




































Extração de informações de imagens com IA Generativa
Neste post, exploraremos como utilizar o modelo Llava para gerar rótulos descritivos de imagens, usando dados do conjunto COCO-2017.

Caso de Uso de IA Generativa: Extração de Informações de Imagens com o Modelo Llava
GenAI refere-se a modelos de inteligência artificial capazes de gerar conteúdo novo e criativo a partir de dados de entrada. Seu uso está revolucionando a maneira como processamos dados não estruturados, como imagens, áudios, textos, vídeos, etc. Trabalhar com modelos pré-treinados (i.e., que já foram treinados com grandes conjuntos de dados) e adaptá-los para necessidades específicas tem sido um divisor de águas.
Neste post, vamos explorar a utilização do modelo Llava (Large Language and Vision Assistant) para extrair rótulos descritivos de imagens e também discutir como comparar a qualidade das previsões geradas com métricas específicas para avaliar a performance desse tipo de modelo.
Por que o Modelo Llava?
O modelo Llava é uma alternativa de código aberto ao GPT-4 Vision da OpenAI (que se destaca neste domínio, mas sua aplicação é restrita devido sua natureza proprietária e comercial) que foi treinado em grandes conjuntos de dados multimodais, sendo capaz de compreender e gerar descrições textuais para imagens.
Essa capacidade de “conversar com imagens” tendo o mesmo “poder” de um LLM, possibilita seu uso em muitas soluções desenvolvidas por cientistas de dados no mundo real, como:
- Classificação de produtos em e-commerce: geração de descrições detalhadas de roupas, acessórios, eletrônicos, etc.
- Detecção de defeitos em linhas de produção: identificação de falhas em produtos para automação e controle de qualidade.
- Diagnóstico médico por imagens: auxiliar na detecção precoce de doenças a partir de descrições detalhadas de imagens médicas.
- Reconhecimento de placas de carros: transcrição automática de textos de placas e características de veículos.
- Identificação de sinais de trânsito: aplicação em veículos autônomos para navegação e identificação de sinais.
- Análise de alimentos para calcular nutrição: extração automática de informações nutricionais de fotos ou rótulos de alimentos.
- Identificação de animais em câmeras de vida selvagem: gerar descrições detalhadas de animais detectados, ajudando pesquisadores a automatizar o monitoramento da vida selvagem.
- Detecção de aglomerações em eventos: analisar imagens de câmeras de segurança para identificar a presença de grandes grupos de pessoas em eventos ou lugares públicos, útil em gestão de multidões ou para questões de segurança.
Dataset COCO-2017
O COCO (Common Objects in Context) é um dataset amplamente utilizado em visão computacional. Ele é um dos maiores conjuntos de imagens do dia a dia com objetos em diferentes contextos, com anotações detalhadas fornecidas por humanos como tags, caixa delimitadora, polígono que segmenta a imagem detectando objetos bem como sua descrição. Isso o torna ideal para testar o desempenho desse tipo de modelo para geração de legendas.


Preparando o Ambiente
Utilizei o ambiente do Kaggle para desenvolvimento deste notebook, que disponibiliza a utilização de GPUs. Através do Hardware Accelerator utilizaremos a NVIDIA TESLA P100 GPU.
Expandir código
%%capture
!pip -qqq install bitsandbytes accelerate rouge-score pycocoevalcap bert_score
!pip install -U nltk
import os
import re
import json
import pandas as pd
import numpy as np
from tqdm import tqdm
import seaborn as sns
import matplotlib.pyplot as plt
from PIL import Image
import requests
from io import BytesIO
from IPython.display import HTML
import base64
import torch
from transformers import pipeline, AutoProcessor, BitsAndBytesConfig
from nltk.translate.bleu_score import sentence_bleu
from rouge_score import rouge_scorer
from bert_score import score as bert_score
from nltk.translate.meteor_score import meteor_score
from transformers import logging
import warnings
logging.set_verbosity_error()
warnings.filterwarnings("ignore", "use_inf_as_na")Carregar dados
Por fins de praticidade para este post, selecionei uma amostra de 10 imagens aleatórias do dataset COCO - (Common Objects in Context) no site https://cocodataset.org (onde é possível ter uma descrição detalhada do conjunto de dados, incluindo seu paper para aprofundamento), para avaliar o desempenho do modelo.
Expandir código
df_sample = pd.DataFrame({
'coco_url': [
'http://images.cocodataset.org/train2017/000000058822.jpg',
'http://images.cocodataset.org/train2017/000000530396.jpg',
'http://images.cocodataset.org/train2017/000000097916.jpg',
'http://images.cocodataset.org/train2017/000000418492.jpg',
'http://images.cocodataset.org/train2017/000000022304.jpg',
'http://images.cocodataset.org/train2017/000000295999.jpg',
'http://images.cocodataset.org/train2017/000000406616.jpg',
'http://images.cocodataset.org/train2017/000000370926.jpg',
'http://images.cocodataset.org/train2017/000000005612.jpg',
'http://images.cocodataset.org/train2017/000000146436.jpg'
],
'caption': [
'A laptop sitting on a desk with a cell phone and mouse.',
'A black bear walking through the grass field.',
'a person who is surfing in the ocean.',
'A young boy standing on a sandy beach holding a flag.',
'A man surfing on a wave in the ocean.',
'A herd of cows, grazing in a field.',
'There is a cutting board and knife with chopped apples and carrots.',
'A long yellow school bus is parked on a city street.\n',
'A black and white horse standing in the middle of a field.',
'A man in a red jacket looking at his phone.'
]})
# Função para verificar se o caminho é uma URL
def is_url(path):
return path.startswith('http://') or path.startswith('https://')
# Função simplificada para gerar o thumbnail e convertê-lo em base64 diretamente
def process_image(path):
try:
if is_url(path):
# Se for uma URL, baixar a imagem
response = requests.get(path)
response.raise_for_status() # Verifica se houve algum erro no download
image = Image.open(BytesIO(response.content)) # Abrir a imagem do conteúdo da resposta
else:
# Se for um caminho local, abrir a imagem diretamente
image = Image.open(path)
# Criar uma miniatura da imagem (thumbnail) com tamanho máximo de 150x150
image.thumbnail((150, 150), Image.LANCZOS)
# Salvar a imagem em um buffer de memória e convertê-la para base64
with BytesIO() as buffer:
image.save(buffer, 'jpeg')
image_base64 = base64.b64encode(buffer.getvalue()).decode()
# Retornar a string HTML com a imagem embutida no formato base64
return f'<img src="data:image/jpeg;base64,{image_base64}">'
except Exception as e:
# Em caso de erro, retornar uma string vazia ou uma mensagem de erro
return f"<p>Erro ao carregar imagem: {e}</p>"
# Aplicar o processamento de imagens diretamente no DataFrame
df_sample['image'] = df_sample['coco_url'].map(process_image) # Pode ser URL ou caminho local
# Exibir as legendas e imagens formatadas em HTML
HTML(df_sample[['image', 'coco_url', 'caption']].head().to_html(escape=False))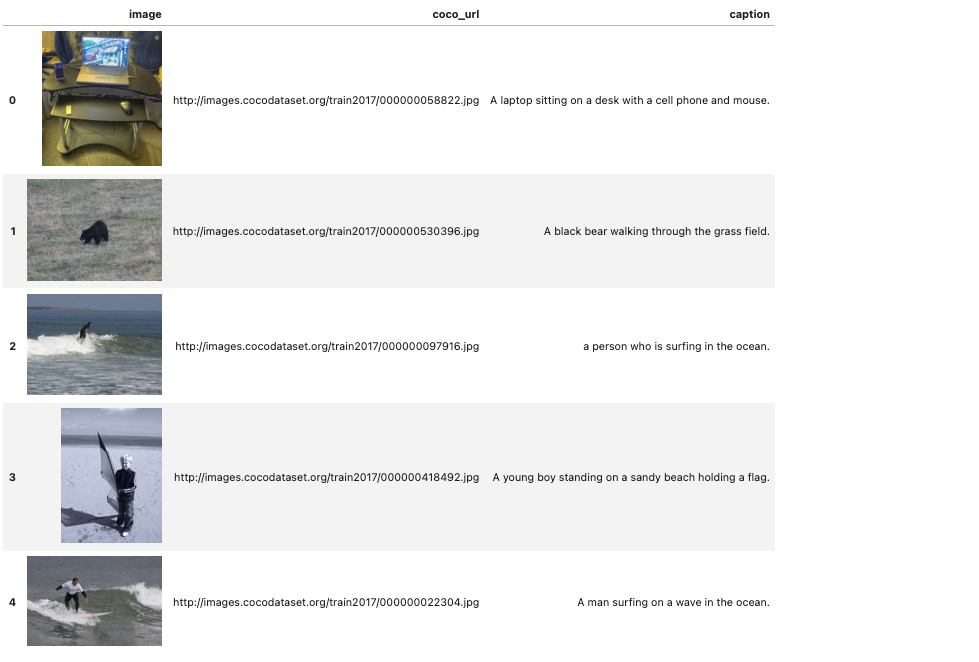
Caso você precise de mais imagens para testar, também é possível encontrar uma versão disponibilizada no Kaggle .
Carregar modelo
Utilizaremos uma versão de 7 bilhões de parâmetros do modelo “LLaVA 1.5” (Language and Vision Assistant), disponível no HuggingFace (Uma plataforma onde a comunidade de Machine Learning colabora com modelos, dados e aplicações) treinada para tarefas de geração de texto a partir de imagens.
%%time
model_id = "llava-hf/llava-1.5-7b-hf"
# Configuração de quantização do modelo, que permite reduzir o uso de memória sem
# comprometer muito a precisão. Aqui estamos configurando para usar quantização em 4 bits.
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# Criação de um pipeline de processamento de imagens para geração de texto
# O pipeline é configurado para a tarefa "image-to-text"
pipe = pipeline(
"image-to-text",
model=model_id,
model_kwargs={
"quantization_config": quantization_config,
"low_cpu_mem_usage": True
}
)
# Carregar o processador associado responsável por pré-processar
# as imagens de entrada e preparar os dados para serem inseridos no modelo
processor = AutoProcessor.from_pretrained(model_id)CPU times: user 28.7 s, sys: 28.1 s, total: 56.8 s
Wall time: 6min 26s📌 Nota: A quantização é uma técnica para reduzir o tamanho do modelo, perdendo um pouco de performance para otimizar o desempenho e rodar em máquinas com memória limitada.
Prompt Engineering
Uma ampla variedade de técnicas poderiam ser aplicadas para desenvolver prompts mais eficazes (inclusive com LangChain, como fiz no último post) ou especializar o modelo com ajuste fino visando obter resultados otimizados. No entanto, como este não é o foco do post, usarei um prompt simples e direto para estabelecer um baseline para avaliar as capacidades do modelo com o mínimo de esforço.
# Cada valor em "content" tem que ser uma lista de dicionário com os tipos ("text", "image")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "Describe this image in a few words:"},
{"type": "image"},
]
},
]
# Formata a conversa (que pode incluir texto e imagens) no formato correto que o modelo entende.
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)O prompt deve ser especificado no seguinte formato:
USER: <image>
<prompt>
ASSISTANT:Inferência
Com o modelo devidamente configurado e o prompt ajustado, estamos prontos para executar o pipeline de inferência. A vantagem de utilizar pipelines é que eles abstraem boa parte da codificação complexa, proporcionando uma interface simples e eficiente. Essa API versátil é dedicada a várias tarefas, como NER (Reconhecimento de Entidades), Análise de Sentimentos, Extração de Features e Question Answering.
for i in tqdm(range(df_sample.shape[0])):
# preparar objetos do loop
coco_url = df_sample.iloc[i]['coco_url']
caption = df_sample.iloc[i]['caption']
index = df_sample.iloc[i].name
# Obter imagem
response = requests.get(coco_url)
image = Image.open(BytesIO(response.content))
# Realizar a inferência usando o pipeline e o prompt gerado
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 32})
# Processar o texto gerado para extrair a parte relevante
result = outputs[0]['generated_text'].split('ASSISTANT:', 1)[1].strip()
# Adicionar o resultado da inferência à nova coluna 'llm' do DataFrame
df_sample.loc[index, 'llm'] = result100%|██████████| 10/10 [00:41<00:00, 4.20s/it]Após a execução do modelo, veja como ficaram os resultados:
Expandir código
# Função para destacar as palavras
def highlight_diff(caption, llm):
# Divide as frases em palavras
caption_words = caption.replace(".", "").split()
llm_words = llm.replace(".", "").split()
# Converte as palavras em conjuntos para encontrar a interseção
caption_set = set(caption_words)
llm_set = set(llm_words)
# Calcula as palavras que não estão na interseção
caption_highlighted = " ".join([f'<span style="color:red">{word}</span>' if word not in llm_set else word for word in caption_words])
llm_highlighted = " ".join([f'<span style="color:red">{word}</span>' if word not in caption_set else word for word in llm_words])
return caption_highlighted, llm_highlighted
# Aplica a função a cada linha do DataFrame e cria novas colunas
df_sample['highlighted_caption'], df_sample['highlighted_llm'] = zip(*df_sample.apply(lambda row: highlight_diff(row['caption'], row['llm']), axis=1))
# Exibir o DataFrame formatado com HTML
HTML(df_sample[['image', 'highlighted_caption', 'highlighted_llm']].to_html(escape=False))
Destaquei em vermelho as palavras que diferem entre a legenda original do dataset e a previsão gerada pelo nosso modelo de linguagem.
💭 Apesar de algumas diferenças sutis entre as duas versões, como ‘looking at his phone’ e ‘looking at his cell phone’, a ideia principal permanece bastante coerente com o que vemos nas imagens. Em alguns casos, como no item 3, a descrição gerada pelo modelo, ‘holding a kite’, parece até mais apropriada do que a fornecida pelo dataset, ‘holding a flag’.
Agora, o próximo passo será quantificar essas diferenças de maneira numérica.
Avaliar modelo
Para medir a precisão das legendas geradas, aplicaremos quatro métricas amplamente usadas:
- BLEU (Bilingual Evaluation Understudy Score): Amplamente utilizada para medir a qualidade de traduções automáticas, mede a sobreposição de n-gramas entre a tradução gerada por um modelo e as traduções de referência, atribuindo uma pontuação que varia de 0 a 1 (aplica também um fator de penalização para evitar que traduções curtas sejam favorecidas);
- ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation): Muito utilizado em tarefa de sumarização de textos, considera a sequência mais longa de palavras que aparecem em ambas as referências e previsões, medindo a capacidade de preservar a ordem das palavras;
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): Baseada na média harmônica da precisão e recall de n-gramas, com recall ponderado mais alto do que a precisão. Essa métrica METEOR foi projetada para corrigir alguns dos problemas (como encontrar sinônimos) nas métricas BLEU e ROGUE;
- BERTScore: Usa embeddings (representações semânticas) obtidas a partir do modelo BERT para comparar a similaridade semântica entre as descrições geradas e as de referência.
Expandir código
# Funções para calcular as métricas
def calcular_bleu(referencias, previsao):
return sentence_bleu([referencias.split(" ")], previsao.split(" "),weights = [1])
def calcular_rouge(referencias, previsao):
scorer = rouge_scorer.RougeScorer(['rougeL'], use_stemmer=True)
return scorer.score(referencias, previsao)['rougeL'].fmeasure
def calcular_meteor(referencias, previsao):
return meteor_score([referencias.split(" ")], previsao.split(" "))
def calcular_bertscore(referencias, previsao):
P, R, F1 = bert_score([previsao], [referencias], lang="en", verbose=True)
return F1.mean().item()%%capture
# Avaliar as amostras no DataFrame
resultados = []
for i, row in df_sample.iterrows():
referencias = row['caption'].replace(".", "")
previsao = row['llm'].replace(".", "")
bleu = calcular_bleu(referencias, previsao)
rouge = calcular_rouge(referencias, previsao)
meteor = calcular_meteor(referencias, previsao)
bert = calcular_bertscore(referencias, previsao)
resultados.append([referencias, previsao, bleu, rouge, meteor, bert])
# Converter os resultados para um DataFrame
df_resultados = pd.DataFrame(resultados, columns=['caption', 'llm', 'BLEU', 'ROUGE', 'METEOR', 'BERTScore'])Vejamos os resultados:
Expandir código
# Configurar o tema do Seaborn
sns.set_theme(style="white", rc={"axes.facecolor": (0, 0, 0, 0)})
# Reformatar o DataFrame para o formato long
df_long = df_resultados[['BLEU', 'ROUGE', 'METEOR', 'BERTScore']].melt(var_name="Métrica", value_name="Valor")
# Calcular a média de cada métrica
mean_values = df_long.groupby('Métrica')['Valor'].mean().reset_index()
# Inicializar o objeto FacetGrid
pal = sns.cubehelix_palette(len(df_long['Métrica'].unique()), rot=-.25, light=.7)
g = sns.FacetGrid(df_long, row="Métrica", hue="Métrica", aspect=6, height=1.5, palette=pal)
# Desenhar as densidades
g.map(sns.kdeplot, "Valor",
bw_adjust=.5, clip_on=False,
fill=True, alpha=1, linewidth=1.5)
g.map(sns.kdeplot, "Valor", clip_on=False, color="w", lw=2, bw_adjust=.5)
# Adicionar linha de referência
g.refline(y=0, linewidth=2, linestyle="-", color=None, clip_on=False)
# Função para rotular o gráfico
def label(x, color, label):
ax = plt.gca()
# Localizar a média correspondente à métrica
mean_value = mean_values[mean_values['Métrica'] == label]['Valor'].values[0]
ax.text(0, .4, f"{label} (Média: {mean_value:.2f})", fontweight="bold", color=color,
ha="left", va="center", transform=ax.transAxes, fontsize=20)
g.map(label, "Valor")
# Ajustar espaçamento entre subplots manualmente
g.figure.subplots_adjust(hspace=0.2)
# Remover detalhes desnecessários dos eixos
g.set_titles("")
g.set(yticks=[], ylabel="")
g.despine(bottom=True, left=True)
# Configurar o eixo x
g.set(xlim=(0.4, 1), xticks=np.arange(0.4, 1.05, 0.1)) # Limites e ticks do eixo x
# Remover rótulos do eixo x em cada subplot
for ax in g.axes.flat:
ax.set_xlabel("") # Remover rótulo do eixo x
ax.tick_params(axis='x', labelsize=16) # Aumentar o tamanho da fonte dos ticks do eixo x
# Exibir o gráfico
plt.show()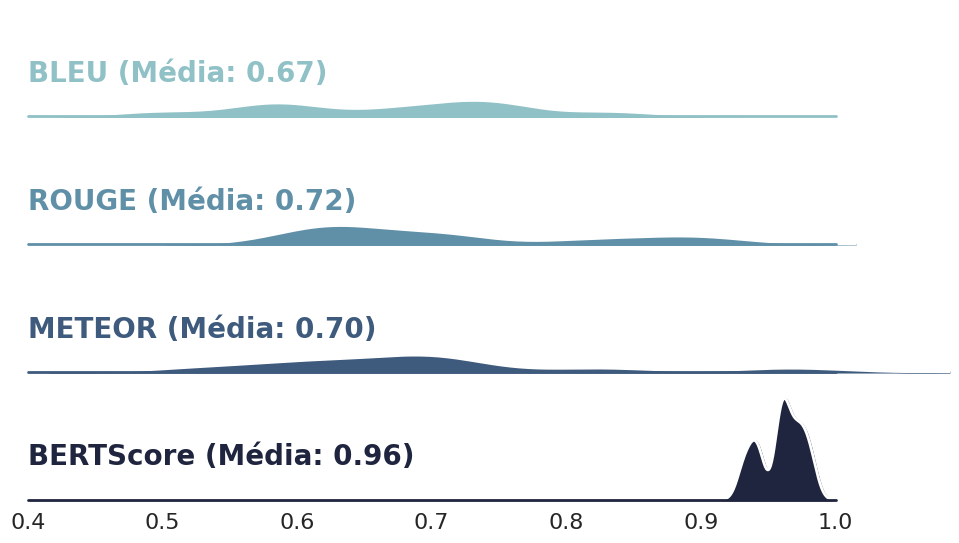
📌 Insights ao Avaliar as Métricas do Modelo:
As métricas baseadas em n-grams e na correspondência de palavras mostraram desempenho subestimado. Embora o modelo tenha apresentado algumas variações na escolha das palavras, as frases geradas mantiveram um sentido geral muito semelhante ao que é retratado nas imagens.
Por outro lado, a métrica baseada em embeddings, que avalia o significado semântico das frases, apresentou resultados significativamente superiores. Essa abordagem se mostrou mais congruente em avaliar a similaridade das descrições geradas e a descrição informada do conteúdo visual das imagens.
É importante ressaltar que nosso prompt foi mantido na forma mais simples possível e que o conjunto de dados abrange um escopo bastante amplo. Com isso, acredito que o modelo ainda tem muito potencial para oferecer resultados ainda mais robustos, sem a necessidade de ajustes finos, em tarefas mais específicas.
Conclusão
O uso da GenAI com o modelo Llava oferece uma solução eficiente para a extração de features de imagens em Python, possibilitando a criação de descrições ricas e detalhadas. Ao comparar a qualidade das saídas com métricas como BLEU, podemos garantir que o modelo esteja oferecendo resultados satisfatórios para as necessidades do projeto.
Se você deseja automatizar processos de análise de imagens, explorar a criação de modelos customizados ou otimizar a organização de dados visuais, a utilização de GenAI com modelos como o Llava pode ser um divisor de águas em seus projetos.
Se este conteúdo foi útil, continue acompanhando o blog para mais tutoriais sobre inteligência artificial e Python!





Share this post
Twitter
LinkedIn
Email