





































Detecção de Linguagem Tóxica com o LLM Gemma e LangChain
Neste post utilizaremos o modelo Gemma de IA generativa do Google com framework LangChain auxiliando na tarefa de prompt engineering

Caso de Uso de IA Generativa: Detecção de Linguagem Tóxica em Mídias Sociais
Neste post, realizaremos a tarefa de detecção de linguagem tóxica em mídias sociais usando o modelo Gemma de IA generativa do Google com o framework LangChain. Vamos explorar como o texto de entrada afeta a saída do modelo e faremos alguma engenharia de prompts para direcioná-lo à tarefa necessária.
Setup
Utilizaremos o ambiente do Kaggle para desenvolvimento deste notebook, que disponibiliza a utilização de GPUs. Através do Hardware Accelerator utilizaremos a NVIDIA TESLA P100 GPU.
Instalar e carregar dependencias
Vamos instalar as bibliotecas accelerate e bitsandbytes que possibilitam a quantização de LLMs e algumas bibliotecas do framework LangChain
!pip install accelerate
!pip install -i https://pypi.org/simple/ bitsandbytes
!pip install langchain langchain_huggingface langchain_community langchain_chromaCarregar bibliotecas
import pandas as pd
import torch
import re
from sklearn.metrics import accuracy_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
from langchain_huggingface import HuggingFacePipeline
from langchain_core.prompts.few_shot import PromptTemplate, FewShotPromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_chroma import ChromaCarregar funções auxiliares
Carregar uma função para limpeza simples dos tweets.
Clique aqui para ver os códigos
def clean_tweet(text):
"""
src: https://github.com/lrdsouza/told-br-classifier
"""
text = text.replace('rt @user', '')
text = text.replace('@user', '')
pattern = re.compile('[^a-zA-Z0-9\sáéíóúàèìòùâêîôûãõçÁÉÍÓÚÀÈÌÒÙÂÊÎÔÛÃÕÇ]')
text = re.sub(r'http\S+', '', text)
text = pattern.sub(r' ', text)
text = text.replace('\n', ' ')
text = ' '.join(text.split())
return text
Carregar dados
Vamos utilizar o conjunto de dados TolD-br, um recurso interessante para o estudo da toxicidade em conteúdos online em português brasileiro. Este dataset foi utilizado na competição ML Olympiad - Toxic Language (PTBR) Detection, organizada pelo TensorFlow UGSP no Kaggle este ano. A competição convidou entusiastas de dados, cientistas e pesquisadores a desenvolverem modelos de machine learning capazes de classificar tweets em português brasileiro como tóxicos ou não tóxicos.
train = pd.read_csv("/kaggle/input/ml-olympiad-toxic-language-ptbr-detection/train (2).csv")
test = pd.read_csv("/kaggle/input/ml-olympiad-toxic-language-ptbr-detection/test (4).csv")
sub = pd.read_csv("/kaggle/input/ml-olympiad-toxic-language-ptbr-detection/sample_submission.csv")Selecionar uma amostra para auxiliar no desenvolvimento do prompt para utilização em novos dados:
valid = train.sample(n=100, random_state=123)Preparar dados
Aplicar limpeza básica para preparar os tweets.
Clique aqui para ver os códigos
train['text'] = train.text.apply(lambda x: clean_tweet(x))
valid['text'] = valid.text.apply(lambda x: clean_tweet(x))
test['text'] = test.text.apply(lambda x: clean_tweet(x))
Carregar Modelo
Neste notebook, faremos uso de um modelo da família Gemma, desenvolvida pelo Google, que consiste em modelos leves e de código aberto construídos com base em pesquisas e tecnologias empregadas no desenvolvimento dos modelos Gemini
📌 Nota: Para utilizar o modelo é necessário consentir com a licença do Gemma com o preenchimento de um formulário disponível na página do modelo.
Utilizaremos a implementação do Gemma-7b-instruct, que é uma variante ajustada por instrução (IT) que pode ser usada para bate-papo e/ou seguir instruções.
# Caminho para o modelo disponível pelo ambiente do Kaggle
model_path = "/kaggle/input/gemma/transformers/1.1-7b-it/1/"
# Definir configuracoes de quantizacao para reduzir
# o tamanho do modelo perdendo pouca performance
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# Instanciar o tokenizador do LLM
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Instanciar o LLM
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quantization_config,
low_cpu_mem_usage=True,
device_map="auto"
)Vamos carregar também um modelo de embedding que utilizaremos para auxiliar na construção do nosso prompt:
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")Preparar modelo
Os modelos da Hugging Face podem ser facilmente executados localmente utilizando a classe HuggingFacePipeline. O Hugging Face Model Hub é um repositório que abriga mais de 120 mil modelos, 20 mil conjuntos de dados e 50 mil aplicativos de demonstração (Spaces), todos de código aberto e disponíveis publicamente. Esta plataforma online permite que as pessoas colaborem facilmente e construam modelos de machine learning juntas.
# Instanciar um pipeline transformers
pipe = pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
max_new_tokens=1,
)
# Passar o pipeline para a classe do LangChain
llm = HuggingFacePipeline(pipeline=pipe)Prompt Engineering
Para resolver este problema, criaremos um template de prompt que utiliza a estratégia few-shot, que pode ser construído a partir de um conjunto de exemplos. O conjunto de exemplos será dinâmico, sendo construído com base em tweets que possuem a maior similaridade semantica com o tweet de entrada.
Preparar exemplos
Selecionaremos os exemplos candidatos do conjunto de dados de treino que não estejam no dataset de validação. Cada exemplo de entrada deve ser um dicionário onde:
key: o nome das variáveis de inputs do prompt;values: os valores dos inputs.
# indices de instancias que nao estao no dataset de validacao (evitar leak)
idx_train_examples = train.loc[~train.index.isin(valid.index)].index
# organizar a lista com os exemplos candidatos
examples = [{'tweet': train.text[i],
'label': str(train.label[i])} for i in idx_train_examples]Criar template para os exemplos com PromptTemplate
Agora precisamos instanciar um PromptTemplate para nosso prompt, que recebe um template das instruções que desejamos passar para o LLM e os inputs que alimentam este template:
example_template = """
Tweet: {tweet}
Label: {label}
"""
# Instanciar o exemplo de prompt
example_prompt = PromptTemplate(
input_variables=["tweet", "label"],
template=example_template
)Inserir exemplos com ExampleSelector
Agora vamos instanciar SemanticSimilarityExampleSelector para selecionar exemplos com base em sua semelhança com a entrada. Ele usa um modelo de embedding para calcular a similaridade entre a entrada e os exemplos de few-shot, bem como um armazenamento de vetores Chroma para realizar a pesquisa do vizinho mais próximo de maneira eficiente.
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples = examples,
embeddings = embeddings,
vectorstore_cls = Chroma,
k=3,
)Aumentar o número de vizinhos mais próximos não garantirá necessariamente resultados melhores. Normalmente k=6 no máximo já é suficiente. Se não conseguir bons resultados assim, já seria mais indicado realizar um ajuste fino mesmo.
Preparar o FewShotPromptTemplate
Finalmente, vamos definir a formatação para a apresentação dos exemplos e, em seguida, usar FewShotPromptTemplate para para gerar o template final que será utilizado como prompt com base nos valores de entrada.
prefix = """The following tweets are written in Brazilian Portuguese. \n\
You are a tweet classifier that identifies \
toxic language as 1 and non-toxic language as 0. \n\
Here are some examples:"""
suffix = """
Tweet: {tweet}
Label: """
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
example_separator='\n',
input_variables=["tweet"],
)Vejamos como será a formatação do prompt para a classificação de cada tweet:
print(prompt.format(tweet=valid.head(1).text.values[0]))## The following tweets are written in Brazilian Portuguese.
## You are a tweet classifier that identifies toxic language as 1 and non-toxic language as 0.
## Here are some examples:
##
## Tweet: caralho eu tenho q fazer alguma coisa mt importante mas eu esqueci o que é então n deve ser importante
## Label: 1
##
## Tweet: caralho as pessoas fazem me sentir a pessoa mais bosta e odiada possível eu tô bem
## Label: 0
##
## Tweet: tenho quase certeza que isso e um homem escroto fingindo ser mulher kkkkkkkkk por um momento eu tbm pensei nisso
## Label: 0
##
## Tweet: vei se um filho faz isso cmg eu pego o sanduíche e enfio no cu dele
## Label: Definir Custom Output Parsers
Para concluir a cadeia, vamos definir uma função que funcione como um Custom Output Parser, que será responsável por pegar a saída do LLM e transformá-la no formato mais adequado para nosso caso. Precisamos apenas do último caractere que será retornado pelo LLM.
def parse(response):
"""Retorna apenas o ultimo caracter da saída do LLM"""
return int(response[-1:])Definir Cadeira LangChain
Chains referem-se à sequências de chamadas - seja para um LLM, uma etapa de pré-processamento de dados, tools, ou ainda etapas de pós-processamento do output gerado pelo modelo. As cadeias construídas desta forma são boas porque oferecem suporte nativo a streaming, assíncrono e inferência em batchs para uso.
chain = prompt | llm | parseVamos testar o comportamento da nossa cadeia em 1 tweet:
print(f"""Tweet: {valid.head(1).text.values[0]}
Label: {valid.head(1).label.values[0]}
Predict: {chain.invoke({'tweet': valid.head(1).text.values[0]})}""")## Tweet: vei se um filho faz isso cmg eu pego o sanduíche e enfio no cu dele
## Label: 1
## Predict: 1Claramente um conteúdo tóxico e que foi classificado corretamente. Mas como queremos realizar a chamada da nossa cadeia para diversos tweets do dataset de test, utilizaremos o método .batch() que executa a cadeia para uma lista de entradas:
%%time
valid['predict'] = chain.batch([{'tweet': x} for x in valid.text])## CPU times: user 1min 26s, sys: 24.8 s, total: 1min 51s
## Wall time: 1min 50sAvaliar resultados
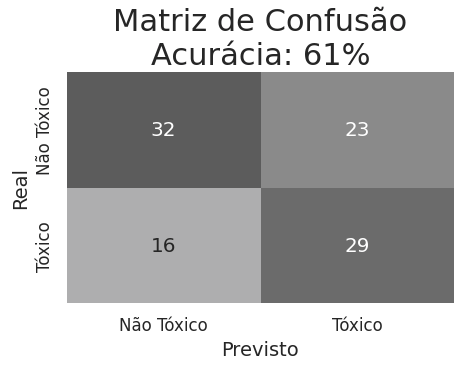
Como a métrica de avaliação da competição era a acurácia, vamos dar uma olhada em como ficou a matriz de confusão:
Clique aqui para ver o código do gráfico
# Calcular métricas
cm = confusion_matrix(valid.label, valid.predict)
acc=accuracy_score(valid.label, valid.predict)
# Configurações de estilo do seaborn
sns.set(font_scale=1.2)
plt.figure(figsize=(5, 3))
# Plotar Matriz de Confusão para o método Vader em inglês
sns.heatmap(cm, annot=True, fmt='d', cmap='binary', cbar=False,vmin=0, vmax=50,
xticklabels=['Não Tóxico', 'Tóxico'], yticklabels=['Não Tóxico', 'Tóxico'])
plt.title(f'Matriz de Confusão\nAcurácia: {acc:.0%}', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.xlabel('Previsto', fontsize=14)
plt.ylabel('Real', fontsize=14)
plt.show()
Conclusão
Embora nosso objetivo não fosse alcançar a perfeição em termos de acurácia, até que o resultado foi satisfatório, dado o potencial dessa ferramenta para resolver uma ampla gama de problemas com poucas modificações nos códigos. Existem muitos outros caminhos a serem explorados (inclusive recomendo assistir à live no YouTube em que os vencedores apresentaram soluções muito mais eficientes), nosso foco aqui foi praticar, aplicar e documentar alguns conceitos interessantes e úteis sobre LLMs e LangChain.


Share this post
Twitter
LinkedIn
Email