Série: LangChain — Agentes com Python — ver índice
Análise de Sentimentos com Llama2 Detecção de Linguagem Tóxica com Gemma Equipe Multiagente para Bitcoin Agente para Ligações de Telemarketing → LLM Local com Qwen sem APIs Por que rodar LLMs localmente? Nos últimos anos, o mundo dos modelos de linguagem de grande porte (LLMs) deixou de ser um território exclusivo das gigantes americanas. Uma leva de modelos open-weight de origem chinesa como o Qwen (Alibaba), o DeepSeek e o Yi chegaram com qualidade surpreendente e, mais importante, com pesos disponíveis publicamente. Li sobre alguns deles em um post que apareceu no meu LinkedIn e fiquei curioso para testar: será que dá para rodar um desses modelos localmente no meu Mac e ainda plugar ele num agente LangChain funcional?
Série: LangChain — Agentes com Python — ver índice
Análise de Sentimentos com Llama2 Detecção de Linguagem Tóxica com Gemma → Equipe Multiagente para Bitcoin Agente para Ligações de Telemarketing LLM Local com Qwen sem APIs Por que Analisar o Mercado Bitcoin com Agentes de IA? O cenário do bitcoin sempre foi meio intrigante. Foi lançado há 16 anos mas até hoje ninguém sabe ao certo quem está por trás do projeto — o criador, conhecido apenas pelo pseudônimo Satoshi Nakamoto, nunca revelou sua identidade. Além disso o bitcoin foi a primeira e ainda é a mais conhecida aplicação da tecnologia Blockchain, que revolucionou a forma como lidamos com registros digitais e segurança dos dados. Sua natureza descentralizada e sua notória volatilidade o tornam um ativo único.
Introdução Definição do problema de negócio Soluções Estratégia analítica Decisões sobre a target Processamento dos Dados Dados Externos Feature Engineering Modelos Ensemble Post Processing Considerações Finais Introdução O TFUG - TensorFlow Users Group de São Paulo lançou uma nova competição no Kaggle onde o objetivo era desenvolver modelos para previsão de diagnóstico de síndromes respiratórias, que é um tema relacionado com um dos 17 tópicos de Desenvolvimento Sustentável das Nações Unidas - Boa saúde e bem-estar.
Introdução DALL·E 2 Instruções de Uso Parâmetros Exemplos DALL·E Mini e Stable Diffusion Exemplos Opções Alternativas VQGAN+CLIP Mais Parâmetros Mais Exemplos Discussão Filosófica Conclusão Referências Introdução Você já deve ter ouvido falar sobre uma inteligência artificial que gera artes super-realistas a partir de textos e imagens. Hoje em dia já existem algumas opções como DALL·E 2 (da OpenAI/Google) e a Make-A-Scene (da Meta), e essas ferramentas são capazes de gerar versões e estilos diferentes de uma dada imagem ou ainda criar uma imagem com apenas uma breve descrição do resultado desejado. As imagens podem ser tão aleatórias quanto um “gato de óculos e uma coroa” (em homenagem ao dia dos gatos):
Introdução Definição do problema de negócio Análise Exploratória (em R) Estrutura da base Ano da base de dados Target Machine Learning (em Python) Importar dependencias Carregar dados Modelagem Submissão Considerações Finais Introdução No final de Janeiro desde ano (2022) o TFUG - TensorFlow Users Group de São Paulo lançou uma competição no Kaggle para prever as notas do enem que tem relação com um dos 17 tópicos de Desenvolvimento Sustentável das Nações Unidas - Educação de Qualidade.
Introdução Definição do problema de negócio Análise Exploratória (em R) Machine Learning (em Python) Importar dependências Stage 0: Feature Extraction com KNN Stage 1: Tuning XGBoost com Optuna Stage 2: Calcular Out-Of-Fold SHAP values Stage 3: Modelo Final com AutoGluon Conclusão Referências Introdução Em Agosto e 2021 a Porto Seguro lançou um desafio no Kaggle que consistia em estimar a propensão de aquisição de novos produtos. Tratava-se de um problema de classificação e foi bem desafiador principalmente por 2 motivos:
O problema envolvendo dados desbalanceados Objetivo Dependências Preparar dados Breve análise exploratória Modelagem Baselines Preparar Pipeline de dados com workflowsets Benchmark Conclusão Referências O problema envolvendo dados desbalanceados A tarefa de classificação com dados desbalanceados é muito comum na vida real podendo variar desde um leve viés até um enorme desequilíbrio na distribuição da classe de interesse. Problemas mais comuns envolvem:
Ciência de dados é a área que combina programação, matemática, estatística e conhecimento de contexto para extrair soluções escondidas em grandes massas de dados desorganizados. Com a quantidade de dados produzida a cada instante e o poder computacional cada vez mais barato, ela ganhou um espaço enorme no mercado. Para ter ideia da escala, projeta-se que, até 2025, o mundo gere cerca de 175 zettabytes de dados por ano (IDC, Data Age 2025).
Qualidade de sono? 🤨 Como funciona aplicativo Sleep Cycle? Objetivo 🎯 Explorar dados 🔎 Limpeza e preparação dos dados Imputar dados de fontes externas Insights Reter dados Modelagem 🚀 Amostragem Engenharia de recursos Modelo Nulo (Baseline) Árvore de decisões Random Forest LightGBM Seleção do modelo 🤔 Previsão em dados novos 💫 Conclusão 🍻 Referências 🧳 Qualidade de sono? 🤨 Sim, exatamente! Neste post analisaremos dados de um tracking que venho fazendo desde 2017 com informações relacionadas à um sono de qualidade.
Problema de negócio Uma tarefa comum no dia a dia de um estatístico (ou cientista de dados) é a elaboração de relatórios para passar ao restante da equipe e/ou tomadores de decisão os resultados encontrados e muitas vezes essa tarefa pode parecer desgastante quando os relatórios são muitos extensos e repetitivos.
Com a linguagem R, escrever relatórios estatísticos utilizando RMarkdown acaba sendo a escolha padrão por ser tão simples transformar as análises em documentos, apresentações e dashboards de alta qualidade com poucas linhas de código.
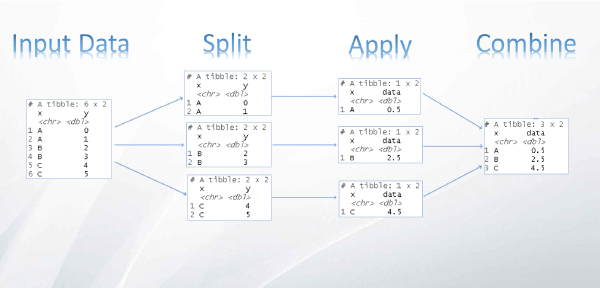
O método split-apply-combine Geralmente em uma análise de dados precisamos compreender, além do comportamento geral dos dados, o seu comportamento de acordo com alguns segmentos.
No famoso paper The Split-Apply-Combine Strategy for Data Analysis, Hadley Wickham descreve a abordagem “split-apply-combine” (dividir-aplicar-combinar) como uma das mais comuns em uma análise de dados. Em R essa tarefa pode ser feita por diversos caminhos, veja alguns dos modos de se fazer utilizando funções base do R e abordagens mais antigas:
Até que um dia.. Agora em dezembro encerro um desafio pessoal de fazer pelo menos um post por mês durante o ano de 2018 e estou muito animado com o término deste ciclo! Espero ter contribuído um pouquinho com a comunidade de Estatística e Ciência de Dados que está maior a cada dia e cada vez mais importante.
Análise de sobrevivência e PUBG Análise de sobrevivência é um termo que se refere a situações médicas e é caracterizada pela sua variável resposta, que pode ser apresentada de três formas: probabilidade de sobrevivência, taxa de incidêcia e taxa de incidência acumulada.
Na engenharia este termo também é conhecido como confiabilidade, no entanto, condições parecidas podem ocorrer em (inusitadas) outras áreas.
PUBG é um jogo online multiplayer de batalha em que 100 jogadores são lançados em uma ilha e tem como objetivo principal sobreviver, a área de jogo diminui progressivamente, confinando os sobreviventes a um espaço cada vez menor e forçando encontros e o vencedor é o último jogador (ou time) a permanecer vivo.
⚠️ Nota de atualização (2026): Este post usa Ubuntu 16.04 LTS (EOL desde 2021), RStudio Server (renomeado para Posit Workbench) e Shiny Server na instância f1-micro do Google Cloud. Os passos gerais ainda funcionam, mas o Ubuntu mínimo recomendado hoje é o 22.04 LTS e os pacotes de instalação do RStudio/Posit mudaram de URL. Para instâncias novas, consulte a documentação atual do Posit Workbench.
Objetivo do post Uma das várias maneiras de se implementar o RStudio Server e o Shiny Server é através de serviços de nuvem que fornecem máquinas virtuais. Empresas gigantes no mercado como Amazon Web Services (AWS), Microsoft, Google, IBM, Oracle etc têm investido pesado nestes serviços e a escolha de qual cloud utilizar deve ser feita de acordo com a necessidade do usuário pois cada uma delas oferecem diferentes preços com diferentes custos/benefícios.
Perguntas Estudar em outra cidade têm suas vantagens e desvantagens, durante toda a graduação atravessei Baía de Guanabara pela Ponte Presidente Costa e Silva, (popularmente conhecida como Ponte Rio–Niterói) assim como todas as pessoas que fazem esse trajeto diariamente e diante de tanta beleza natural com a vista panorâmica da Baía como os espetáculos proporcionados pelo pôr do sol, os pássaros ou a beleza inegável do Pão de Açúcar também é notável a beleza fruto da maior habilidade humana: a criatividade. Temos o cristo, todos aqueles grandes barcos, o Porto do Rio de Janeiro com todas aquelas obras de Engenharia, ou até mesmo a própria Ponte, que por si só já é intrigante.
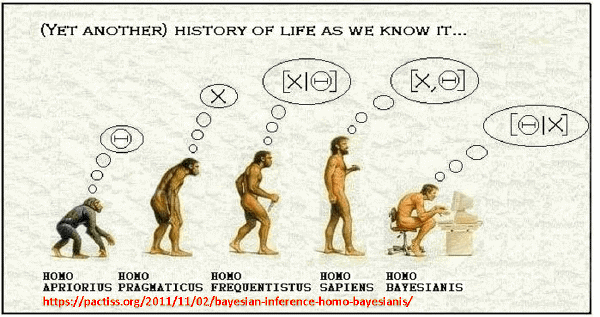
Modelagem estatística e as duas grandes escolas de inferência Através da modelagem estatística é possível tomar decisões sobre diversos assuntos de interesse como por exemplo na análise de risco de crédito, previsões de quantidade de chuva em um dado local, estimativas de erros ou falhas de um novo produto ou serviço além de diversas áreas como na Educação, Economia, nas Ciências Sociais, Saúde etc.
Muitas vezes os parâmetros das distribuições em estudo podem ser desconhecidos e existe o desejo de se inferir sobre eles. Existem duas grandes escolas de inferência: a clássica e a bayesiana. A clássica trata esses parâmetros como quantidades fixas e não atribui distribuição a eles, a estimação desses parâmetros é dada através da função de verossimilhança, enquanto que na escola bayesiana atribui-se uma distribuição, chamada de distribuição a priori, ao conjunto de parâmetros desconhecidos quantificando a sua crença sobre esse conjunto e a estimação dos parâmetros é dada através da distribuição à posteriori, que é proporcional ao produto da função de verossimilhança com a distribuição a priori.
A análise exploratória dos dados A análise exploratória dos dados (AED) foi um termo que ganhou bastante popularidade quando Tukey publicou o livro Exploratory Data Analysis em 1977 que tratava uma “busca por conhecimento antes da análise de dados de fato”. Ocorre quando busca-se obter informações ocultas sobre os dados, tais como: variação, anomalias, distribuição, tendências, padrões e relações
Google Trends O Google Trends é uma ferramenta gratuita, muito poderosa e que pode ser implementada para ajudar em nossas estratégias de análises.
Através dele temos acesso a uma gigantesca base de dados que reúne os temas mais pesquisados na plataforma da Google possibilitando acessar dados de busca desde o ano de 2004.
Através de suas séries temporais podemos avaliar a presença de pedrões, obter noções de tendência, sazonalidade e até mesmo arriscar algumas previsões.
Relatórios de alta qualidade só com \(\LaTeX\)? Como já mencionei no post sobre tabelas incríveis com R, a tarefa de um estatístico (ou Data Scientist, em sua versão diluída e mais comercial) vai muito além do planejamento, análises, inferência, sumarização e interpretação de observações para fornecer a melhor informação possível a partir do dados disponíveis. A produção final dos relatórios é fundamental e na grande maioria das vezes utiliza-se a linguagem \(\LaTeX\), mas será que ela é realmente a única opção?
Você costuma ler o manual? Quando éramos crianças, geralmente não tínhamos o costume de ler o manual das coisas, não é mesmo? Particularmente eu sempre gostei de aprender como as coisas funcionavam diretamente com a prática para poder usá-las depois. Adorava buscar entender como as coisas se encaixavam ao montar os brinquedinhos do kinder-ovo sem ler as instruções ou criar diferentes combinações com lego customizados, por exemplo. Acredito que isso seja da natureza de toda criança!
Onde estão os blocos? Fevereiro começando e o carnaval já está ai, especialmente se você mora no Rio de Janeiro já deve ter passado por algum bloco e a pergunta que todo mundo faz no carnaval pelo menos uma vez é: “Onde tem bloco?”.
TL;DR
Usamos ggmap para geocodificar (transformar endereço em latitude/longitude) os blocos de carnaval. O pacote leaflet (com leaflet.extras) plota tudo num mapa interativo. A limpeza de texto usa a função ajustar_nomes() do post sobre manipulação de strings. Baseado nessa pergunta resolvi fazer esse post especial, vamos utilizar os pacotes ggmap e leaflet para buscar as coordenadas geográficas do endereço dos blocos e representa-los num mapa agradável de navegar
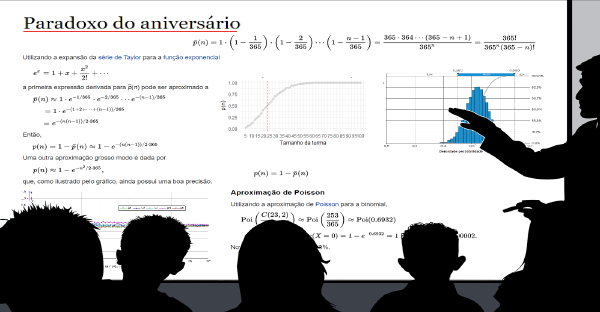
Curiosidades sobre a teoria das probabilidades TL;DR
Num grupo de apenas 23 pessoas, a probabilidade de duas fazerem aniversário no mesmo dia já passa de 50%. O resultado é contraintuitivo; resolvemos de duas formas: analítica (abordagem clássica) e por simulação em R (abordagem frequentista). Uma simulação com 5000 turmas confirma a fórmula teórica. O uso de cálculo de probabilidades para avaliar incertezas já é utilizado a centenas de anos. Foram tantas áreas que se encontraram aplicações (como na medicina, jogos de azar, previsão do tempo…) que hoje não restam dúvidas de que os dados são onipresentes, ainda mais em plena era da informação.
Importância da apresentação dos dados O trabalho de quem analisa dados vai muito além de planejar, resumir e interpretar observações: apresentar bem os resultados é parte essencial de qualquer projeto ou pesquisa. Não é à toa que já existe até uma área dentro da ciência de dados focada nisso, com o título de "Data Artist".
Além dos pacotes que ajudam a apresentar as figuras geradas nas análises (como mostrei nos posts sobre a qualidade do ajuste de modelos e sobre avaliar o ajuste pela abordagem bayesiana), contamos com pacotes que apresentam tabelas de forma elegante e até interativa.
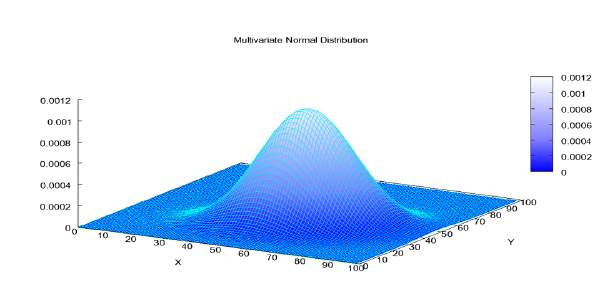
Análise Multivariada Esse é o primeiro post do ano e como no ano de 2017 falou-se tanto das maravilhas computacionais desta onda do Big Data e em contra partida, identificamos que deste 2004 a popularidade pelo termo “estatística” vem diminuindo como mostrei em uma breve pesquisa neste post sobre a API do googletrends sinto que existe uma necessidade de se ampliar também a divulgação dos métodos estatísticos pois o aprofundamento na teoria é fundamental (é muito fácil achar resultados sem fundamento apenas “apertando botão”), como as ferramentas da estatística multivariada que muitas vezes servem como soluções para essas grandes quantidades de dados
Funções do R para avaliar o ajuste de modelos Traduzindo:
“Essencialmente, todos os modelos estão errados, mas alguns são úteis” - George E. P. Box
Se você estuda estatística provavelmente já deve saber quem é este simpático senhor. Box teve grande contribuição para a estatística. Foi aluno do Ronald Aylmer Fisher e ainda se casou com a filha dele!
Lendo um artigo sobre a vida de Fisher um parágrafo me chamou atenção com uma fala de sua filha, que dizia o seguinte:
Inferência bayesiana Imagem da Internet
Quando estamos falando de Inferência nosso objetivo normalmente é tentar verificar alguma informação sobre uma quantidade desconhecida.
TL;DR
Na inferência bayesiana, o parâmetro é tratado como aleatório e sua "crença" é representada por uma distribuição de probabilidade. O pacote R2jags ajusta modelos bayesianos no R chamando o JAGS (amostrador de Gibbs). O mcmcplots e o superdiag diagnosticam a convergência das cadeias MCMC. Para isso devemos utilizar toda informação disponível, seja ela objetiva ou subjetiva (isto é, vinda de umam amostra ou de algum conhecimento préveo ou intuitivo)
O pacote dplyr A análise exploratória dos dados é uma tarefa de bastante relevância para entendermos a natureza dos dados e o tempo de análise é sempre muito precioso. É necessária bastante curiosidade e criatividade para fazer uma boa análise exploratória dos dados pois é difícil receber aqueles dados bonitinhos igual aos nativos do banco de dados do R.
A manipulação de dados é uma das etapas que mais consomem tempo em qualquer projeto, como comento no panorama da ciência de dados que escrevi para quem está começando. Aqui o foco é numa das ferramentas centrais para essa tarefa.
Tipos de relações Vimos no último post sobre tipos de correlações quais tipos de medidas de correlação e associação podem ser calculadas para identificar o grau de associação (ou dependência) entre as variáveis. Um exemplo prático dessas técnicas aplicadas a dados reais pode ser visto na análise do mercado de criptomoedas com R.
Já sabemos que esses coeficientes variam entre 0 e 1 ou entre -1 e +1, de maneira que a proximidade de zero indique a falta de associação entre elas.
Correlações Tipos de Variáveis Tipos de Correlações Coeficiente de Correlação de Pearson Coeficiente de Correlação de Spearman \(\rho\) Coeficiente de Correlação de Kendall (\(\tau\) de kendall) Qui-quadrado de independencia Teste exato de fisher Medidas de associação \(\phi\) (phi) (é o R de pearson quando aplicado a tabelas 2x2) V de Crámer Coeficiente de contingência Kappa Mãos a obra Referências Correlações De maneira geral, quando estamos interessados em avaliar o grau de associação entre duas variáveis calculamos os coeficientes de associação ou correlação entre variáveis.