




































Gerando arte com Inteligência Artificial
Veja como usar, opções, dicas e truques de modelos de inteligência artificial para criar arte sem escrever uma linha de código (a não ser que você queira).

Introdução
Você já deve ter ouvido falar sobre uma inteligência artificial que gera artes super-realistas a partir de textos e imagens. Hoje em dia já existem algumas opções como DALL·E 2 (da OpenAI/Google) e a Make-A-Scene (da Meta), e essas ferramentas são capazes de gerar versões e estilos diferentes de uma dada imagem ou ainda criar uma imagem com apenas uma breve descrição do resultado desejado. As imagens podem ser tão aleatórias quanto um “gato de óculos e uma coroa” (em homenagem ao dia dos gatos):
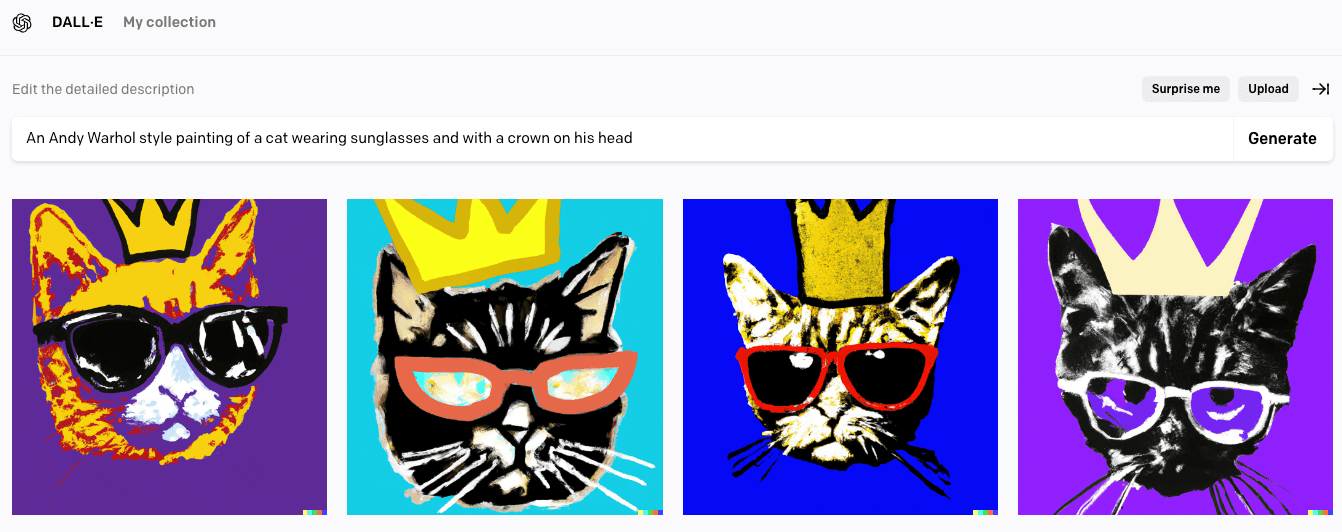 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Não vou entrar na teoria por trás dos algoritmos pois além do artigo oficial, existe bastante conteúdo sobre o assunto disponível na internet. Neste post focarei mais em fazer alguns comentários sobre o que andei estudando e compartilhar algumas dicas úteis sobre como escrever os “parâmetros” ou “queries” para sistemas DALL·E 2 (ou alternativos).
Não posso prometer que depois de ler este post você estará imediatamente capaz de criar artes incríveis utilizando IA até porque eu também sou iniciante no assunto, mas terá algum conhecimento básico para poder trabalhar e desenvolver ainda mais suas habilidades. Para ser honesto, uma vez que acostumamos, não é muito difícil de usar. Não há necessidade de escrever nenhuma linha de código para utilizar a DALL·E 2 nem as outras arquiteturas que apresentarei neste post (no máximo ajustar alguns hiperparâmetros, caso queira).
DALL·E 2
A OpenAI lançou em Janeiro de 2021 o DALL·E e um ano depois, sua segunda geração que constrói imagens mais realistas e precisas, com resolução 4x maior. DALL·E 2 começou como um projeto de pesquisa e agora está disponível em versão beta para aqueles que entrarem na waitlist. Eles pedem algumas informações como redes sociais e intenções de uso. No meu caso, demorou uns 2/3 meses para liberação, quando recebi um e-mail com meu acesso:
O modelo não está finalizado pois existem diversas mitigações de segurança que a equipe da OpenAI ainda vem trabalhando:
- Previnir geração de imagens violentas, limitando a capacidade do DALL·E 2 ao remover conteúdo explicito dos dados de treinamento e minimizando a exposição do algoritmo à estes conceitos;
- Restringir conteúdos políticos evitando seu uso indevido (ex.: fake news);
- Implantação em fases, limitando o número de acessos para usuários confiáveis e a medida que ganharem confiança, liberam a versão beta para mais pessoas.
🚨 Atenção
Para quem quiser ir brincando com esse tipo de rede neural enquanto não recebe o acesso, leia até o final pois apresentarei algumas alternativas!
Instruções de Uso
Ainda existe muita discussão sobre o assunto na comunidade e ainda não consolidou-se um “guia definitivo de como usar a ferramenta”, as dicas que darei aqui foram baseadas em experimentos que fiz e pesquisas na internet (referências no final do post). Tentarei fornecer uma boa quantidade de informações organizadas que sejam fáceis de entender, mas também útil para ajudá-lo a entender como a IA interpreta a frase que você escreve como input.
Parâmetros
Os “parâmetros” que usamos para definir e descrever os detalhes/estilos/objetos/ambiente etc que estão na imagem são a chave. Essas são as instruções ou descrições que “dizem” ao algoritmo o que você deseja ver na imagem.
É preciso escrever a frase de uma maneira que a IA entenda claramente. Você se familiarizará com a maneira de escrever parâmetros ao longo do tempo com a prática (caso tenha tempo, veja este vídeo de como ensinar linguagem de programação para uma criança, que da uma bela intuição de como devemos pensar).
Para começar, precisamos decidir qual é a imagem. É uma pintura? uma fotografia? um desenho de uma linha? Primeiro decidimos o meio da imagem e depois o assunto da imagem. O que vai ter na pintura? Existe uma história a ser contada para descrever visualmente para a IA para que ela esteja na imagem? De que é a imagem?
Se a imagem que você deseja produzir for replicar uma arte (um desenho, pintura, etc. de algo), então você deve pensar no estilo de arte de um artista que você gosta ou qual estilo de arte se adequaria ao tema ou sentimento da peça de arte você está tentando criar.
Exemplos
A seguir veremos alguns exemplos de como fazer e como não fazer a “query para gerar as imagens.”
Para criar uma pintura no estilo de alguém você escreveria algo assim nos parâmetros :“A digital art of a happy dog in a desert with pyramids in the background and planets in the sky” (Uma arte digital de um cachorro feliz em um deserto com pirâmides ao fundo e planetas no céu):
Note que o modelo entende bem o que são os elementos e como eles se posicionam (à frente, atrás, acima, abaixo, direita, esquerda, etc). Além disso, como não especifiquei se era dia/noite nem se o fundo seria um universo, as cores ficaram confusas. Um azul escuro (quase preto) onde estão os planetas e um azul claro (como dia) para o fundo do deserto.
 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Se a imagem não for de uma obra de arte/pintura, não iniciamos a frase com o meio (esboço/pintura/qualquer que seja), em vez disso, começamos a frase descrevendo imediatamente a cena da maneira mais gramaticalmente correta possível (que seja difícil de entender errado).
Veja um exemplo que vi na internet, dizer algo como “Um homem e uma mulher de vestido vermelho ao lado de um cavalo” pode ser mal interpretado pela IA, pois o homem e a mulher podem estar no vestido vermelho ou com roupas vermelhas, além de faltar mais detalhes do que estamos imaginando. Veja como ficou o exemplo gerado:
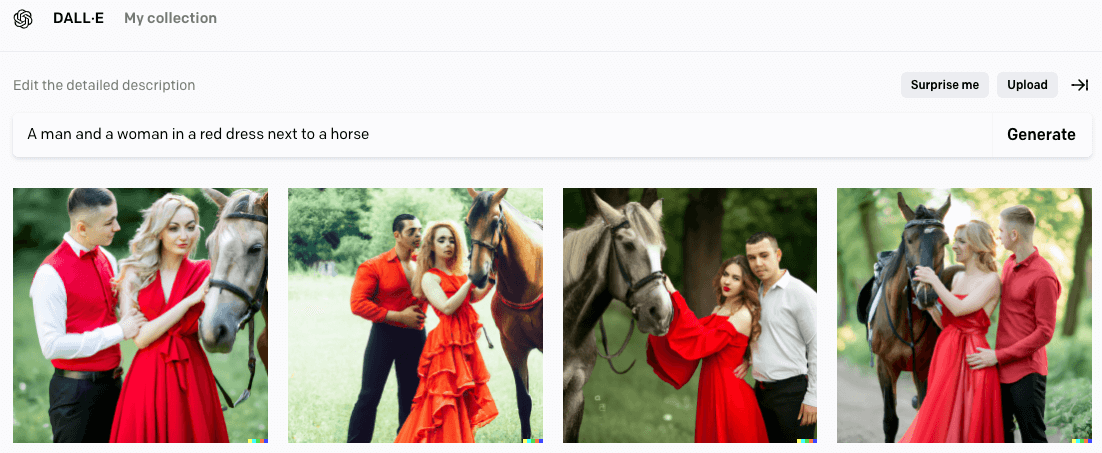 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Até que o resultado não ficou tão ruim, com pelo menos uma imagem com o rapaz de camisa branca. Mas não era exatamente essa cena que tinha em mente, vamos tentar descrever melhor a cena que gostariamos de ver: “Um homem de terno preto e uma mulher de lindo vestido vermelho ao lado de seu majestoso cavalo marrom enquanto observam o pôr do sol”:
 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Nós já estavamos vendo essa cena mentalmente, mas simplesmente não a havíamos descrito bem o suficiente. Então sempre pense nas descrições dessa maneira, tentando explicar uma fotografia para uma criança de dez anos de uma forma que provavelmente seria capaz de desenhá-la ou algo muito parecido sem ver a foto.
Além de descrever bem as fotos, existem alguns tipos de palavras-chave que podem ajudar a melhorar os detalhes, veja alguns bastante populares que criam resultados surpreendentes: “4k”, “Unreal engine”, “Ray tracing”, “Fotorrealismo”, “Hiper-realismo”.
⭐️ Sucesso!
Agora, juntando todas essas dicas, acho que você está pronto para tentar construir seus próprios “parâmetros”.
DALL·E Mini e Stable Diffusion
Ainda não tenho acesso ao DALL·E 2 e agora?
Bom, a OpenAI apresentou o primeiro (e impressionante) modelo para gerar imagens com DALL·E, certo? A partir daí a comunidade ficou enlouquecida e muitos cientistas de dados tentaram reproduzir os resultados inspirados no artigo oficial.
A versão mais promissora que encontrei foi a DALL·E mini, desenvolvida por craiyon.com que é é um modelo de IA capaz de gerar figuras formidáveis a partir de qualquer input de texto. Além disso eles estão trabalhando na versão “DALL·E mega” que possui diversas melhorias nos otimizadores, na arquitetura em geral e treinada em datasets maiores (uma versão beta ja pode ser importada via Python).
Além desta, outro lançamento público anunciado recentemente (e muito promissor) foi o Stable Difusion, que após incansáveis revisões jurídicas, éticas e de tecnologia, lançaram o modelo e um aplicativo web pronto para uso, com licença permissiva para uso comercial e não comercial.
É muito legal ver nestas ferramentas, o fruto de muitas horas de esforço coletivo para criar um único arquivo que comprime a “informação visual da humanidade” em alguns gigabytes!
Exemplos
Veja algumas imagens geradas tentando descrever sentimentos:
 “Felicidade”
“Felicidade”
 “Amor”
“Amor”
 “Solidão”
“Solidão”
Imagens geradas por gomesfellipe utilizando DALL·E Mini
A idéia de gerar estas imagens era tentar entender como uma IA “pensaria” sobre estes termos mas, para surpresa de ninguém, os resultados foram muito próximos de uma busca no Google (dado que o modelo foi treinado em conjuntos de dados públicos). É possível notar também alguns “bugs” como o último smile e um “coração duplo”.
Mesmo assim, achei interessante as paletas de cores apresentadas com cores mais “alegres” para felicidade (como verde, azul, branco e o amarelo dos “smiles”), um vermelho/rosa para amor e solidão em tons de cinza.
Essa rede tem algumas limitações com rostos e acabam sendo meio distorcidas (segundo os desenvolvedores, é uma limitação atual do codificador de imagem mas eles já estão trabalhando nisso). Veja a seguir uma comparação do resultado da DALL·E 2 vs DALL mini para a frase “Uma sereia nadando em um mar de fogo”:


Imagens geradas por gomesfellipe utilizando DALL·E Mini
A imagem gerada pela DALL·E mini tem uma resolução mais baixa e demorou um pouco mais para ser processada. Um ponto interessante é como mesmo esse modelo “menor” já é capaz de entender um “mar” e gerar o reflexo na água. Os “rostos” gerados pela DALL·E mini muitas vezes são comparados com “sonhos” e até mesmo meio assustadores enquanto que a DALL·E 2 conseguiu entregar uma imagem que, apesar de meio “caricata”, até que ficou bastante detalhada.
Opções Alternativas
Depois que o artigo com a ideia principal foi divulgado, a comunidade começou a desenvolver diversas redes que trabalhassem de forma semelhante. Nenhuma das redes conseguiu ser tão realistas quando a DALL·E mas fica aquela coisa meio psicodelica que se parece mesmo com um sonho.
Existem diversas versões, como por exemplo:
- VQGAN+CLIP (focaremos nesta);
- CLIP-GLaSS;
- BigGAN + CLIP + CMA-ES;
- Disco Diffusion v4.1;
- Um app para Windows que usa a própria RAM do pc;
- Midjourney;
- Dentre outras…
Todos os notebooks que estão na lista acima são hospedados no Google Collab e podem ser executados sem nenhum tipo de pré-configuração de ambiente. O modelo mais popular (e o que eu utilizei mais) acabou sendo a VQGAN+CLIP que foi inicialmente escrito em espanhol e depois em inglês.
VQGAN+CLIP
Apesar de muito democrática, o problema de hospedar esses notebooks no Google Collab é que se você estiver usando um usuário gratuito, descobrirá que a GPU e RAM são bem limitada. Algumas imagens precisavam de até 5h para serem geradas e mesmo assim o resultado não ficava bom (ri muito com alguns resultados 😂), enquanto que as imagens geradas com o uso da GPU rodavam em alguns minutos e dava para ver que a rede conseguia “ir mais longe”, alcançando imagens com resolução melhor.
Veja a seguir uma imagem que criei a partir de uma foto da Amora (minha cachorrinha) como “chute inicial”:
” A happy dog in the desert:200 | sunset in the background:100 | planets in the sky:100 | by Salvador Dali:100 | turtle:-100 | city:-100 | buildings:-200”
 Imagem gerada por gomesfellipe utilizando VQGAN+CLIP
Imagem gerada por gomesfellipe utilizando VQGAN+CLIP
Particularmente, gostei bastante do resultado final mas não foi tão fácil utilizando esta rede. Antes de submeter a imagem no notebook, precisei remover o fundo para remover qualquer tipo de ruído pois a rede não é capaz de distinguir o que é um cachorro, o que é meu braço ou o armário ao fundo e os resultados ficavam muito estranhas. Além disso fiz uma colagem (no Power Point mesmo) com alguns elementos que eu gostaria que estivessem na imagem data determinar suas posições.
⚠️ Alerta!
Eu tinha muito claro em minha mente aonde gostaria que os elementos estivessem posicionados, porém, esta etapa de colagem dos elementos é completamente opcional! É uma forma de “guiar” a rede para resultados que estamos procurando, parando em determinada interação e ajustando a posição de elementos (muito útil para arrumar algumas estranhezas que aparecem em rostos) e inputando novamente como imagem inicial.
Além disso, você deve ter notado a presença de pipes “|” e uns valores (como dicionários do Python). A idéia é que as palavras-chave que você colocar entre cada um desses pipes influenciará bastante na imagem final e até mesmo remover coisas que não desejamos.
A primeira sentença é definida automaticamente como 100 “unidades”. Logo em seguida, as próximas sentenças receberão apenas 1 “unidade”. O ideal é colocar o “valor” associado aquela “chave” que representa o quão “proeminente” será aquele elemento na imagem.
Note ainda que eu tentei evitar que o modelo incluí-se novos elementos como uma cidade que estava se formando ao fundo ou uma tartaruga no canto esquerdo informando valores negativos para estes elementos que nãa gostaria que aparecessem.
Estes notebooks não salvam seus resultados, quando você atualizar a página, outra seção será iniciada e todo o trabalho será perdido! Então quando gostar de alguma imagem, não esqueça de salvá-la!
💡 Dica
Nem sempre a última imagem gerada no processo é a que nós mais gostamos, então vale a pena conferir como foi o processo de aprendizagem em “épocas” anteriores.
Mais Parâmetros
Praticamente todos esses notebooks possuem os mesmos parâmetros então passarei por alguns que considero interessantes para se ter uma noção geral de como funciona:
model: há várias opções de modelos treinados em conjuntos de dados específicos para diferentes tarefas, como por exemplo:- Imagens com diferentes texturas:
imagenet_1024,imagenet_16384,sflckr,coco; - Imagens com estilos de arte:
wikiart_1024,wikiart_16384; - Rostos com diferentes traços:
faceshq,ffhq,celebahq;
- Imagens com diferentes texturas:
inicial_image: podemos ter uma idéia de elementos que gostaríamos que estivesse na imagem e então criar uma imagem para usar como “chute inicial” para direcionar o trabalho da rede;seed: é bom colocar um número aleatório (maior que zero) para garantir que o desenvolvimento da imagem seja reprodutível;max_interactions: é o número de vezes que o modelo vai “trabalhar” na imagem. Pode ser limitado, a menos que você pague pelo Google Collab Pro (aí da para colocar um valor bem alto e avaliar um bom ponto de parada após alguns experimentos).heightewidth: a altura e a largura são colocadas automaticamente em 600 e 600. Pode ser que demore um pouco então para quem estiver usando a versão free pode ser útil abaixar para cerca de 200 de largura e altura para aliviar no processamento da imagem e permitir mais iterações.
Mais Exemplos
Veja um exemplo de arte gerada a partir de um quadro, onde a tecnologia atua como um colaborador criativo em vez de uma ferramenta básica:
Esta pintura é intitulada como “Desolate Civilisation” e é composta por 9 pinturas futuristas criadas e montadas utilizando VQGAN+CLIP para se assemelhar à Mona Lisa (via NightCafe Studio).
Interessante como o autor divide a tarefa em 9 “minitarefas”, facilitando assim a produção da imagem toda (além de dar um toque artístico bem interessante).
 Desolate Civilisation - NightCafe Studio
Desolate Civilisation - NightCafe Studio
Discussão Filosófica
Estas novas abordagens estão mudando definitivamente a natureza dos processos criativos. Além de nós, meros mortais não-desenhistas, os artistas também podem se beneficiar destas tecnologias como fonte de inspiração, seja gerando imagens aleatórias sobre coisas que vêm em mente ou ainda “tunar” suas obras, mesclando com diferentes elementos ou tipos de estilos.
Apesar de interessante, para pessoas questionadoras, pode surgir alguma questão filosófica como: será que isto é arte? Existem muitas definições de arte e seu significado varia conforme a época ou cultura.
Li diferentes definições e refleti bastante sobre o assunto, e a definição que mais me agradou foi a de Immanuel Kant (um dos meus filósofos favoritos), que sugere que: “a arte diferencia-se da natureza por ser uma atividade racional e livre. Assim, uma teia de aranha, embora possa parecer bela, não é uma obra de arte, já que se trata de uma tarefa mecânica e natural. A arte também se diferencia da ciência, já que para se produzir uma obra de arte não basta ter conhecimento sobre um determinado assunto - é preciso ter habilidade para fazer. Kant define a arte estética como aquela cuja finalidade imediata é o sentimento do prazer, não apenas o prazer ligado às sensações, mas também o prazer da reflexão.”
 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagino que, pelo menos hoje em dia e por um bom tempo, a IA por si só não conseguirá produzir arte, pois até então todos esses modelos estão “aprendendo” com os inputs que fornecemos e produzindo outputs que pedimos. Isso é uma limitação de uma “inteligência artificial fraca” não sendo capaz de executar a atividade artística “livremente”, além de que sua finalidade imediata não tem haver com prazer de reflexão nenhuma.
Enquanto continuamos a filosofar e especular sobre a definição de arte, podemos usar estes modelos para ajudar na criação de valor com as “artes” mais necessárias no mundo capitalista que vivemos. Veja como fica “Uma foto em 4k de um carro futurista em um salão todo branco e vazio”:
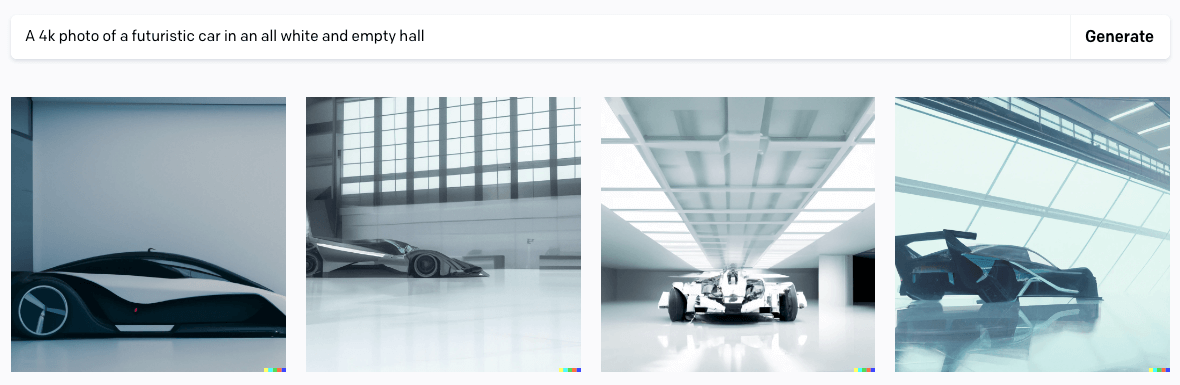 Imagem gerada por gomesfellipe utilizando DALL·E 2
Imagem gerada por gomesfellipe utilizando DALL·E 2
Essas imagens mostram como podemos usar estes modelos para produzir protótipos de bens de consumo, páginas iniciais de sites ou até pôsteres de filmes (imagina “Futuristic Fast and Furious” 😅 😂).
Conclusão
Todos esses experimentos me fizeram entender melhor o que é possível e o que não é possível de fazer, mas me deixaram com muitas dúvidas de questões filosóficas sobre o que é a arte em si no sentido mais amplo 🤯.
No futuro, gostaria de explorar novas formas de me divertir, criar arte e encontrar caminhos para usar essa nova tecnologia para facilitar o trabalho das pessoas e, quem sabe, até monetizar!
Espero que tenham gostado, qualquer crítica ou sugestão será muito bem vinda!
Abraços!
Referências
- https://www.reddit.com/r/bigsleep/comments/p15fis/tutorial_an_introduction_for_newbies_to_using_the/
- https://openai.com/dall-e-2/
- https://github.com/openai/DALL-E/blob/master/notebooks/usage.ipynb
- https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT#scrollTo=ZdlpRFL8UAlW
- https://www.artstation.com/blogs/stijn/B276/ai-sketches-with-vqgan-and-clip-for-concept-art
- https://arxiv.org/abs/2204.06125
- https://arxiv.org/abs/2203.13131
- https://www.artstation.com/blogs/stijn/B276/ai-sketches-with-vqgan-and-clip-for-concept-art
- https://huggingface.co/spaces/dalle-mini/dalle-mini
- https://github.com/borisdayma/dalle-mini
- https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini-Generate-images-from-any-text-prompt--VmlldzoyMDE4NDAy
- https://stability.ai/blog/stable-diffusion-announcement
- https://siliconangle.com/2022/07/14/metas-latest-generative-ai-system-creates-stunning-images-sketches-text/
- https://creator.nightcafe.studio/create
- https://michaelis.uol.com.br/moderno-portugues/busca/portugues-brasileiro/arte
- https://www.significados.com.br/arte/




Share this post
Twitter
LinkedIn
Email