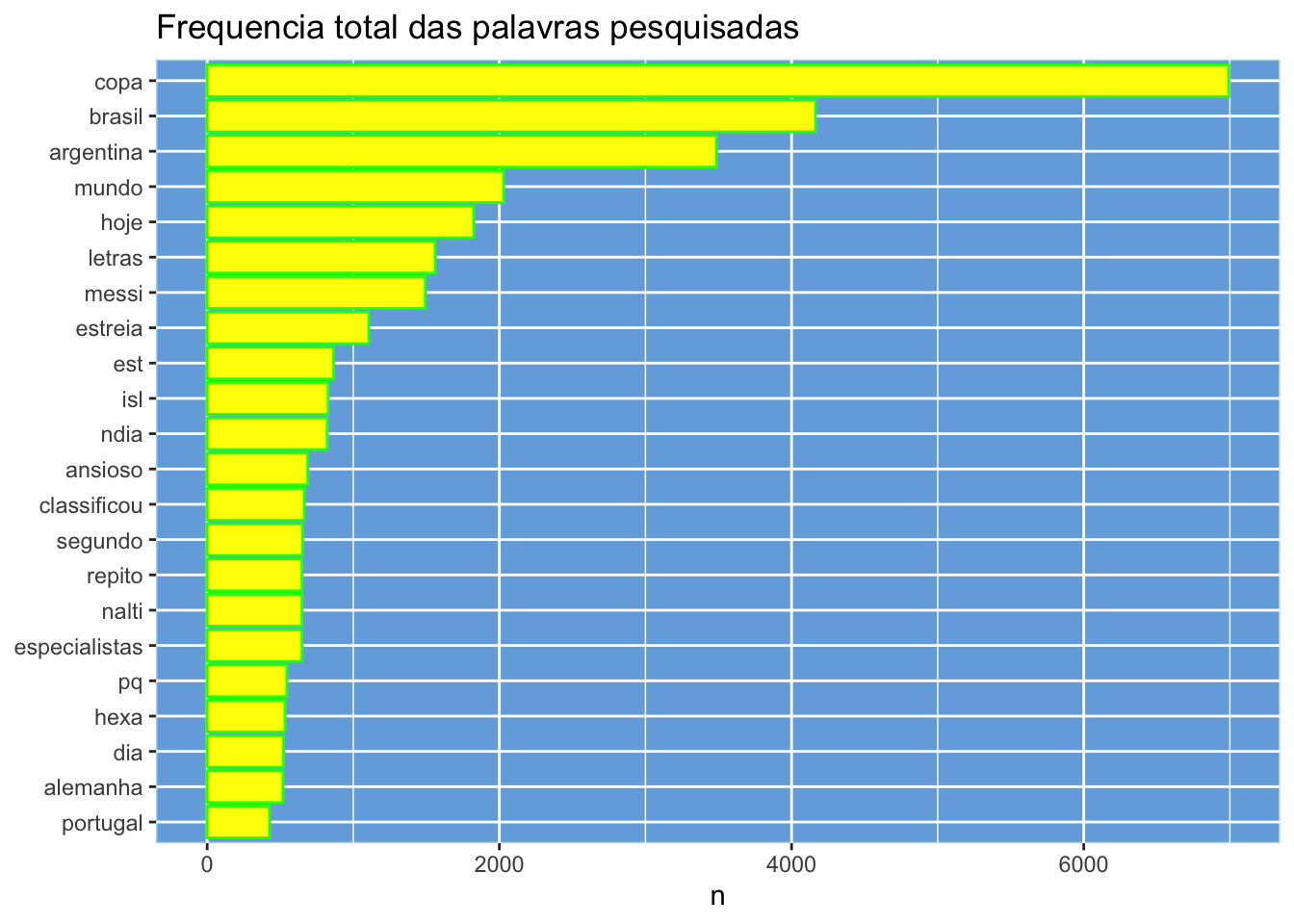
Vejamos as palavras mais faladas nessa pesquisa:
library(ggplot2)
tidy_books %>%
count(word, sort = TRUE) %>%
filter(n > 400) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = I("yellow"), colour = I("green"))) +
geom_col(position="dodge") +
xlab(NULL) +
labs(title = "Frequencia total das palavras pesquisadas")+
coord_flip()+ theme(
panel.background = element_rect(fill = "#74acdf",
colour = "lightblue",
size = 0.5, linetype = "solid"),
panel.grid.major = element_line(size = 0.5, linetype = 'solid',
colour = "white"),
panel.grid.minor = element_line(size = 0.25, linetype = 'solid',
colour = "white")
)
Palavras mais frequentes para cada termo
Vejamos as nuvens de palavras mais frequentes de acordo com cada um dos termos pesquisados:
#Criando nuvem de palavra:
library(wordcloud)
par(mfrow=c(1,2))
tidy_books %>%
filter(book=="br")%>%
count(word) %>%
with(wordcloud(word, n, max.words = 100,random.order = F,min.freq = 15,random.color = F,colors = c("#009b3a", "#fedf00","#002776"),scale = c(2,1),rot.per = 0.05))
tidy_books %>%
filter(book=="arg")%>%
count(word) %>%
with(wordcloud(word, n, max.words = 100,min.freq = 15,random.order = F,random.color = F,colors = c("#75ade0", "#ffffff","#f6b506"),scale = c(2,1),rot.per = 0.05))
par(mfrow=c(1,1))Análise de sentimentos
A análise de sentimentos utilizando a abordagem tidy foi possível graças ao pacote lexiconPT, que esta disponível no CRAN e que conheci ao ler o post: “O Sensacionalista e Text Mining: Análise de sentimento usando o lexiconPT” do blog Paixão por dados que gosto tanto de acompanhar.
# Analise de sentimentos:
library(lexiconPT)
sentiment = data.frame(word = sentiLex_lem_PT02$term ,
polarity = sentiLex_lem_PT02$polarity) %>%
mutate(sentiment = if_else(polarity>0,"positive",if_else(polarity<0,"negative","neutro")),
word = as.character(word)) %>%
as_tibble()
library(tidyr)
book_sentiment <- tidy_books %>%
inner_join(sentiment) %>%
count(book,word, index = line , sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative) %T>%
print## # A tibble: 2,953 x 7
## book word index negative neutro positive sentiment
## <chr> <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 arg abandonar 857 1 0 0 -1
## 2 arg absurdo 849 1 0 0 -1
## 3 arg absurdo 1863 1 0 0 -1
## 4 arg afogado 2275 1 0 0 -1
## 5 arg afogado 3659 1 0 0 -1
## 6 arg alegria 1134 0 0 1 1
## 7 arg almo 186 0 0 1 1
## 8 arg almo 2828 0 0 1 1
## 9 arg almo 3433 0 0 1 1
## 10 arg almo 3569 0 0 1 1
## # … with 2,943 more rowsCada palavra possui um valor associado a sua polaridade , vejamos como ficou distribuído o número de palavras de cada sentimento de acordo com cada termo escolhido para a pesquisa:
book_sentiment%>%
count(sentiment,book)%>%
arrange(book) %>%
ggplot(aes(x = factor(sentiment),y = n,fill=book))+
geom_bar(stat="identity",position="dodge")+
facet_wrap(~book) +
theme_bw()+
scale_fill_manual(values=c("#75ade0", "#009b3a"))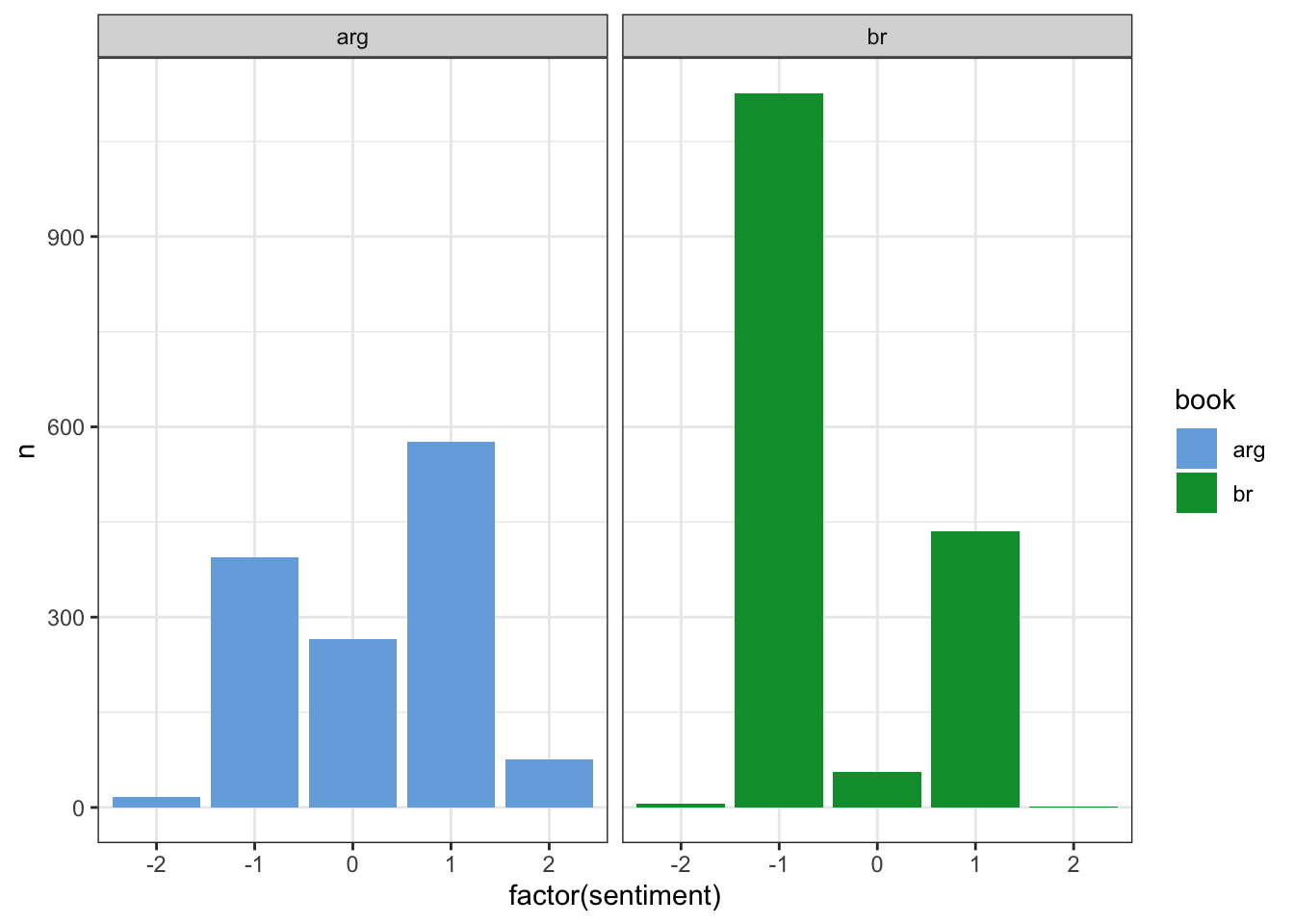
Comparando sentimentos dos termos de pesquisa
Para termos associados a palavra “Brasil” no twitter:
# Nuvem de comparação:
library(reshape2)
tidy_books %>%
filter(book=="br")%>%
inner_join(sentiment) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("red", "gray80","green"),
max.words = 200)
Para termos associados a palavra “Argentina” no twitter:
tidy_books %>%
filter(book=="arg")%>%
inner_join(sentiment) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("red", "gray80","green"),
max.words = 200)
Proporção de palavras positivas e negativas por texto
# Proporção de palavras negativas:
bingnegative <- sentiment %>%
filter(sentiment == "negative")
bingpositive <- sentiment %>%
filter(sentiment == "positive")
wordcounts <- tidy_books %>%
group_by(book, line) %>%
summarize(words = n())Para negativas;
tidy_books %>%
semi_join(bingnegative) %>%
group_by(book, line) %>%
summarize(negativewords = n()) %>%
left_join(wordcounts, by = c("book", "line")) %>%
mutate(ratio = negativewords/words) %>%
top_n(5) %>%
ungroup() %>% arrange(desc(ratio)) %>% filter(book=="br")## # A tibble: 5 x 5
## book line negativewords words ratio
## <chr> <int> <int> <int> <dbl>
## 1 br 2003 1 3 0.333
## 2 br 2775 1 3 0.333
## 3 br 2580 2 7 0.286
## 4 br 126 1 4 0.25
## 5 br 2335 1 4 0.25A frase mais negativa do brasil e da argentina::
base %>%
filter(book=="br",line==2580) %>% mutate(text = as.character(text))%>% select(text) %>% c() ## $text
## [1] "um medo? \x97 de nois criar expectativa e o Brasil perder a copa https://t.co/0chcNWHh0m"base %>%
filter(book=="arg",line==572) %>% mutate(text = as.character(text))%>% select(text) %>% c() ## $text
## [1] "RT @DavidmeMelo: @SantiiSanchez16 @Flamengo Perder a copa para o time mais sujo e mais corrupto da argentina \xe9 assim mesmo https://t.co/zIC\x85"Para positivas:
tidy_books %>%
semi_join(bingpositive) %>%
group_by(book, line) %>%
summarize(positivewords = n()) %>%
left_join(wordcounts, by = c("book", "line")) %>%
mutate(ratio = positivewords/words) %>%
top_n(5) %>%
ungroup() %>% arrange(desc(ratio))## # A tibble: 22 x 5
## book line positivewords words ratio
## <chr> <int> <int> <int> <dbl>
## 1 arg 2120 3 9 0.333
## 2 br 2374 1 3 0.333
## 3 arg 3272 2 7 0.286
## 4 arg 2301 1 4 0.25
## 5 br 126 1 4 0.25
## 6 br 553 2 8 0.25
## 7 br 1499 2 8 0.25
## 8 br 2054 2 8 0.25
## 9 br 2591 1 4 0.25
## 10 arg 2130 1 5 0.2
## # … with 12 more rowsA frase mais positiva do brasil e da argentina:
base %>%
filter(book=="br",line==2374) %>% mutate(text = as.character(text))%>% select(text) %>% c() ## $text
## [1] "Tirei Brasil, \xe9 uma honra https://t.co/OgNCot4Wu0"base %>%
filter(book=="arg",line==2120) %>% mutate(text = as.character(text))%>% select(text) %>% c() ## $text
## [1] "@_LeoFerreiraH Quero que a Argentina passe para possivelmente enfrentar o Brasil, ganhar da Argentina j\xe1 \xe9 bom, na\x85 https://t.co/bxHJUeGVpc"TF-IDF
Segundo Silge; Robinson (2018) no livro tidytextminig:
The statistic tf-idf is intended to measure how important a word is to a document in a collection (or corpus) of documents, for example, to one novel in a collection of novels or to one website in a collection of websites.
Traduzido pelo Google tradutor:
A estatística tf-idf destina-se a medir a importância de uma palavra para um documento em uma coleção (ou corpus) de documentos, por exemplo, para um romance em uma coleção de romances ou para um site em uma coleção de sites.
Matematicamente:
\[ idf(\text{term}) = \ln{\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}}\right)} \]
E que com o pacote tidytext podemos obter usando o comando bind_tf_idf(), veja:
# Obtendo numero de palavras
book_words <- original_books %>%
unnest_tokens(word, text) %>%
count(book, word, sort = TRUE) %>%
ungroup()%>%
anti_join(stop_words)
total_words <- book_words %>%
group_by(book) %>%
summarize(total = sum(n))
book_words <- left_join(book_words, total_words)
# tf-idf:
book_words <- book_words %>%
bind_tf_idf(word, book, n)
book_words %>%
arrange(desc(tf_idf))## # A tibble: 4,773 x 7
## book word n total tf idf tf_idf
## <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 br letras 1562 30429 0.0513 0.693 0.0356
## 2 br ansioso 688 30429 0.0226 0.693 0.0157
## 3 arg classificou 666 40781 0.0163 0.693 0.0113
## 4 arg segundo 654 40781 0.0160 0.693 0.0111
## 5 arg especialistas 649 40781 0.0159 0.693 0.0110
## 6 arg nalti 649 40781 0.0159 0.693 0.0110
## 7 arg repito 649 40781 0.0159 0.693 0.0110
## 8 br icon 248 30429 0.00815 0.693 0.00565
## 9 arg ncio 287 40781 0.00704 0.693 0.00488
## 10 arg penalti 284 40781 0.00696 0.693 0.00483
## # … with 4,763 more rowsO que nos trás algo como: “termos mais relevantes.”
Visualmente:
book_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(book) %>%
top_n(15) %>%
ungroup %>%
ggplot(aes(word, tf_idf, fill = book)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~book, ncol = 2, scales = "free") +
coord_flip()+
theme_bw()+
scale_fill_manual(values=c("#75ade0", "#009b3a"))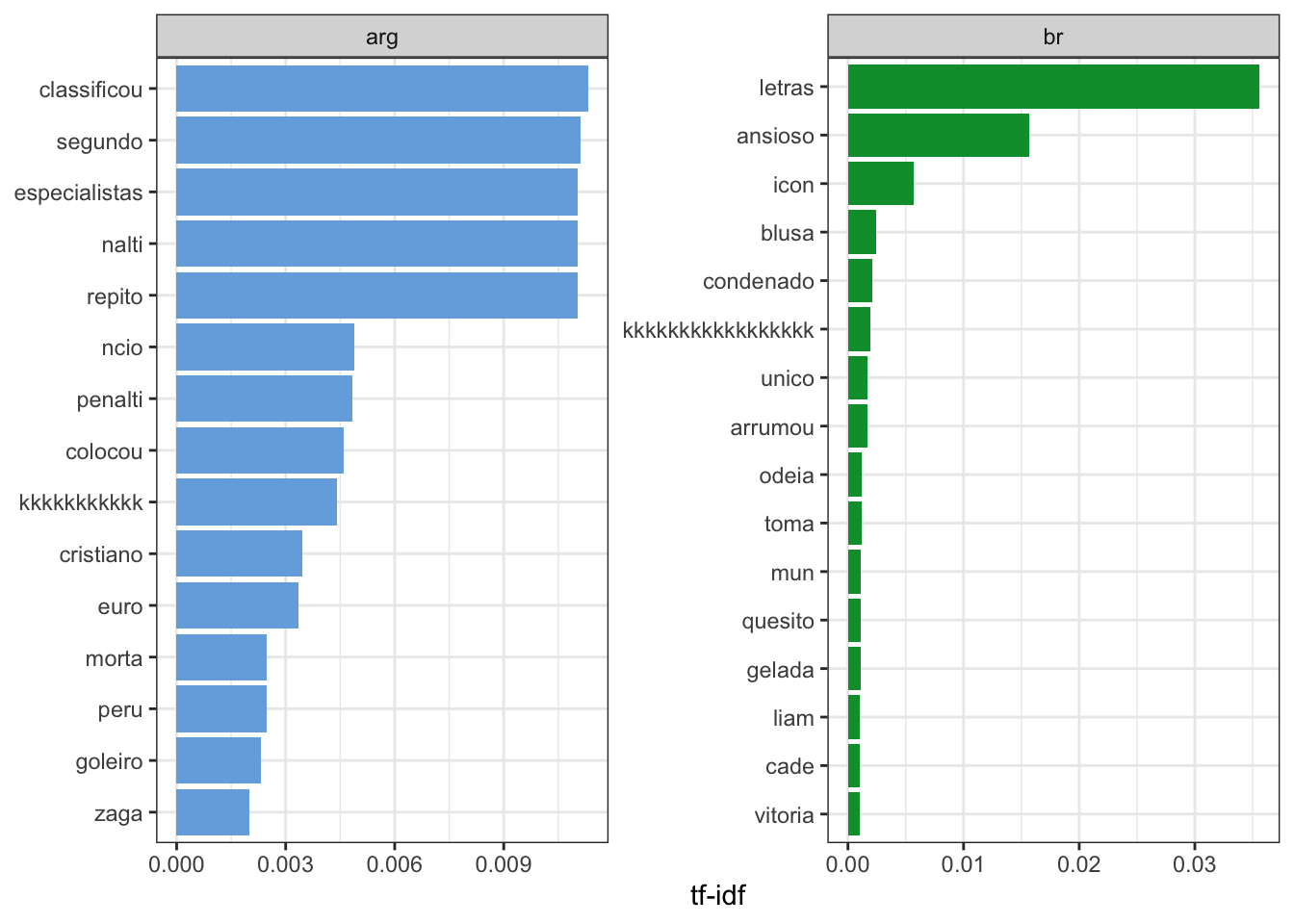
bi grams
OS bi grams são sequencias de palavras, a seguir será procurada as sequencias de duas palavras, o que nos permite estudar um pouco melhor o contexto do seu uso.
# Bi grams
book_bigrams <- original_books %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)
book_bigrams %>%
count(bigram, sort = TRUE)## # A tibble: 15,106 x 3
## # Groups: book [2]
## book bigram n
## <chr> <chr> <int>
## 1 br brasil copa 2039
## 2 br copa mundo 1459
## 3 br hoje brasil 1215
## 4 arg argentina copa 1122
## 5 arg isl ndia 818
## 6 br estreia brasil 764
## 7 br ansioso estreia 684
## 8 br est ansioso 680
## 9 arg classificou argentina 660
## 10 arg copa segundo 649
## # … with 15,096 more rowsSeparando as coluna de bi grams:
bigrams_separated <- book_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_words$word) %>%
filter(!word2 %in% stop_words$word)
# new bigram counts:
bigram_counts <- bigrams_filtered %>%
count(word1, word2, sort = TRUE)
bigram_counts## # A tibble: 15,106 x 4
## # Groups: book [2]
## book word1 word2 n
## <chr> <chr> <chr> <int>
## 1 br brasil copa 2039
## 2 br copa mundo 1459
## 3 br hoje brasil 1215
## 4 arg argentina copa 1122
## 5 arg isl ndia 818
## 6 br estreia brasil 764
## 7 br ansioso estreia 684
## 8 br est ansioso 680
## 9 arg classificou argentina 660
## 10 arg copa segundo 649
## # … with 15,096 more rowsCaso seja preciso juntar novamente:
bigrams_united <- bigrams_filtered %>%
unite(bigram, word1, word2, sep = " ")
bigrams_united## # A tibble: 71,208 x 2
## # Groups: book [2]
## book bigram
## <chr> <chr>
## 1 arg isl ndia
## 2 arg ndia pouco
## 3 arg pouco mil
## 4 arg mil habitantes
## 5 arg habitantes montaram
## 6 arg montaram sele
## 7 arg sele est
## 8 arg est copa
## 9 arg copa fizeram
## 10 arg fizeram gol
## # … with 71,198 more rowsAnalisando bi grams com tf-idf
Também é possível aplicar a transformação tf-idf em bigrams, veja:
#bi grams com tf idf
bigram_tf_idf <- bigrams_united %>%
count(book, bigram) %>%
bind_tf_idf(bigram, book, n) %>%
arrange(desc(tf_idf))
bigram_tf_idf## # A tibble: 15,106 x 6
## # Groups: book [2]
## book bigram n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 br hoje brasil 1215 0.0399 0.693 0.0277
## 2 br ansioso estreia 684 0.0225 0.693 0.0156
## 3 br est ansioso 680 0.0223 0.693 0.0155
## 4 br letras letras 620 0.0204 0.693 0.0141
## 5 arg classificou argentina 660 0.0162 0.693 0.0112
## 6 arg copa segundo 649 0.0159 0.693 0.0110
## 7 arg messi repito 649 0.0159 0.693 0.0110
## 8 arg repito classificou 649 0.0159 0.693 0.0110
## 9 arg segundo especialistas 649 0.0159 0.693 0.0110
## 10 br brasil letras 313 0.0103 0.693 0.00713
## # … with 15,096 more rowsAnalisando contexto de palavras negativas:
Uma das abordagens interessantes ao estudar as bi-grams é a de avaliar o contexto das palavras negativas, veja:
bigrams_separated %>%
filter(word1 == "nao") %>%
count(word1, word2, sort = TRUE)## # A tibble: 35 x 4
## # Groups: book [2]
## book word1 word2 n
## <chr> <chr> <chr> <int>
## 1 br nao copa 10
## 2 arg nao abrir 3
## 3 arg nao convoca 3
## 4 arg nao ruim 3
## 5 br nao acredito 2
## 6 arg nao achei 1
## 7 arg nao acordem 1
## 8 arg nao argentina 1
## 9 arg nao assisti 1
## 10 arg nao compara 1
## # … with 25 more rowsnot_words <- bigrams_separated %>%
filter(word1 == "nao") %>%
inner_join(sentiment, by = c(word2 = "word")) %>%
count(word2, sentiment, sort = TRUE) %>%
ungroup()
not_words## # A tibble: 3 x 4
## book word2 sentiment n
## <chr> <chr> <chr> <int>
## 1 arg ruim negative 3
## 2 arg vencer positive 1
## 3 br amistoso positive 1A palavra não antes de uma palavra “positiva,” como por exemplo “não gosto” pode ser anulada ao somar-se suas polaridades (“não” = - 1, “gosto” = +1 e “não gosto” = -1 + 1) o leva a necessidade de ser tomar um cuidado especial com essas palavras em uma análise de texto mais detalhada, veja de forma visual:
not_words %>%
mutate(sentiment=ifelse(sentiment=="positive",1,ifelse(sentiment=="negative",-1,0)))%>%
mutate(contribution = n * sentiment) %>%
arrange(desc(abs(contribution))) %>%
head(20) %>%
mutate(word2 = reorder(word2, contribution)) %>%
ggplot(aes(word2, n * sentiment, fill = n * sentiment > 0)) +
geom_col() +
xlab("Words preceded by \"not\"") +
ylab("Sentiment score * number of occurrences") +
coord_flip()+
theme_bw()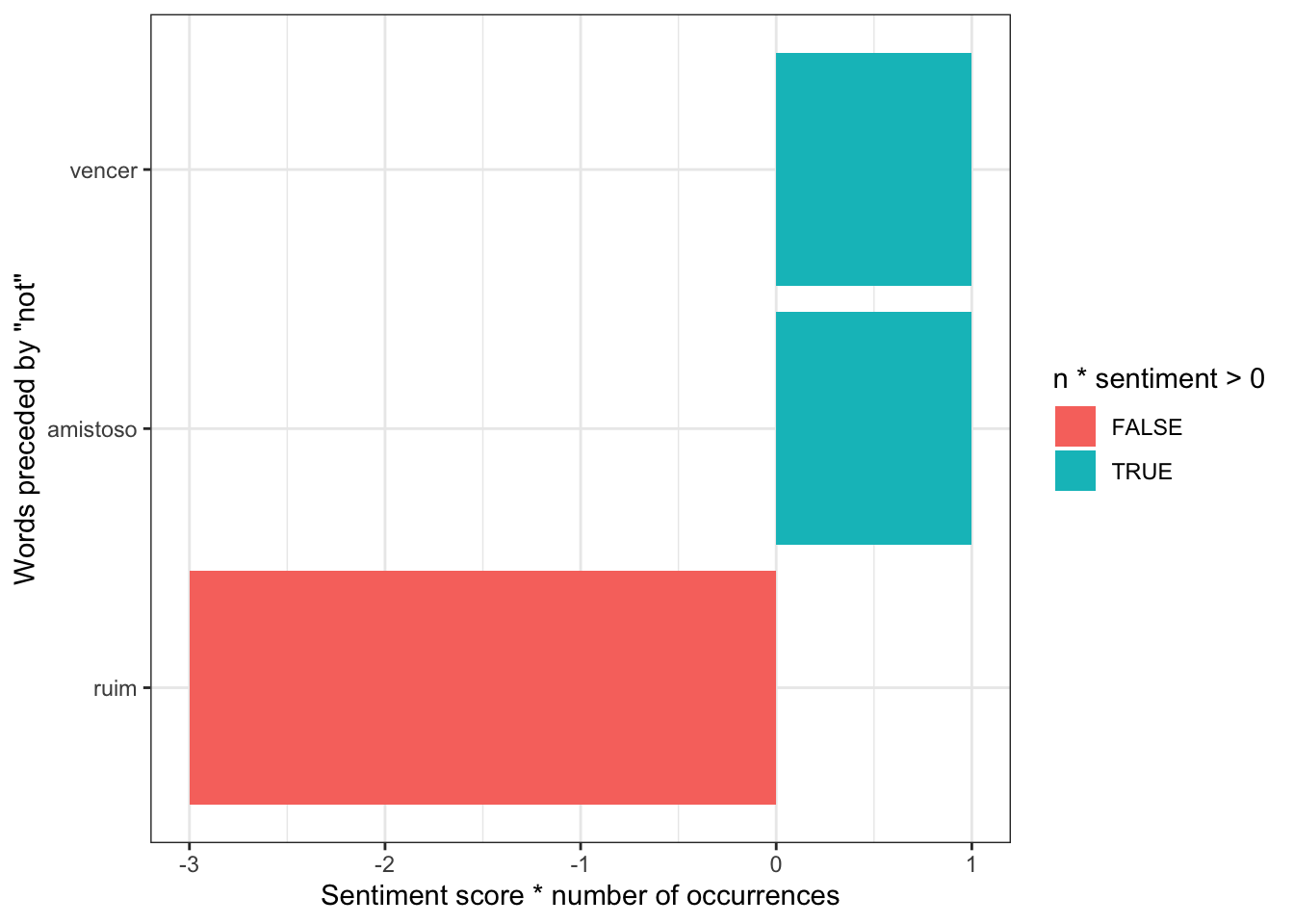
Machine Learning
Estava pesquisando sobre algorítimos recomendados para a análise de texto quando encontrei um artigo da data camp chamado: Lyric Analysis with NLP & Machine Learning with R, do qual a autora expõe a seguinte tabela:

Portanto resolvi fazer uma brincadeira e ajustar 4 dos modelos propostos para a tarefa supervisionada de classificação: K-NN, Tress (tentarei o ajuste do algorítimo Random Forest), Logistic Regression (Modelo estatístico) e Naive-Bayes (por meio do cálculo de probabilidades condicionais) para ver se conseguia recuperar a classificação de quais os termos de pesquisa que eu utilizei para obter esses dados
Além de técnicas apresentadas no livro do pacote caret, por Kuhn (2018), muito do que apliquei aqui foi baseado no livro “Introdução a mineração de dados” por Silva; Peres; Boscarioli (2016), que foi bastante útil na minha introdução sobre o tema Machine Learning.
Vou utilizar uma função chamada plot_pred_type_distribution(),apresentada neste post de titulo: Illustrated Guide to ROC and AUC e fiz uma pequena alteração para que ela funcionasse para o dataset deste post . A função adaptada pode ser encontrada neste link no meu github e a função original neste link do github do autor.
Pacote caret
Basicamente o ajuste de todos os modelos envolveram o uso do pacote caret e muitos dos passos aqui foram baseados nas instruções fornecidas no livro do pacote. O pacote facilita bastante o ajuste dos parâmetros no ajuste de modelos.
Transformar e arrumar
Uma solução do kaggle para o desafio Toxic Comment Classification Challenge me chamou atenção, do qual o participante da competição criou colunas que sinalizassem os caracteres especiais de cada frase, utilizarei esta técnica para o ajuste e novamente utilizarei o pacote de léxicos do apresentado no post do blog Paixão por dados
Veja a base transformada e arrumada:
# Ref: https://cfss.uchicago.edu/text_classification.html
# https://www.r-bloggers.com/illustrated-guide-to-roc-and-auc/
devtools::source_url("https://raw.githubusercontent.com/gomesfellipe/functions/master/plot_pred_type_distribution.R")
base <- base %>%
mutate(length = str_length(text),
ncap = str_count(text, "[A-Z]"),
ncap_len = ncap / length,
nexcl = str_count(text, fixed("!")),
nquest = str_count(text, fixed("?")),
npunct = str_count(text, "[[:punct:]]"),
nword = str_count(text, "\\w+"),
nsymb = str_count(text, "&|@|#|\\$|%|\\*|\\^"),
nsmile = str_count(text, "((?::|;|=)(?:-)?(?:\\)|D|P))"),
text = clean_tweets(text) %>% enc2native() %>% rm_accent())%>%
unnest_tokens(word, text) %>%
anti_join(stop_words)%>%
group_by(book,line,length, ncap, ncap_len, nexcl, nquest, npunct, nword, nsymb, nsmile)%>%
summarise(text=paste(word,collapse = " ")) %>%
select(text,everything())%T>%
print()## # A tibble: 7,995 x 12
## # Groups: book, line, length, ncap, ncap_len, nexcl, nquest, npunct, nword,
## # nsymb [7,995]
## text book line length ncap ncap_len nexcl nquest npunct nword nsymb
## <chr> <chr> <int> <int> <int> <dbl> <int> <int> <int> <int> <int>
## 1 isl … arg 1 NA 7 NA 0 0 6 24 1
## 2 pau … arg 2 108 6 0.0556 0 0 2 20 1
## 3 mess… arg 3 NA 10 NA 0 0 3 24 1
## 4 minu… arg 4 NA 2 NA 0 0 2 24 1
## 5 requ… arg 5 129 23 0.178 0 0 15 21 1
## 6 bras… arg 6 NA 11 NA 0 0 12 20 1
## 7 dupl… arg 7 123 84 0.683 0 0 8 21 1
## 8 mess… arg 8 NA 10 NA 0 0 3 24 1
## 9 mess… arg 9 NA 10 NA 0 0 3 24 1
## 10 mess… arg 10 NA 10 NA 0 0 3 24 1
## # … with 7,985 more rows, and 1 more variable: nsmile <int>Após arrumar e transformar as informações que serão utilizadas na classificação, será criado um corpus sem a abordagem tidy para obter a matriz de documentos e termos, e depois utilizar a coluna de classificação, veja:
library(tm) #Pacote de para text mining
corpus <- Corpus(VectorSource(base$text))
#Criando a matrix de termos:
book_dtm = DocumentTermMatrix(corpus, control = list(minWordLength=2,minDocFreq=3)) %>%
weightTfIdf(normalize = T) %>% # Transformação tf-idf com pacote tm
removeSparseTerms( sparse = .95) # obtendo matriz esparsa com pacote tm
#Transformando em matrix, permitindo a manipulacao:
matrix = as.matrix(book_dtm)
dim(matrix)## [1] 7995 18Pronto, agora já podemos juntar tudo em um data frame e separa em treino e teste para a classificação dos textos obtidos do twitter:
#Criando a base de dados:
full=data.frame(cbind(
base[,"book"],
matrix,
base[,-c(1:3)]
)) %>% na.omit()Treino e teste
Será utilizado tanto o método de hold-out e de cross-validation
set.seed(825)
particao = sample(1:2,nrow(full), replace = T,prob = c(0.7,0.3))
train = full[particao==1,]
test = full[particao==2,]
library(caret)Ajustando modelos
KNN
É uma técnica de aprendizado baseado em instância, isto quer dizer que a classificação de uma observação com a classe desconhecida é realizada a partir da comparação com outras observações cada vez que uma observação é apresentado ao modelo e também é conhecido como “lazy evaluation,” já que um modelo não é induzido previamente.
Diversas medidas de distância podem ser utilizadas, utilizarei aqui a euclideana e além disso a escolha do parâmetro \(k\) (de k vizinhos mais próximos) deve ser feita com cuidado pois um \(k\) pequeno pode expor o algorítimo a uma alta sensibilidade a um ruído.
Utilizarei aqui o pacote caret como ferramenta para o ajuste deste modelo pois ela permite que eu configure que seja feita a validação cruzada em conjunto com a padronização, pois esses complementos beneficiam no ajuste de modelos que calculam distâncias.
# knn -------
set.seed(825)
antes = Sys.time()
book_knn <- train(book ~.,
data=train,
method = "knn",
trControl = trainControl(method = "cv",number = 10), # validacao cruzada
preProc = c("center", "scale"))
time_knn <- Sys.time() - antes
Sys.time() - antes## Time difference of 2.465522 secsplot(book_knn)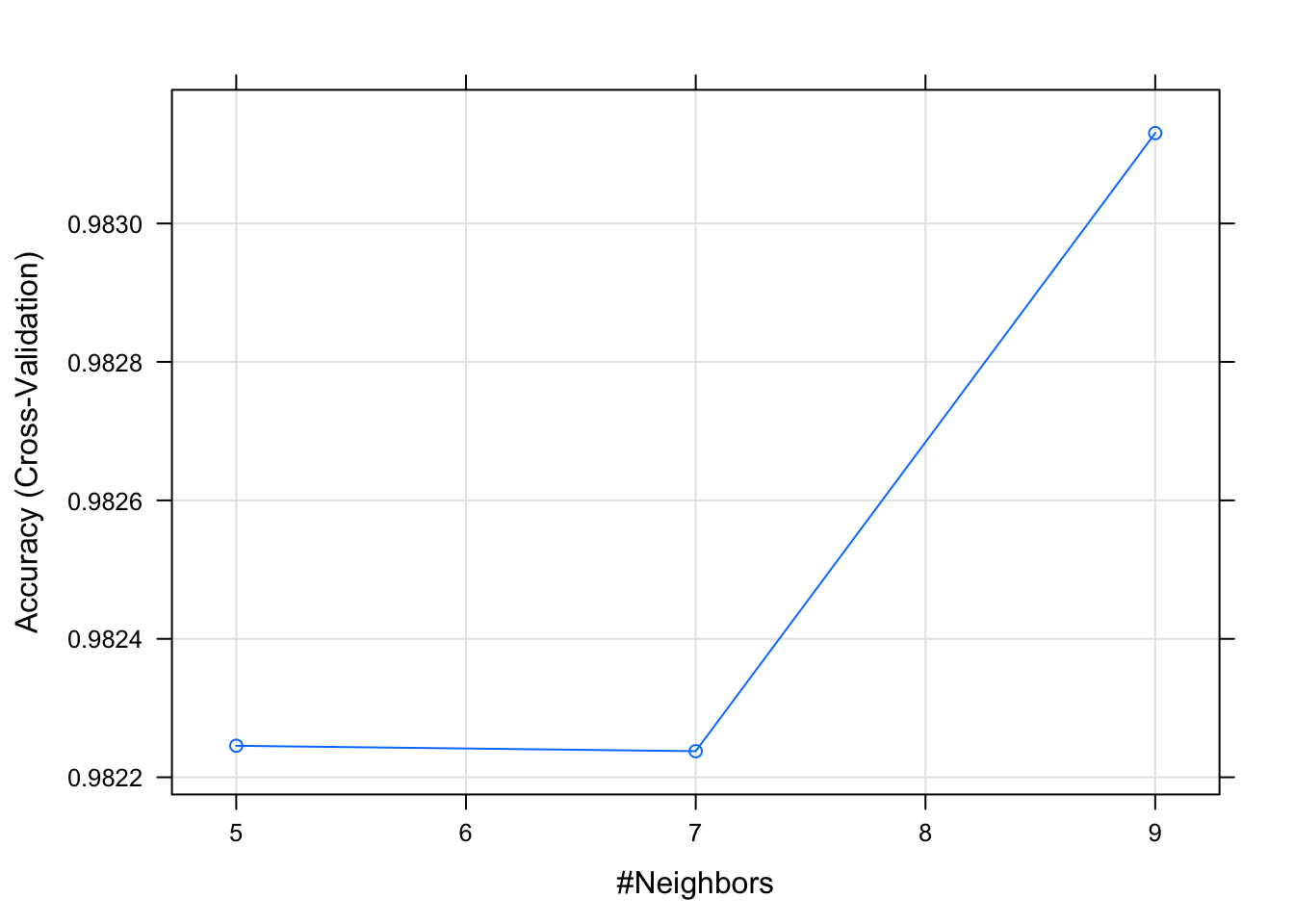
previsao = predict(book_knn, test)
confusionMatrix(previsao, factor(test$book))## Confusion Matrix and Statistics
##
## Reference
## Prediction arg br
## arg 105 8
## br 5 371
##
## Accuracy : 0.9734
## 95% CI : (0.955, 0.9858)
## No Information Rate : 0.7751
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.9245
##
## Mcnemar's Test P-Value : 0.5791
##
## Sensitivity : 0.9545
## Specificity : 0.9789
## Pos Pred Value : 0.9292
## Neg Pred Value : 0.9867
## Prevalence : 0.2249
## Detection Rate : 0.2147
## Detection Prevalence : 0.2311
## Balanced Accuracy : 0.9667
##
## 'Positive' Class : arg
## df = cbind(fit = if_else(previsao=="br",1,0), class = if_else(test$book=="br",1,0)) %>% as.data.frame()
plot_pred_type_distribution(df,0.5)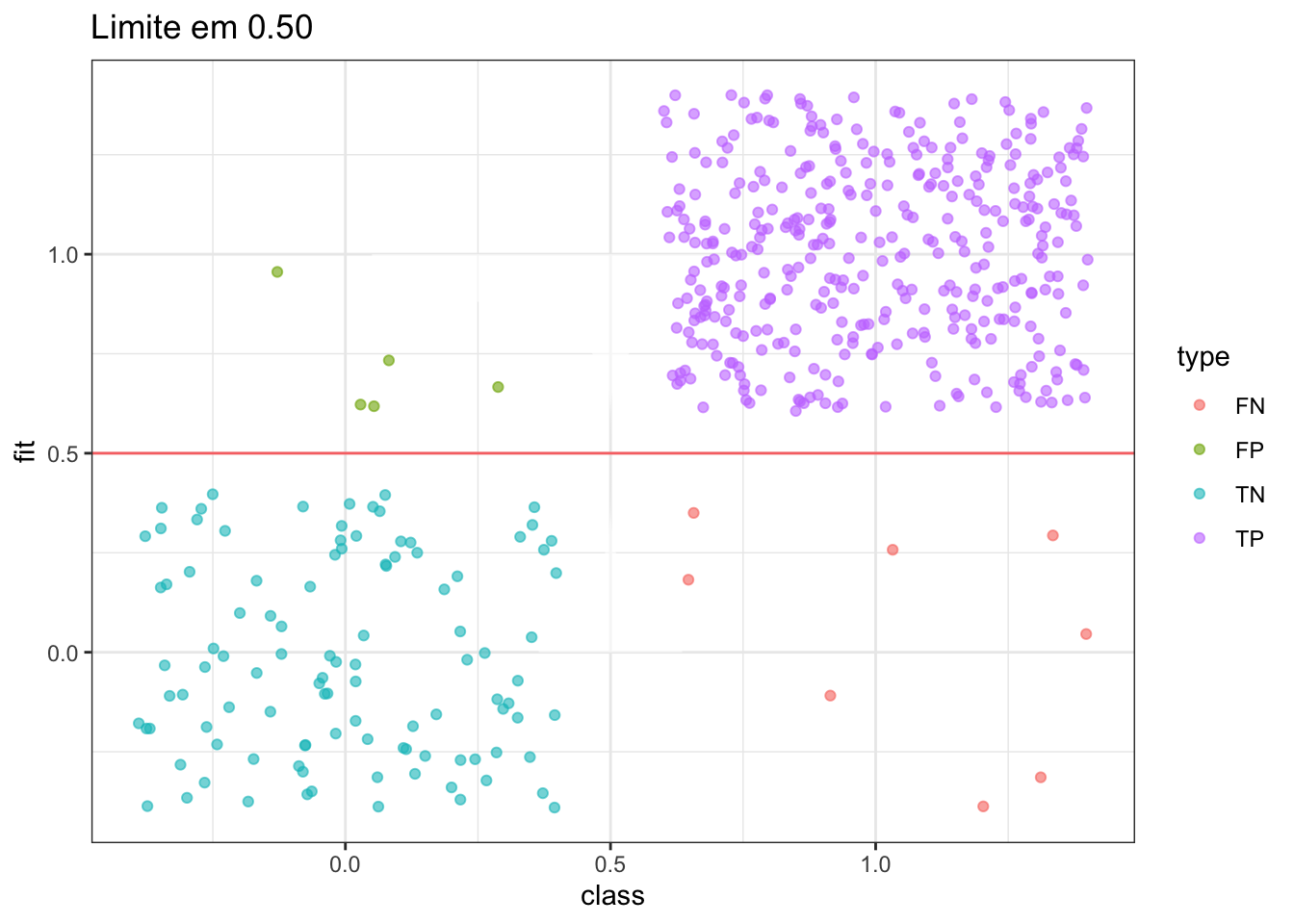
Como podemos ver, segundo a validação cruzada realizada com o pacote caret, o número 5 de vizinhos mais próximos foi o que apresentou o melhor resultado. Além disso o modelo apresentou uma acurácia de 97,18% e isto parece bom dado que a sensibilidade (taxa de verdadeiros positivos) e a especificidade (taxa de verdadeiros negativos) foram altas também, o que foi reforçado com o gráfico ilustrado da matriz de confusão.
O tempo computacional para o ajuste do modelo foi de:2.46385908126831 segundos
Random Forest
O modelo de Random Forest tem se tornado muito popular devido ao seu bom desempenho e pela sua alta capacidade de se adaptar aos dados. O modelo funciona através da combinação de várias árvores de decisões e no seu ajuste alguns parâmetros precisam ser levados em conta.
O parâmetro que sera levado em conta para o ajuste será apenas o ntree, que representa o número de árvores ajustadas. Este parâmetro deve ser escolhido com cuidado pois pode ser tão grande quanto você quiser e continua aumentando a precisão até certo ponto porém pode ser mais limitado pelo tempo computacional disponível.
set.seed(824)
# Random Forest
antes = Sys.time()
book_rf <- train(book ~.,
data=train,
method = "rf",trace=F,
ntree = 200,
trControl = trainControl(method = "cv",number = 10))
time_rf <- Sys.time() - antes
Sys.time() - antes## Time difference of 8.994044 secslibrary(randomForest)
varImpPlot(book_rf$finalModel)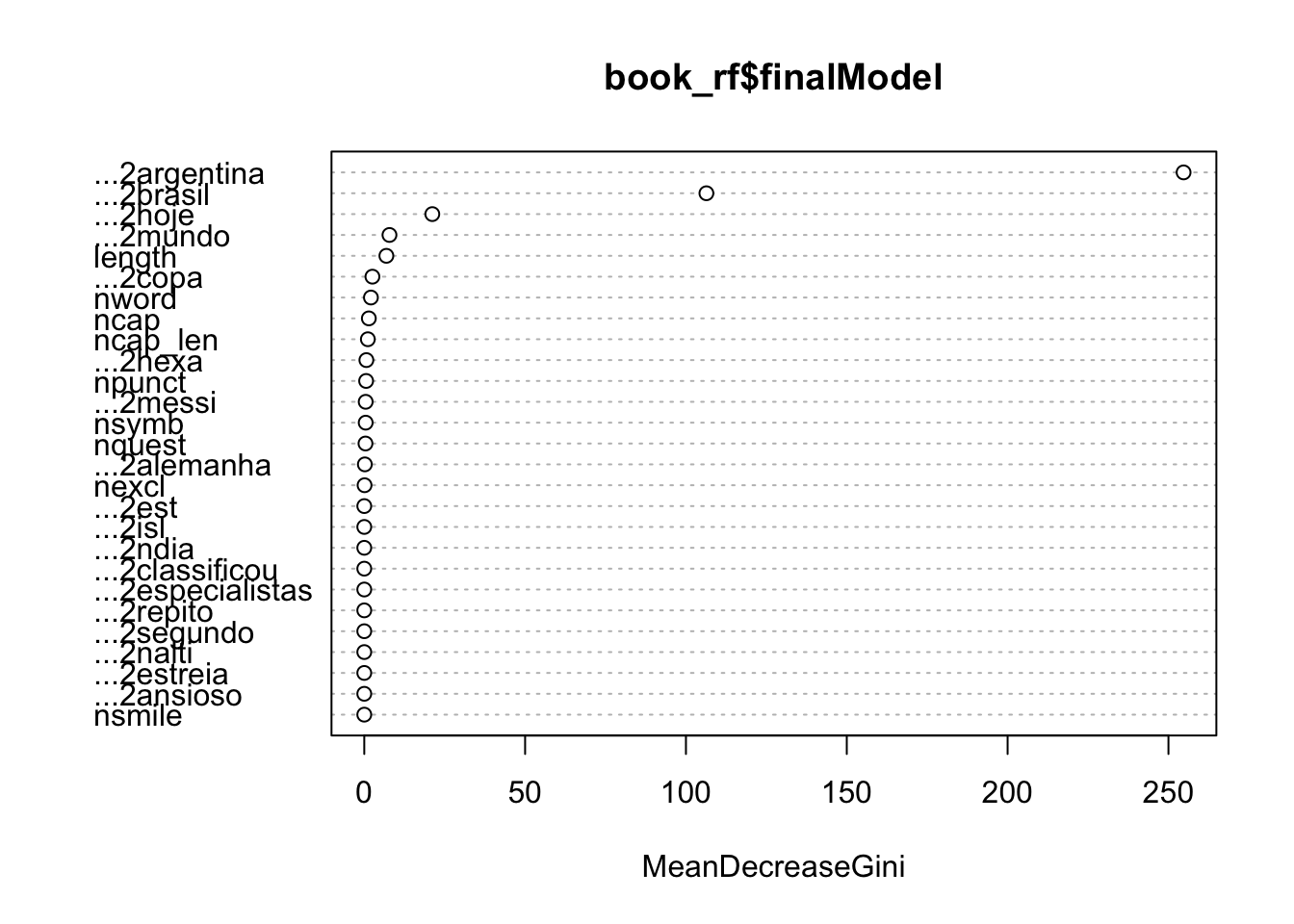
previsao = predict(book_rf, test)
confusionMatrix(previsao, factor(test$book))## Confusion Matrix and Statistics
##
## Reference
## Prediction arg br
## arg 110 0
## br 0 379
##
## Accuracy : 1
## 95% CI : (0.9925, 1)
## No Information Rate : 0.7751
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
##
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.2249
## Detection Rate : 0.2249
## Detection Prevalence : 0.2249
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : arg
## # https://www.r-bloggers.com/illustrated-guide-to-roc-and-auc/
df = cbind(fit = if_else(previsao=="br",1,0), class = if_else(test$book=="br",1,0)) %>% as.data.frame()
plot_pred_type_distribution(df,0.5)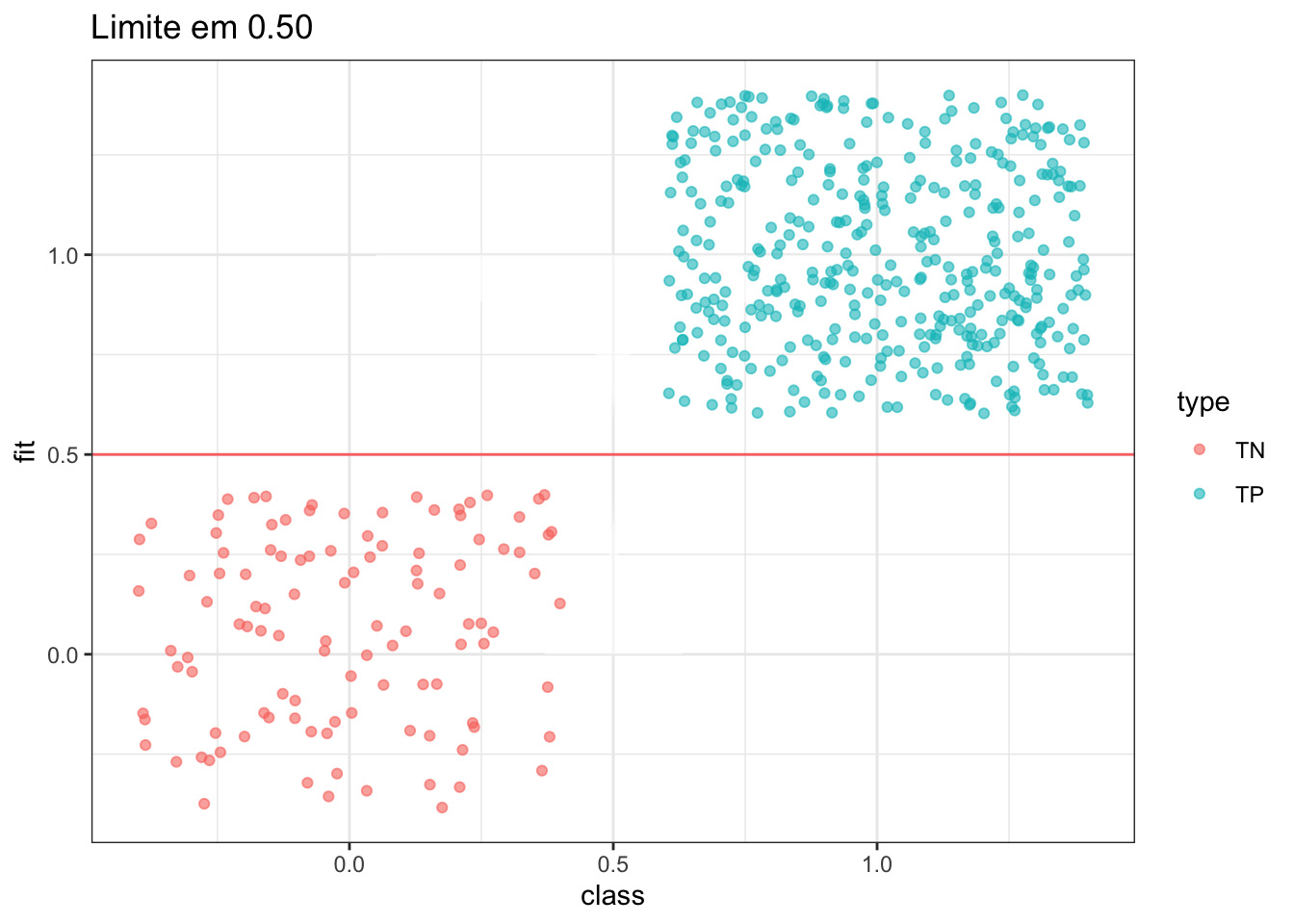
Segundo o gráfico de importância, parece que as palavras “brasil,” “argentina,” “copa” e “messi” foram as que apresentaram maior impacto do preditor (lembrando que essa medida não é um efeito específico), o que mostra que a presença das palavras que estamos utilizando para classificar tiveram um impacto na classificação bastante superior aos demais.
Quanto a acurácia, o random forest apresentou valor um pouco maior do que o do algorítimo K-NN e além disso apresentou altos valores para a sensibilidade (taxa de verdadeiros positivos) e a especificidade (taxa de verdadeiros negativos), o que foi reforçado com o gráfico ilustrado da matriz de confusão, porém o tempo computacional utilizado para ajustar este modelo foi muito maior, o que leva a questionar se esse pequeno aumento na taxa de acerto vale a pena aumentando tanto no tempo de processamento (outra alternativa seria diminuir o tamanho do número de árvores para ver se melhoraria na qualidade do ajuste).
O tempo computacional para o ajuste do modelo foi de: 8.99299788475037 segundos
Naive Bayes
Este é um algorítimo que trata-se de um classificador estatístico baseado no Teorema de Bayes e recebe o nome de ingênuo (naive) porque pressupõe que o valor de um atributo que exerce algum efeito sobre a distribuição da variável resposta é independente do efeito que outros atributos.
O cálculo para a classificação é feito por meio do cálculo de probabilidades condicionais, ou seja, probabilidade de uma observação pertencer a cada classe dado os exemplares existentes no conjunto de dados usado para o treinamento.
# Naive Bayes ----
set.seed(825)
antes = Sys.time()
book_nb <- train(book ~.,
data=train,
method= "nb",
laplace =1,
trControl = trainControl(method = "cv",number = 10))
time_nb <- Sys.time() - antes
Sys.time() - antes## Time difference of 7.141471 secsprevisao = predict(book_nb, test)
confusionMatrix(previsao, factor(test$book))## Confusion Matrix and Statistics
##
## Reference
## Prediction arg br
## arg 108 6
## br 2 373
##
## Accuracy : 0.9836
## 95% CI : (0.968, 0.9929)
## No Information Rate : 0.7751
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.9537
##
## Mcnemar's Test P-Value : 0.2888
##
## Sensitivity : 0.9818
## Specificity : 0.9842
## Pos Pred Value : 0.9474
## Neg Pred Value : 0.9947
## Prevalence : 0.2249
## Detection Rate : 0.2209
## Detection Prevalence : 0.2331
## Balanced Accuracy : 0.9830
##
## 'Positive' Class : arg
## # https://www.r-bloggers.com/illustrated-guide-to-roc-and-auc/
df = cbind(fit = if_else(previsao=="br",1,0), class = if_else(test$book=="br",1,0)) %>% as.data.frame()
plot_pred_type_distribution(df,0.5)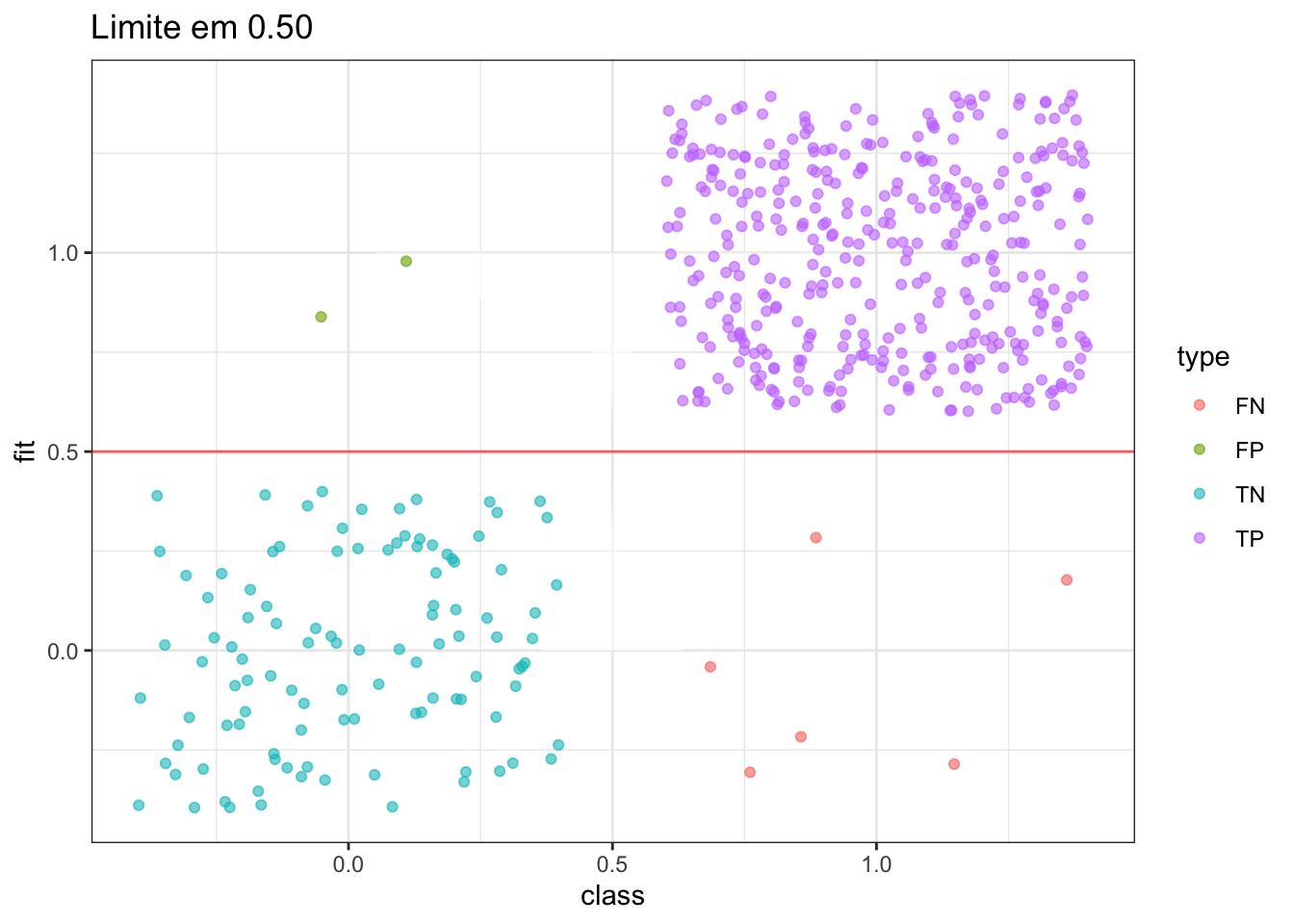
Apesar a aparente acurácia alta, o valor calculado para a especificidade (verdadeiros negativos) foi elevado o que aponta que o ajuste do modelo não se apresentou de forma eficiente
O tempo computacional foi de 7.1403751373291 segundos
GLM - Logit
Este é um modelo estatístico que já abordei aqui no blog no post sobre AED de forma rápida e um pouco de machine learning e seguindo a recomendação do artigo da datacamp vejamos quais resultados obtemos com o ajuste deste modelo:
# Modelo logístico ----
set.seed(825)
antes = Sys.time()
book_glm <- train(book ~.,
data=train,
method = "glm", # modelo generalizado
family = binomial(link = 'logit'), # Familia Binomial ligacao logit
trControl = trainControl(method = "cv", number = 10)) # validacao cruzada
time_glm <- Sys.time() - antes
Sys.time() - antes## Time difference of 1.378149 secslibrary(ggfortify)
autoplot(book_glm$finalModel, which = 1:6, data = train,
colour = 'book', label.size = 3,
ncol = 3) + theme_classic()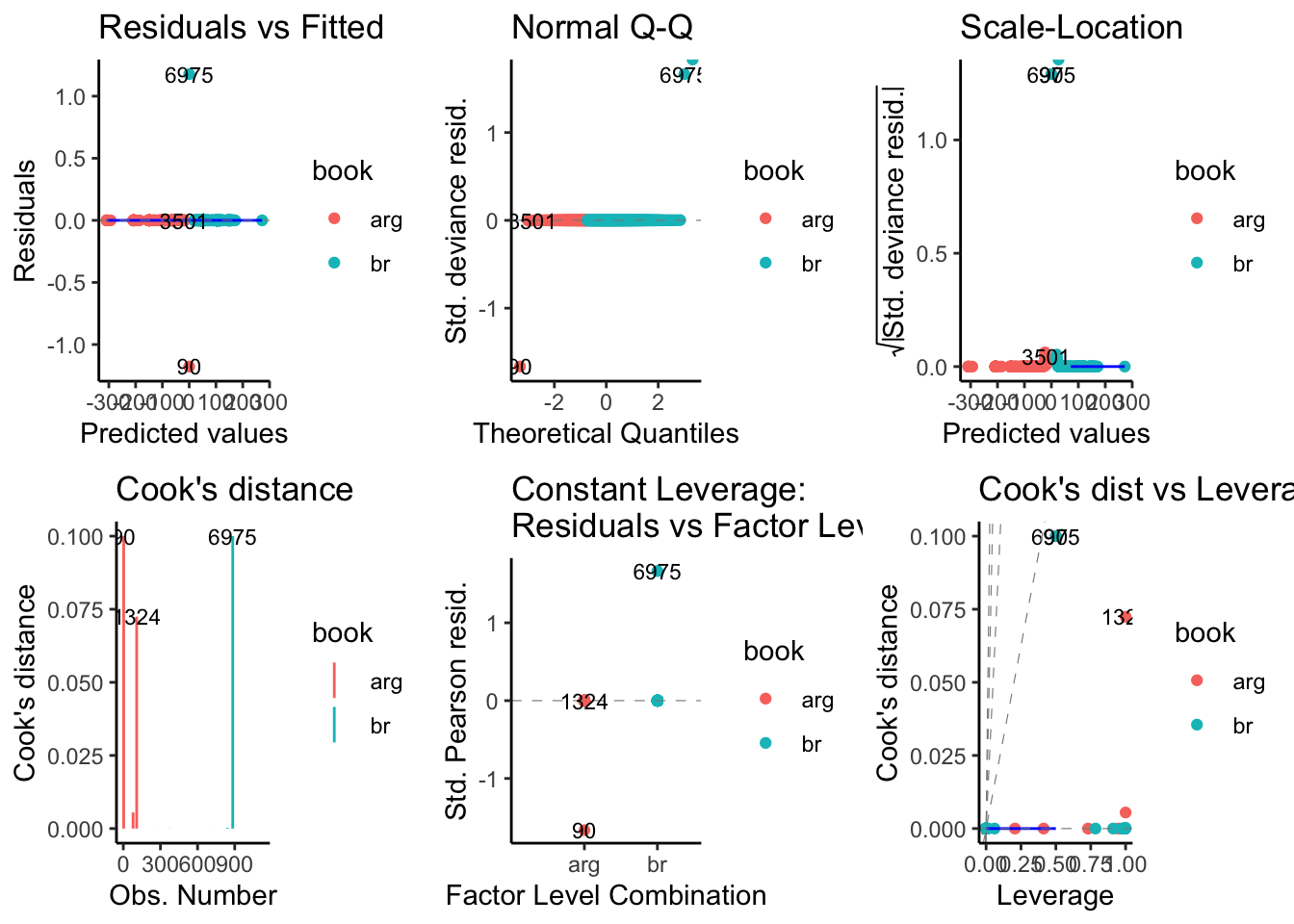
previsao = predict(book_glm, test)
confusionMatrix(previsao, factor(test$book))## Confusion Matrix and Statistics
##
## Reference
## Prediction arg br
## arg 109 0
## br 1 379
##
## Accuracy : 0.998
## 95% CI : (0.9887, 0.9999)
## No Information Rate : 0.7751
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.9941
##
## Mcnemar's Test P-Value : 1
##
## Sensitivity : 0.9909
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 0.9974
## Prevalence : 0.2249
## Detection Rate : 0.2229
## Detection Prevalence : 0.2229
## Balanced Accuracy : 0.9955
##
## 'Positive' Class : arg
## df = cbind(fit = if_else(previsao=="br",1,0), class = if_else(test$book=="br",1,0)) %>% as.data.frame()
plot_pred_type_distribution(df,0.5)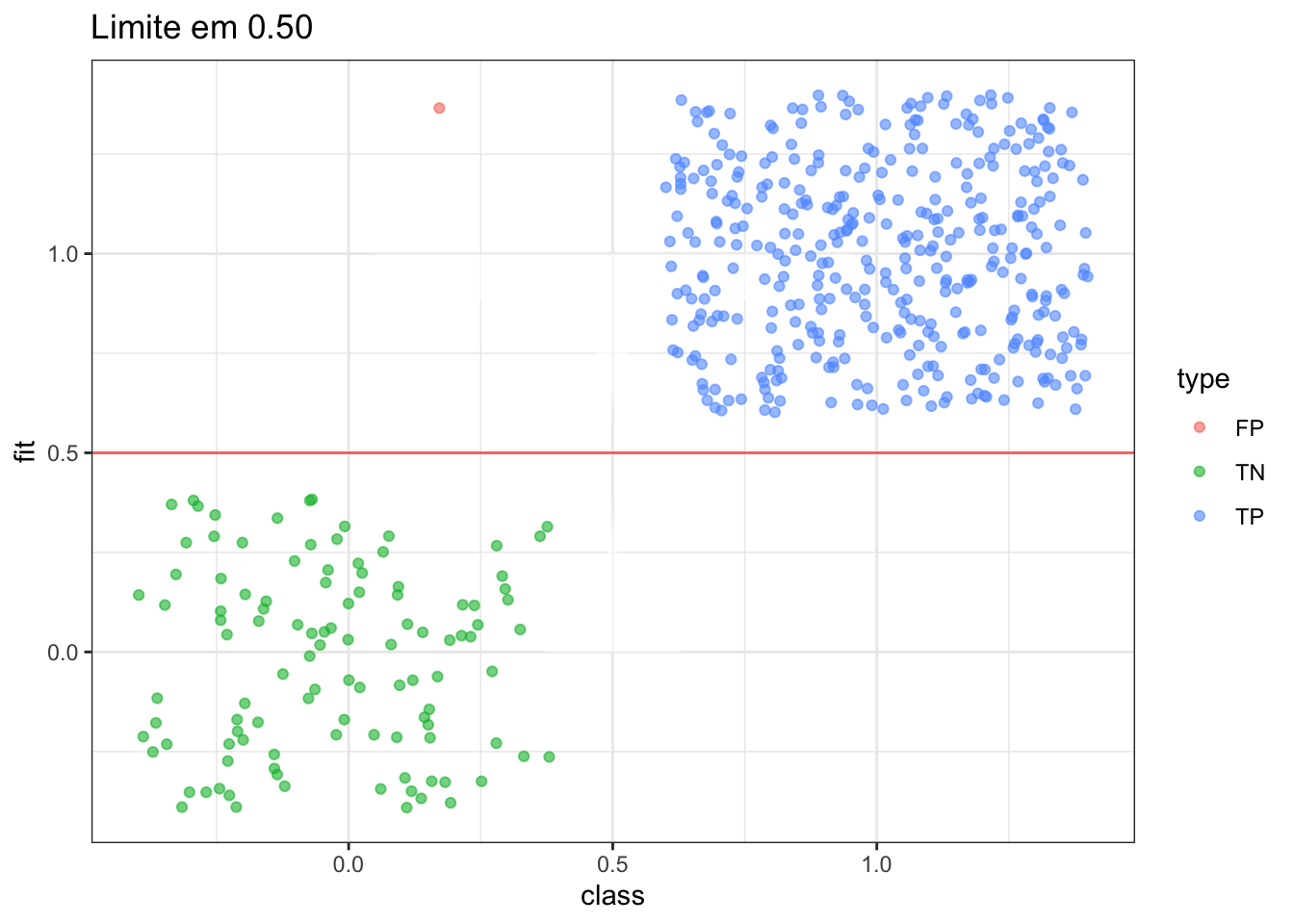
Comparando modelos
Agora que temos 4 modelos ajustados e cada um apresentando resultados diferentes, vejamos qual deles seria o mais interessante para caso fosse necessário recuperar a classificação dos termos pesquisados através da API, veja a seguir um resumo das medidas obtidas:
# "Dados esses modelos, podemos fazer declarações estatísticas sobre suas diferenças de desempenho? Para fazer isso, primeiro coletamos os resultados de reamostragem usando resamples." - caret
resamps <- resamples(list(knn = book_knn,
rf = book_rf,
nb = book_nb,
glm = book_glm))
summary(resamps)##
## Call:
## summary.resamples(object = resamps)
##
## Models: knn, rf, nb, glm
## Number of resamples: 10
##
## Accuracy
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## knn 0.9553571 0.9821824 0.9823009 0.9831305 0.9889381 1 0
## rf 0.9823009 1.0000000 1.0000000 0.9973451 1.0000000 1 0
## nb 0.9107143 0.9623894 0.9823009 0.9768726 1.0000000 1 0
## glm 0.9910714 0.9911504 1.0000000 0.9964523 1.0000000 1 0
##
## Kappa
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## knn 0.8730734 0.9500663 0.9512773 0.9530901 0.9691458 1 0
## rf 0.9513351 1.0000000 1.0000000 0.9926689 1.0000000 1 0
## nb 0.7791798 0.8998204 0.9525409 0.9398109 1.0000000 1 0
## glm 0.9752868 0.9753544 1.0000000 0.9901350 1.0000000 1 0Como podemos ver, o modelo que apresentou a menor acurácia e o menor coeficiente kappa foi o Naive Bayes enquanto que o que apresentou as maiores medidas de qualidade do ajuste foi o modelo ajustado com o algorítimo Random Forest e tanto o modelo ajustado pelo algorítimo knn quanto o modelo linear generalizado com função de ligação “logit” também apresentaram acurácia e coeficiente kappa próximos do apresentado no ajuste do Random Forest.
Portanto, apesar dos ajustes, caso dois modelos não apresentem diferença estatisticamente significante e o tempo computacional gasto para o ajuste de ambos for muito diferente pode ser que ser que tenhamos um modelo candidato para:
c( knn= time_knn,rf = time_rf,nb = time_nb,glm = time_glm)## Time differences in secs
## knn rf nb glm
## 2.463859 8.992998 7.140375 1.377073O modelo linear generalizado foi o que apresentou o menor tempo computacional e foi o que apresentou o terceiro maior registro para os as medidas de qualidade do ajuste dos modelos, portanto esse modelo será avaliado com mais cuidado em seguida para saber se ele será o modelo selecionado
Obs.: Sou suspeito para falar mas dentre esses modelos eu teria preferência por este modelo de qualquer maneira por não se tratar de uma “caixa preta,” da qual todos os efeitos de cada parâmetro ajustado podem ser interpretado, além de obter medidas como razões de chance que ajudam bastante na compreensão dos dados.
Comparando de forma visual:
splom(resamps)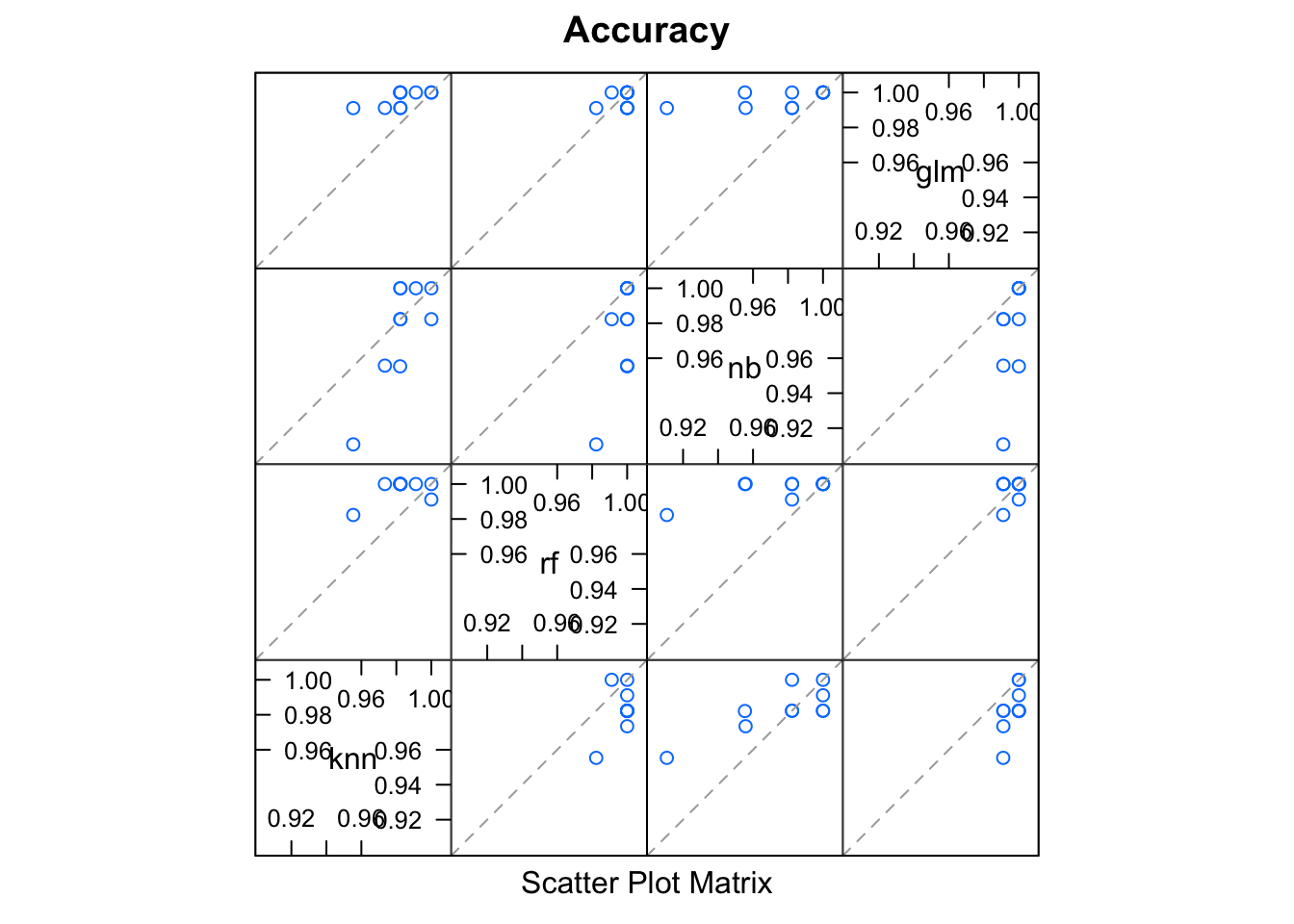
Assim fica mais claro o como o ajuste dos modelos Random Forest, K-NN e GLM se destacaram quando avaliados em relação a acurácia apresentada.
Vejamos a seguir como foi a distribuição dessas medidas de acordo com cada modelo através de boxplots:
bwplot(resamps)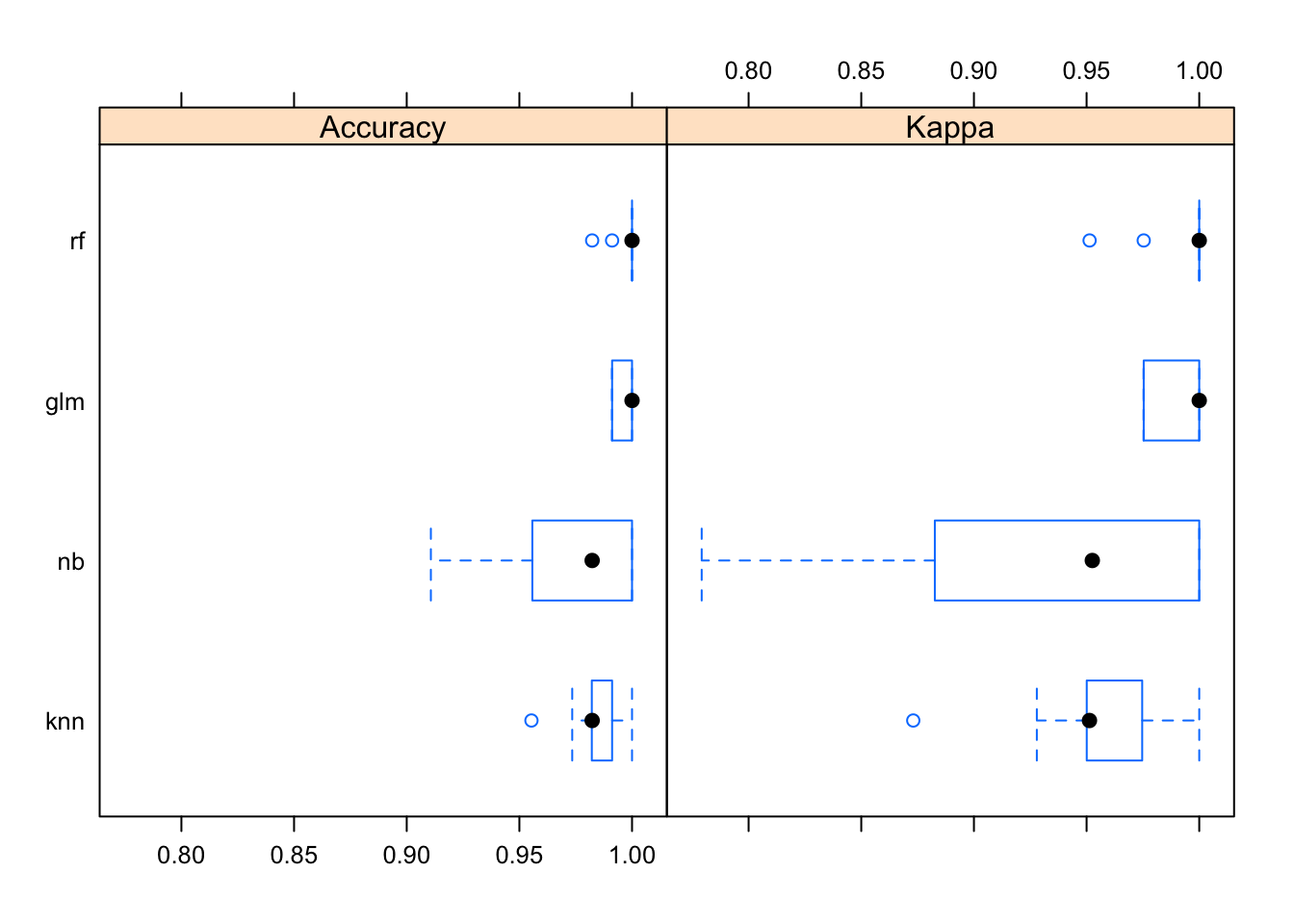
Note que além de apresentar os ajustes com menor acurácia (e elevada taxa de falsos negativos) o algorítimo Naive Bayes foi o que apresentou a maior variação interquartil das medidas de qualidade do ajuste do modelo.
Para finalizar a análise visual vamos obter as diferenças entre os modelos com a função diff() e em seguida conferir de maneira visual o comportamento dessas informações:
difValues <- diff(resamps)
# plot:
bwplot(difValues)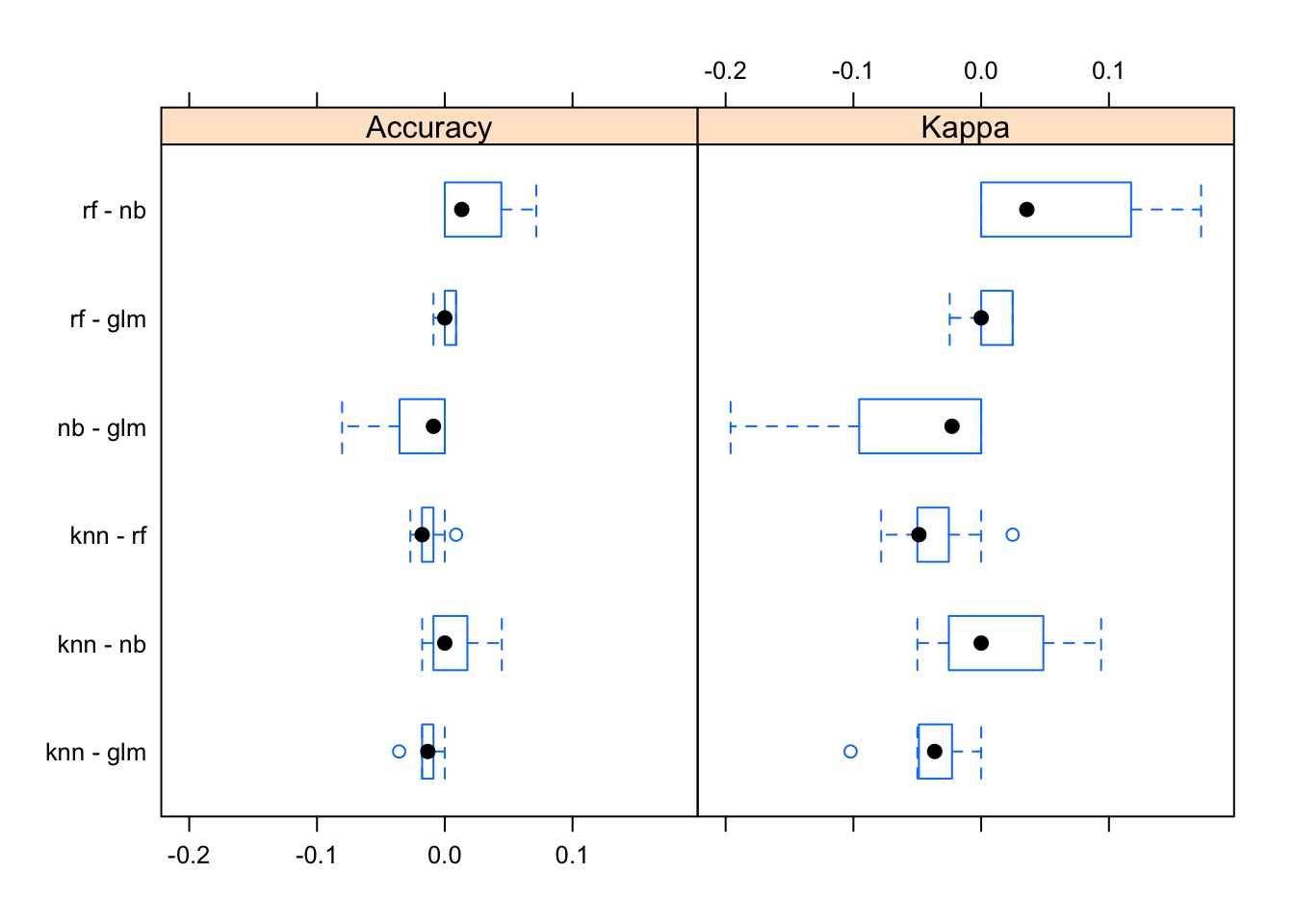
Observe que tanto o modelo logístico quando o ajuste com o algorítimo K-NN apresentaram valores muito próximos dos valores do ajuste do Random Forest e como já vimos o Random Forest foi o modelo que levou maior tempo computacional para ser ajustado, portanto vamos conferir a seguir se existe diferença estatisticamente significante entre os valores obtidos através de cada um dos ajustes e decidir qual dos modelos se apresentou de maneira mais adequada para nosso caso:
resamps$values %>%
select_if(is.numeric) %>%
purrr::map(function(x) shapiro.test(x))## $`knn~Accuracy`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.87602, p-value = 0.1174
##
##
## $`knn~Kappa`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.87418, p-value = 0.1118
##
##
## $`rf~Accuracy`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.53165, p-value = 8.564e-06
##
##
## $`rf~Kappa`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.53234, p-value = 8.727e-06
##
##
## $`nb~Accuracy`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.80077, p-value = 0.01482
##
##
## $`nb~Kappa`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.81793, p-value = 0.02392
##
##
## $`glm~Accuracy`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.6429, p-value = 0.0001803
##
##
## $`glm~Kappa`
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.64123, p-value = 0.0001722Como a hipótese de normalidade não foi rejeitada para nenhuma das amostras de acurácias registradas, vejamos se existe diferença estatisticamente significante entre as médias dessas medidas de qualidade para cada modelo:
t.test(resamps$values$`rf~Accuracy`,resamps$values$`knn~Accuracy`, paired = T) ##
## Paired t-test
##
## data: resamps$values$`rf~Accuracy` and resamps$values$`knn~Accuracy`
## t = 3.9961, df = 9, p-value = 0.003129
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.0061678 0.0222614
## sample estimates:
## mean of the differences
## 0.0142146Rejeita a hipótese de que as médias das acurácias calculadas para o ajuste do algorítimo Random Forest e K-NN foram iguais
t.test(resamps$values$`rf~Accuracy`,resamps$values$`glm~Accuracy`, paired = T) ##
## Paired t-test
##
## data: resamps$values$`rf~Accuracy` and resamps$values$`glm~Accuracy`
## t = 0.43326, df = 9, p-value = 0.675
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.003768926 0.005554640
## sample estimates:
## mean of the differences
## 0.0008928571Novamente, rejeita-se a hipótese de que as médias das acurácias calculadas para o ajuste do algorítimo Random Forest e do modelo de logístico foram iguais
t.test(resamps$values$`knn~Accuracy`,resamps$values$`glm~Accuracy`, paired = T)##
## Paired t-test
##
## data: resamps$values$`knn~Accuracy` and resamps$values$`glm~Accuracy`
## t = -4.0077, df = 9, p-value = 0.003074
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.020841197 -0.005802292
## sample estimates:
## mean of the differences
## -0.01332174Já para a comparação entre as médias das acurácias calculadas para o algorítimo K-NN e para o modelo logístico não houve evidências estatísticas para se rejeitas a hipótese de que ambas as médias são iguais, o que nos sugere o modelo logístico como o segundo melhor candidato como modelo de classificação para este problema com estes dados.
Então a escolha ficará a critério do que é mais importante. Caso o tempo computacional fosse uma medida que tivesse mais importância do que a pequena superioridade de acurácia apresentada pelo algorítimo Random Forest, escolheria o modelo logístico, porém como neste caso os 7.61592507362366 segundos a mais para ajustar o modelo não fazem diferença para mim, fico com o modelo Random Forest.
Este post trás alguns dos conceitos que venho estudado e existem muitos tópicos apresentados aqui que podem (e devem) ser estudados com mais profundidade, espero que tenha gostado!
Referências
obs.: links mensionados no corpo do texto


Share this post
Twitter
LinkedIn
Email