




































Solução Final - ML Olympiad [2º lugar]
Solução que alcançou o 2º lugar na ML Olympiad do Kaggle: análise exploratória em R, feature engineering e modelagem com CatBoost para prever qualidade educacional.

Introdução
No final de Janeiro desde ano (2022) o TFUG - TensorFlow Users Group de São Paulo lançou uma competição no Kaggle para prever as notas do enem que tem relação com um dos 17 tópicos de Desenvolvimento Sustentável das Nações Unidas - Educação de Qualidade.
Além de divertido, o desafio foi repleto de possibilidades e bastante desafiador! Todos os competidores que trabalharam duro em pleno mês de carnaval estão de parabéns! 😅 😂
Aqui estão alguns dos prêmios recebidos:

Como nesta competição havia bastante trabalho a ser feito e tivemos apenas 1 mês para trabalhar na solução, foi preciso fazer uma boa gestão do código e do tempo de desenvolvimento.
Nas seções abaixo apresento o racional por trás da minha solução bem como os 5 melhores modelos individuais (para cada nota) que utilizei em um ensemble para chegar ao segundo lugar.
Definição do problema de negócio
O objetivo desta competição consistiu em prever as notas dos alunos(as) nas provas: Ciências da Natureza, Ciências Humanas, Linguagens e Códigos, Matemática e Redação.
Apesar das notas serem calculadas de maneira independente, a partir de modelos de TRI (Teoria de Resposta ao Item) que levam em consideração a performance em um caderno específico e na dificuldade de cada questão, o mesmo aluno realiza todas as provas em um curto período de tempo.
Portanto, esta tarefa pode ser enquadrada como um problema supervisionado de regressão com múltiplos outputs na qual as previsões são, de certa forma, dependentes da entrada umas das outras.
A validação da solução foi feita utilizando a métrica Mean Columnwise Root Mean Squared Error – MCRMSE, que é basicamente a média do RMSE calculado sobre as previsões de cada nota.
Análise Exploratória (em R)
Convido o leitor a conferir o notebook publicado no Kaggle com a análise exploratória completa. Aqui irei trazer apenas alguns dos principais insights que encontrei durante a etapa de análise exploratória.
Estrutura da base
Veja a seguir qual a estrutura geral da base de dados:
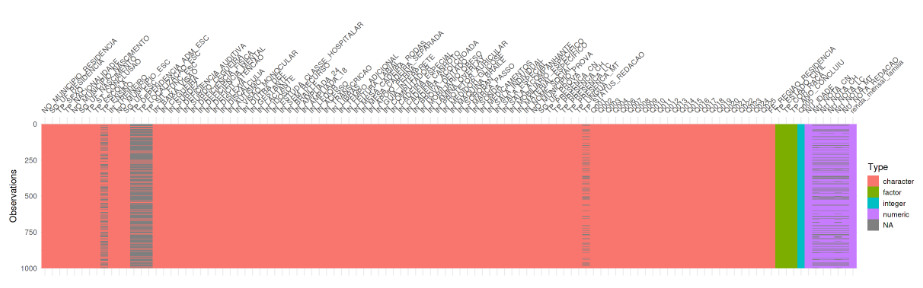
É notório que existem dados faltantes e que parece haver algum padrão. Vejamos com mais detalhse:
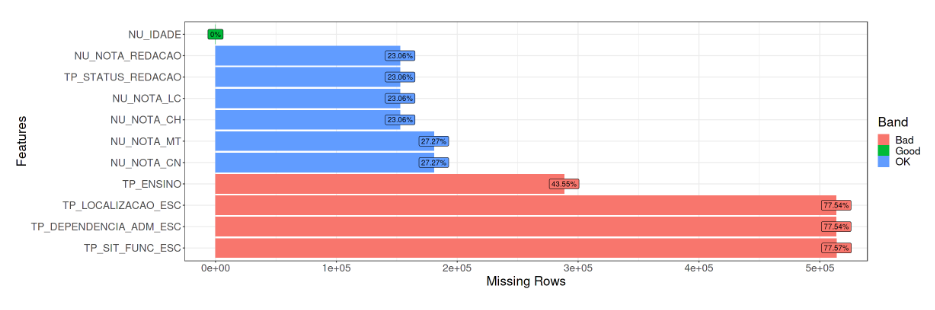
💡 Insights!
Existem dados missing nas 5 targets que queremos prever e note que existe uma relação tanto entre as provas de Matemática e Ciências da Natuerza quanto nas de Ciências Humanas, Linguagens e Códigos e Redação, o que parece ocorrer devido a ausência do aluno incrito em comparecer a realização da prova no respectivo dia.
Ano da base de dados
Essa informação não estava explicitamente disponível, mas após analisar a idade dos participantes em relação ao ano em que concluíram o ensino médio, foi possível identificar que tratavam-se dos dados de 2019, veja:
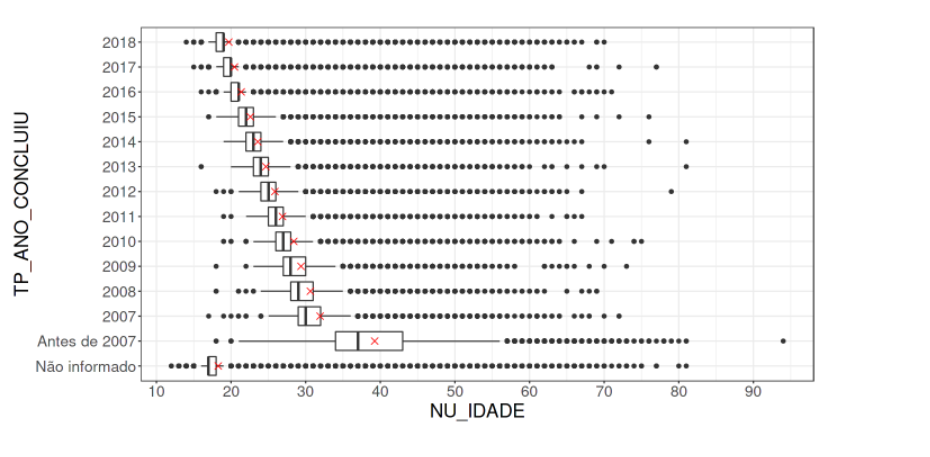
Essa informação poderia ser útil na hora de buscar dados externos (permitido nesta competição).
💡 Insights!
→ Atenção aos outliers: É no mínimo estranho uma pessoa que formou em 2007 ter 17 anos;
→ Como ninguém concluiu a escola no ano de 2019 e a média das idades vai diminuindo quanto mais próximo de 2018, parece que estes dados são de 2019. Essa informção poderia ser útil na hora de procurar por bases externas.
Target
A primeira decisão importante era definir como enquadrar o problema; se seriam múltiplos modelos independentes ou modelos com saídas dependentes.
Primeiramente vejamos como eram as distribuições das notas por caderno:
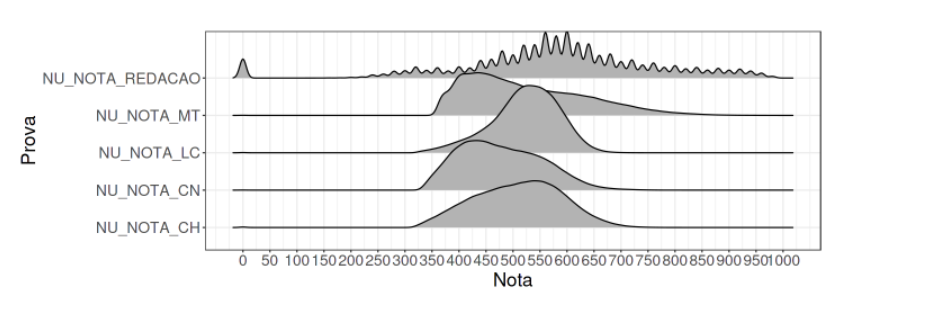
Ao olhar estas distribuições foram surgindo várias idéias! Cheguei até a tentar modelos estatísticos GAM considerando a resposta como uma distribuição Beta (transformando as targets no intervalo [0,1]) mas acabou não apresentando bons resultados para a competição.. acho que seria necessário um pouco mais de preparação nos dados.
Apesar das notas do enem serem calculadas via TRI (Teoria de Resposta ao Item) que considera as notas independentes, parece existir alguma correlação entre as notas, veja:
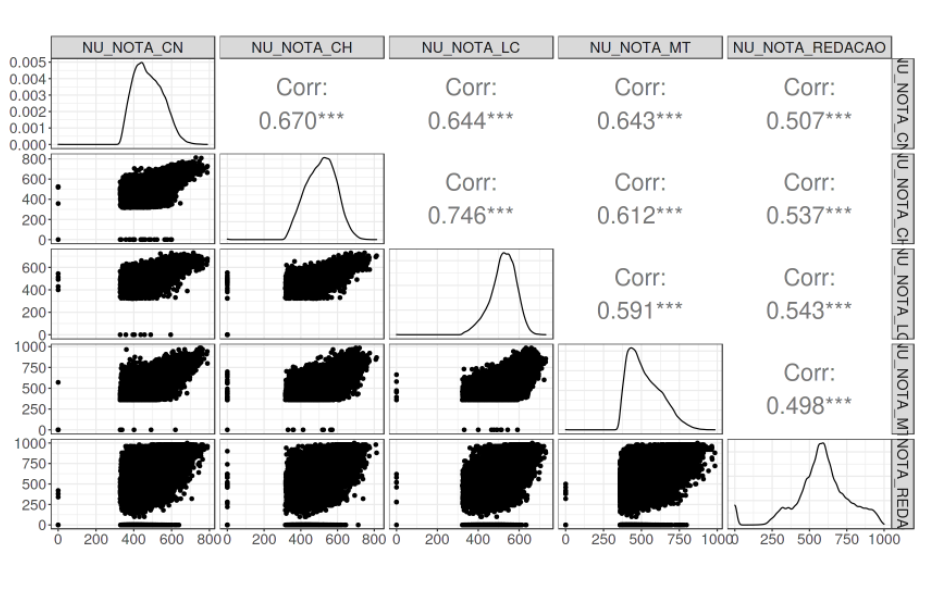
As targets da nota de Línguas e Códigos e Ciências Humanas pareciam possuir uma correlação “interessante”, mas, após testar modelos de múltiplas respostas dependentes para cada dia (com e sem a nota da redação), em nenhum de meus testes superou (de maneira consistente) o desempenho de modelos que considerassem as saídas independentes. Portanto foquei em criar 5 modelos independentes.
Machine Learning (em Python)
Toda a rotina de pré-processamento dos dados, feature engineering, modelagem, ensamble e pós-processamento foi realizada utilizando a linguagem Python para cada uma das 5 notas. Trouxe apenas o modelo final neste post mas, para chegar até aqui foram necessário muitos testes!
Importar dependencias
Carregar pacotes Python:
# data prep
import numpy as np
import pandas as pd
# pre process
from sklearn.preprocessing import MinMaxScaler
# modeling
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor
# plots
import seaborn as sns
import matplotlib.pyplot as pltConfira a baixo as funções desenvolvidas para a solução deste problema
(Clique aqui para expandir as funções)
def prep_data_questionarios(df):
'''
Converte dados de questionario para ordinal
'''
# escolaridade pai
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}
df.loc[:, 'Q001'] = df.loc[:, 'Q001'].map(to_map).astype(int)
# escolaridade mae
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}
df.loc[:, 'Q002'] = df.loc[:, 'Q002'].map(to_map).astype(int)
# ocupacao pai
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': -1}
df.loc[:, 'Q003'] = df.loc[:, 'Q003'].map(to_map).astype(int)
# ocupacao mae
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': -1}
df.loc[:, 'Q004'] = df.loc[:, 'Q004'].map(to_map).astype(int)
# renda da familia
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F':5, 'G':6, 'H':7, 'I':8,
'J':9, 'K':10,'L':11, 'M':12, 'N':13, 'O':14, 'P':15, 'Q':16}
df.loc[:, 'Q006'] = df.loc[:, 'Q006'].map(to_map).astype(int)
# empregado domestico
to_map = {'A':0, 'B':1, 'C':2, 'D':3}
df.loc[:, 'Q007'] = df.loc[:, 'Q007'].map(to_map).astype(int)
# banheiro
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q008'] = df.loc[:, 'Q008'].map(to_map).astype(int)
# qnt de quartos
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q009'] = df.loc[:, 'Q009'].map(to_map).astype(int)
# qnt de carros
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q010'] = df.loc[:, 'Q010'].map(to_map).astype(int)
# qnt de motocicleta
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q011'] = df.loc[:, 'Q011'].map(to_map).astype(int)
# qnt de geladeira
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q012'] = df.loc[:, 'Q012'].map(to_map).astype(int)
# qnt de freezer
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q013'] = df.loc[:, 'Q013'].map(to_map).astype(int)
# qnt de maquina de lavar roupa
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q014'] = df.loc[:, 'Q014'].map(to_map).astype(int)
# qnt de maquina de secar roupa
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q015'] = df.loc[:, 'Q015'].map(to_map).astype(int)
# qnt de microondas
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q016'] = df.loc[:, 'Q016'].map(to_map).astype(int)
# qnt de maquina de lavar louca
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q017'] = df.loc[:, 'Q017'].map(to_map).astype(int)
# tem aspirador de po
to_map = {'A':0, 'B':1}
df.loc[:, 'Q018'] = df.loc[:, 'Q018'].map(to_map).astype(int)
# qtd tv colorida
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q019'] = df.loc[:, 'Q019'].map(to_map).astype(int)
# tem dvd
to_map = {'A':0, 'B':1}
df.loc[:, 'Q020'] = df.loc[:, 'Q020'].map(to_map).astype(int)
# tem tv por assinatura
to_map = {'A':0, 'B':1}
df.loc[:, 'Q021'] = df.loc[:, 'Q021'].map(to_map).astype(int)
# qtd telefone celular
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q022'] = df.loc[:, 'Q022'].map(to_map).astype(int)
# qtd telefone fixo
to_map = {'A':0, 'B':1}
df.loc[:, 'Q023'] = df.loc[:, 'Q023'].map(to_map).astype(int)
# qtd computador
to_map = {'A':0, 'B':1, 'C':2, 'D':3, 'E':4}
df.loc[:, 'Q024'] = df.loc[:, 'Q024'].map(to_map).astype(int)
# tem acesso a internet
to_map = {'A':0, 'B':1}
df.loc[:, 'Q025'] = df.loc[:, 'Q025'].map(to_map).astype(int)
return(df)
def fe_questionario(df):
'''
Gerar novas features artificiais baseadas nos dados de questionario
'''
df.loc[:, "Q021+Q006"] = df["Q021"] + df["Q006"]
df.loc[:, "Q018+Q006"] = df["Q018"] + df["Q006"]
df.loc[:, "Q018+Q008"] = df["Q018"] + df["Q008"]
df.loc[:, "Q010+Q018"] = df["Q010"] + df["Q018"]
df.loc[:, "Q018+Q024"] = df["Q018"] + df["Q024"]
df.loc[:, "Q018*Q006"] = df["Q018"] * df["Q006"]
df.loc[:, "Q010*Q018"] = df["Q010"] * df["Q018"]
return df
def fe_mun(data):
'''
Gerar novas features a partir das localizacoes de municipio
'''
for c in list(data.columns[data.dtypes=='category']):
data.loc[:, c] = data.loc[:, c].astype('object')
data.loc[:, 'FE_MUNICIPIO_PROVA_x_MUNICIPIO_RESIDENCIA'] = np.where(data.NO_MUNICIPIO_PROVA == data.NO_MUNICIPIO_RESIDENCIA , 1, 0)
data.loc[:, 'FE_MUNICIPIO_PROVA_x_MUNICIPIO_NASCIMENTO'] = np.where(data.NO_MUNICIPIO_PROVA == data.NO_MUNICIPIO_NASCIMENTO , 1, 0)
data.loc[:, 'FE_MUNICIPIO_PROVA_x_MUNICIPIO_ESC'] = np.where(data.NO_MUNICIPIO_PROVA == data.NO_MUNICIPIO_ESC , 1, 0)
data.loc[:, 'FE_MUNICIPIO_RESIDENCIA_x_MUNICIPIO_NASCIMENTO'] = np.where(data.NO_MUNICIPIO_RESIDENCIA == data.NO_MUNICIPIO_NASCIMENTO , 1, 0)
data.loc[:, 'FE_MUNICIPIO_RESIDENCIA_x_MUNICIPIO_ESC'] = np.where(data.NO_MUNICIPIO_RESIDENCIA == data.NO_MUNICIPIO_ESC , 1, 0)
data.loc[:, 'FE_MUNICIPIO_NASCIMENTO_x_MUNICIPIO_ESC'] = np.where(data.NO_MUNICIPIO_RESIDENCIA == data.NO_MUNICIPIO_ESC , 1, 0)
for c in list(data.columns[data.dtypes=='object']):
data.loc[:, c] = data.loc[:, c].astype('category')
return data
def fe_in(df):
'''
Gerar features a partir das indicadoras
'''
df.loc[:, 'IN_DEFICIT_ATENCAO+IN_TEMPO_ADICIONAL'] = df["IN_DEFICIT_ATENCAO"] + df["IN_TEMPO_ADICIONAL"]
df.loc[:, 'IN_LEDOR+IN_TRANSCRICAO'] = df["IN_LEDOR"] + df["IN_TRANSCRICAO"]
return df
def prep_co_escola(df):
'''
Converter codigo da escola para categorico
'''
df.loc[:, 'CO_ESCOLA'] = [str(x) for x in df.CO_ESCOLA]
df.loc[:, 'CO_ESCOLA'] = np.where(df['CO_ESCOLA']=='nan', np.nan, df['CO_ESCOLA'])
df.loc[:, 'CO_ESCOLA'] = df.loc[:, 'CO_ESCOLA'].astype('category')
return df
def fe_extra(df):
'''
Gerar novas features
'''
df.loc[:, "FE_IDADE_DISCRETA"] = pd.cut(df.NU_IDADE, (0, 15, 18, 23, 36, 60, 120), labels=['ADOLESCENTE','ADOLESCENTE_2', 'JOVEM','JOVEM_2', 'ADULTO', 'IDOSO']).astype('category')
df.loc[:, 'FE_OCUPACAO_PAIS'] = df.Q003 + df.Q004
df.loc[:, 'FE_ESCOLARIDADE_PAIS'] = df.Q001 + df.Q002
df.loc[:, 'FE_RENDA_POR_PESSOA'] = df.Q006 / df.Q005
df.loc[:, 'FE_CELULAR_POR_PESSOA'] = df.Q022 / df.Q005
df.loc[:, 'FE_COMPUTADOR_POR_PESSOA'] = df.Q024 / df.Q005
df.loc[:, 'FE_VISAO_RUIM'] = df[['IN_BAIXA_VISAO', 'IN_CEGUEIRA', 'IN_VISAO_MONOCULAR', 'IN_SURDO_CEGUEIRA']].max(axis=1)
df.loc[:, 'FE_AUDICAO_RUIM'] = df[['IN_SURDEZ', 'IN_DEFICIENCIA_AUDITIVA', 'IN_SURDO_CEGUEIRA']].max(axis=1)
df.loc[:, 'FE_TDAH_MAIS_TEMPO'] = df.IN_TEMPO_ADICIONAL + df.IN_DEFICIT_ATENCAO
df.loc[:, 'FE_TDAH_MEDICADO'] = np.where((df.IN_DEFICIT_ATENCAO==1)&(df.IN_MEDICAMENTOS==1), 1, 0)
df.loc[:, 'FE_RECURSO_VISAO'] = df[['IN_BRAILLE', 'IN_AMPLIADA_24', 'IN_AMPLIADA_18', 'IN_LEDOR', 'IN_MAQUINA_BRAILE', 'IN_LAMINA_OVERLAY']].max(axis=1)
df.loc[:, 'FE_RECURSO_SURDEZ'] = df[['IN_LIBRAS', 'IN_LEITURA_LABIAL', 'IN_TRANSCRICAO']].max(axis=1)
acess = ['IN_ACESSO', 'IN_MESA_CADEIRA_RODAS', 'IN_MESA_CADEIRA_SEPARADA', 'IN_APOIO_PERNA', 'IN_CADEIRA_ESPECIAL', 'IN_CADEIRA_CANHOTO', 'IN_CADEIRA_ACOLCHOADA', 'IN_MOBILIARIO_OBESO', 'IN_SALA_INDIVIDUAL', 'IN_SALA_ESPECIAL', 'IN_SALA_ACOMPANHANTE', 'IN_MOBILIARIO_ESPECIFICO', 'IN_MATERIAL_ESPECIFICO']
df.loc[:, 'FE_ACESSIBILIDADE'] = df[acess].max(axis=1)
return df
Carregar features artificiais extraídas através de um modelo KNN. Não apresentarei o código aqui (talvez fique para um próximo post) mas a idéia é basicamente a seguinte:
🧪 Feature Extraction com KNN
Ajuste um KNeighborsRegressor encontrando os K-vizinhos mais próximos de cada instância out-of-fold via validação cruzada (para evitar data leak) nos dados de treino e depois ajuste um modelo em todos os dados de treino para obter os K-vizinhos mais próximos nos dados de teste.
Quem sabe no futuro faço um post compartilhando esta estratégia com mais detalhes.
knn_train = pd.read_csv("../input/knn/KNN_feat_train_CH_LC.csv")
knn_test = pd.read_csv("../input/knn/KNN_feat_test_CH_LC.csv")
knn_train_cn_mt = pd.read_csv("../input/knn/KNN_feat_train_CN_MT.csv")
knn_test_cn_mt = pd.read_csv("../input/knn/KNN_feat_test_CN_MT.csv")
knn_train_rd = pd.read_csv("../input/knn/KNN_feat_train_RD.csv")
knn_test_rd = pd.read_csv("../input/knn/KNN_feat_test_RD.csv")Carregar dados
Importar uma versão do dataset no formato .parquet que foi compactada com um truque para otimizar o consumo de memória disponibilizada pelos organizadores neste notebook.
train = pd.read_parquet('train.parquet')
test = pd.read_parquet('test.parquet')
sub = pd.read_csv('../input/qualityeducation/sample_submission.csv')Definir objetos com targets
targets = ['NU_NOTA_LC', 'NU_NOTA_CH', 'NU_NOTA_CN', 'NU_NOTA_MT', 'NU_NOTA_REDACAO']
presencas = ['TP_PRESENCA_LC', 'TP_PRESENCA_CH', 'TP_PRESENCA_CN', 'TP_PRESENCA_MT', 'TP_STATUS_REDACAO']⚠️ Atenção:
A feature de presença é muito importante no pós-processamento para atribuir nota zero aos alunos que não foram realizar a prova mas não faz sentido mantê-la nos dados de treino pois será sempre constante.
Dados externos
Dados Externos utilizados:
Esta base tinha muita informação legal mas sua cobertura temporal estava bastante defasada (1991 - 2010) o que pode adicionar algum ruído ao modelo.
As features selecionadas (sem muito critério) desta base foram:
extra1 = pd.read_csv("municipio.csv")
extra1 = extra1[extra1.ano==2010]
features_extra1 = ['expectativa_vida', 'razao_dependencia', 'expectativa_anos_estudo',
'taxa_analfabetismo_11_a_14', 'taxa_analfabetismo_15_a_17', 'taxa_analfabetismo_18_mais',
'taxa_atraso_0_basico', 'taxa_atraso_0_fundamental', 'taxa_atraso_0_medio',
'taxa_freq_bruta_medio', 'taxa_freq_liquida_medio',
'taxa_freq_medio_18_24', 'taxa_freq_medio_6_14', 'indice_gini','prop_pobreza_extrema', 'prop_pobreza',
'prop_renda_10_ricos', 'prop_renda_20_pobres', 'razao_10_ricos_40_pobres','renda_pc' , 'renda_pc_quintil_1',
'indice_theil', 'prop_trabalhadores_conta_proria',
'prop_empregadores', 'prop_ocupados_agropecuaria', 'prop_ocupados_comercio',
'prop_ocupados_construcao', 'prop_ocupados_formalizacao', 'prop_ocupados_medio',
'prop_ocupados_servicos', 'prop_ocupados_superior',
'prop_ocupados_renda_0', 'renda_media_ocupados', 'indice_treil_trabalho',
'taxa_ocupados_carteira', 'taxa_agua_encanada',
'taxa_banheiro_agua_encanada', 'taxa_coleta_lixo', 'taxa_energia_eletrica',
'taxa_agua_esgoto_inadequados', 'taxa_criancas_dom_sem_fund',
'pea', 'indice_escolaridade', 'indice_frequencia_escolar',
'idhm', 'idhm_e', 'idhm_l', 'idhm_r']
extra1 = extra1[['id_municipio']+features_extra1]
train = pd.merge(train, extra1, how='left', left_on='CO_MUNICIPIO_RESIDENCIA', right_on='id_municipio')
test = pd.merge(test, extra1, how='left', left_on='CO_MUNICIPIO_RESIDENCIA', right_on='id_municipio')Base disponível no mesmo site dos dados da competição e que trás informações muito ricas das escolas do Brasil. Infelizmente quase 75% da informação da escola do aluno era missing então esta base não conseguiu alavancar os ganhos do modelo de maneira considerável.
Nesta base foquei principalmente nas features utilizadas para calcular o IIE (Índice de Estrutura da Escola) que se baseia nos seguintes componentes:
| Componente 1: Pedagógica (IEE_Pedagógico): | Componente 2: Básica (IEE_Básico): | Componente 3: Tecnológica (IEE_Tecnológico): |
|---|---|---|
| Qualificação do docente (formação acadêmica dos professores) | Água filtrada (binária) | Número de computadores por aluno (computadores disponíveis para uso dos alunos) |
| Número de alunos por sala | Acesso à rede pública de energia (binária) | Número de equipamentos multimídia por aluno |
| Número de funcionários por aluno | Acesso à rede pública de esgoto (binária) | Acesso a internet (binária) |
| Quadra de esportes coberta (binária) | Coleta periódica de lixo (binária) | Laboratório de Ciências (binária) |
| Biblioteca (binária) | Banheiro dentro do prédio (binária) | Laboratório de Informática (binária) |
# Importar dados
extra2 = pd.read_csv('microdados_ed_basica_2021.csv', error_bad_lines=False, sep=';', encoding='latin1', dtype={'CO_ORGAO_REGIONAL': 'str'})
extra2 = extra2[extra2.isnull().sum(axis=1) / extra2.shape[1] < .9]
# Tratamento nas features
extra2.loc[:, 'QT_TOTAL_ALUNOS'] = extra2[['QT_MAT_BAS_ND', 'QT_MAT_BAS_BRANCA', 'QT_MAT_BAS_PRETA', 'QT_MAT_BAS_PARDA', 'QT_MAT_BAS_AMARELA', 'QT_MAT_BAS_INDIGENA']].sum(axis=1).fillna(0)
extra2.loc[:, 'QT_TOTAL_PROFESSORES'] = (extra2.QT_DOC_BAS + extra2.QT_DOC_INF + extra2.QT_DOC_INF_CRE + extra2.QT_DOC_INF_PRE + extra2.QT_DOC_FUND + extra2.QT_DOC_FUND_AI + extra2.QT_DOC_FUND_AF + extra2.QT_DOC_MED + extra2.QT_DOC_PROF + extra2.QT_DOC_PROF_TEC + extra2.QT_DOC_EJA + extra2.QT_DOC_EJA_FUND + extra2.QT_DOC_EJA_MED + extra2.QT_DOC_ESP + extra2.QT_DOC_ESP_CC + extra2.QT_DOC_ESP_CE).fillna(0)
extra2.loc[:, 'QT_SALAS_UTILIZADAS'] = (extra2.loc[:, 'QT_TOTAL_ALUNOS'] / extra2.QT_SALAS_UTILIZADAS).fillna(0)
extra2.loc[:, 'QT_COMP_DISP_ALUNO'] = extra2.QT_DESKTOP_ALUNO + extra2.QT_COMP_PORTATIL_ALUNO + extra2.QT_TABLET_ALUNO
# Selecao de faetures importantes
features_extra2 = ['CO_ENTIDADE', 'QT_SALAS_UTILIZADAS', 'QT_TOTAL_PROFESSORES', 'IN_QUADRA_ESPORTES_COBERTA', 'IN_BIBLIOTECA',
'IN_AGUA_POTAVEL', 'IN_ENERGIA_REDE_PUBLICA', 'IN_ESGOTO_REDE_PUBLICA', 'IN_LIXO_SERVICO_COLETA', 'IN_BANHEIRO',
'QT_COMP_DISP_ALUNO', 'QT_EQUIP_MULTIMIDIA', 'IN_INTERNET', 'IN_LABORATORIO_CIENCIAS', 'IN_LABORATORIO_INFORMATICA']
extra2 = extra2[features_extra2]
# Remover outliers
for c in list(extra2.iloc[:, 1:].columns):
trs = extra2.loc[extra2[c]!=88888, c].quantile(.99)
extra2.loc[(extra2[c]==88888)|(extra2[c]>trs), c] = trs
#Normalizar para calcular IEE
scaler = MinMaxScaler()
to_iee = scaler.fit_transform(extra2.iloc[:, 1:])
to_iee = pd.DataFrame(to_iee, columns=extra2.iloc[:, 1:].columns)
# Calcular IEE e componentes
extra2.loc[:, 'COMP1'] = to_iee[['QT_SALAS_UTILIZADAS', 'QT_TOTAL_PROFESSORES', 'IN_QUADRA_ESPORTES_COBERTA', 'IN_BIBLIOTECA']].sum(axis=1)
extra2.loc[:, 'COMP2'] = to_iee[['IN_AGUA_POTAVEL', 'IN_ENERGIA_REDE_PUBLICA', 'IN_ESGOTO_REDE_PUBLICA', 'IN_LIXO_SERVICO_COLETA', 'IN_BANHEIRO']].sum(axis=1)
extra2.loc[:, 'COMP3'] = to_iee[['QT_COMP_DISP_ALUNO', 'QT_EQUIP_MULTIMIDIA', 'IN_INTERNET', 'IN_LABORATORIO_CIENCIAS', 'IN_LABORATORIO_INFORMATICA']].sum(axis=1)
extra2.loc[:, 'IEE'] = extra2.COMP1 + extra2.COMP2 + extra2.COMP3
train = pd.merge(train, extra2, how='left', left_on='CO_ESCOLA', right_on='CO_ENTIDADE').drop('CO_ENTIDADE', axis=1)
test = pd.merge(test, extra2, how='left', left_on='CO_ESCOLA', right_on='CO_ENTIDADE').drop('CO_ENTIDADE', axis=1)Modelagem
Testei muitos modelos e muitas abordagens (inclusive com finalidade de estudo). Foram modelos estatísticos (GAM considerando a distribuição Beta(0,1)), redes neurais (TabNet) e árvores mas no final das contas os que tiveram melhor custo/benefício foram o LightGBM e o CatBoost.
Sobre o tuning, tomei a decisão de não investir muito em otimização automática de hiperparâmetros pois o tempo era curto e os ganhos seriam pequenos comparados com o potencial ganho com a variedade de features que poderiam ser geradas, então fiz apenas alguns testes manuais conforme via necessidade.
Pre processing
A etapa que investi bastante tempo foi para criar novas variáveis. A seguir trago algumas features construídas que foram utilizadas em determinados modelos, a partir dos dados disponíveis:
- Renda somada dos pais;
- Nível de ocupação somado dos pais;
- Renda dividido pelo número de pessoas na casa;
- Quantidade de celulares por pessoa na casa;
- Quantidade de computadores por pessoa na casa;
- Se a pessoa possui visão ruim (se possui baixa visão, cegueira ou monocular);
- Se a pessoa possui audição ruim (Surdez, deficiência auditiva);
- Se o aluno possui TDAH e toma medicamento controlado;
- Se o aluno possui TDAH e teve mais tempo de prova;
- Se precisou de recurso de visão ou audição (libras, baile, etc);
- Se o município que nasceu é o mesmo da escola;
- Se o município que fez a prova é o mesmo da escola;
- Se o município da prova é o mesmo da residência;
- Nota média dos alunos da respectiva escola nas outras provas (*);
- Renda média dos alunos da respectiva escola (*).
(*) Estas features precisaram ser calculadas de maneira muito cuidadosa para não causar algum tipo de data leak!
Post Processing
Essa base tinha uma pegadinha que fazia muita diferença no resultado final. Existem duas possibilidades de um aluno tirar zero em uma prova: errar tudo ou não comparecer.
Como temos a informação da presença do aluno na prova (o que na prática seria meio estranho) bastava dar zero para os alunos faltantes na hora de prever nos dados de teste para submeter.
Linguagens e Códigos
Definir finalidade de algumas colunas:
# colunas que serao dropadas
to_drop = ['IN_PROVA_DEITADO',
'NU_INSCRICAO',
'CO_MUNICIPIO_ESC',
'CO_UF_NASCIMENTO',
'CO_UF_RESIDENCIA',
'CO_UF_ESC',
'CO_UF_PROVA',
'CO_MUNICIPIO_PROVA',
'CO_MUNICIPIO_RESIDENCIA',
'CO_MUNICIPIO_NASCIMENTO']
# definir target e presenca
target = "NU_NOTA_LC"
presenca = "TP_PRESENCA_LC"
# demais notas para dropar (menos ch)
notas = list(set(targets)-set([target, 'NU_NOTA_CH']))Pré-processamento nos dados de treino
X = train.copy()
X.loc[:, 'knn_feature'] = knn_train.knn_oof
X = X.drop(to_drop, axis=1)
X = X[X[presenca]==1]
X = X[~X[target].isnull()]
X = X.loc[:, ~X.columns.isin([target]+[presenca]+notas)]
X.loc[:, 'FE_RENDA'] = X.loc[:, 'Q006'].map({'A':0, 'B':1000, 'C':1500, 'D':2000,
'E':2500, 'F':3000, 'G':4000, 'H':5000, 'I':6000, 'J':7000,'K':8000,'L':9000,
'M':10000, 'N':12000, 'O':15000, 'P':20000, 'Q':30000}).astype(int)
X = prep_data_questionarios(X)
X = fe_mun(X)
X = fe_questionario(X)
X = fe_in(X)
X = prep_co_escola(X)
X = fe_extra(X)
y = train.loc[(train[presenca]==1)&(~train[target].isnull()), target].astype(np.float64)Pré-processamento nos dados de teste
X_test = test.copy()
X_test.loc[:, 'knn_feature'] = knn_test.knn_test
X_test = X_test.drop(to_drop, axis=1)
X_test = X_test.loc[:, ~X_test.columns.isin([presenca])]
X_test.loc[:, 'FE_RENDA'] = X_test.loc[:, 'Q006'].map({'A':0, 'B':1000, 'C':1500, 'D':2000,
'E':2500, 'F':3000, 'G':4000, 'H':5000, 'I':6000, 'J':7000, 'K':8000,'L':9000,
'M':10000, 'N':12000, 'O':15000, 'P':20000, 'Q':30000}).astype(int)
X_test = prep_data_questionarios(X_test)
X_test = fe_mun(X_test)
X_test = fe_questionario(X_test)
X_test = fe_in(X_test)
X_test = prep_co_escola(X_test)
X_test = fe_extra(X_test)Feature engineering separada para evitar data leak:
# calcular estatisticas nos dados de treino
co_escola_renda_media = X.groupby('CO_ESCOLA').FE_RENDA.mean()
co_escola_idade_media = X.groupby('CO_ESCOLA').NU_IDADE.mean()
co_escola_nota_ch = X.groupby('CO_ESCOLA').NU_NOTA_CH.mean()
X = X.drop('NU_NOTA_CH', axis=1)
# instanciar objeto com as estatisticas por escola
co_escola_aux = pd.DataFrame({
'CO_ESCOLA': co_escola_renda_media.index,
'FE_ESCOLA_RENDA_MEDIA': co_escola_renda_media,
'FE_IDADE_MEDIA': co_escola_idade_media,
'FE_NOTA_CH': co_escola_nota_ch
}).reset_index(drop=True)
# Concatenar estatisticas nas bases de treino e teste
X = pd.merge(X, co_escola_aux, how='left', on='CO_ESCOLA')
X_test = pd.merge(X_test, co_escola_aux, how='left', on='CO_ESCOLA')
# Codigo da escola para categorico
X.loc[:, 'CO_ESCOLA'] = X.CO_ESCOLA.astype('object').astype('category')
X_test.loc[:, 'CO_ESCOLA'] = X_test.CO_ESCOLA.astype('object').astype('category')
# Features de contagem
X.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X_test.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X.NO_MUNICIPIO_RESIDENCIA.map({x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X_test.NO_MUNICIPIO_RESIDENCIA.map({ x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X.NO_MUNICIPIO_NASCIMENTO.map({ x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X_test.NO_MUNICIPIO_NASCIMENTO.map({x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X.loc[:, 'FE_COUNT_ESCOLA'] = X.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_ESCOLA'] = X_test.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})Ajustar modelo:
cat_feat = X.columns[X.dtypes=='category']
cat_indices = [X.columns.get_loc(x) for x in cat_feat]
for c in list(cat_feat):
X.loc[:, c] = X.loc[:, c].astype(object).fillna("XXX").astype("category")
X_test.loc[:, c] = X_test.loc[:, c].astype(object).fillna("XXX").astype("category")
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.1, random_state=SEED)
clf = CatBoostRegressor(random_state=314,
cat_features=cat_indices,
verbose=0,
loss_function = "RMSE",
od_type = "Iter",
od_wait = 100,
iterations=3000,
use_best_model=True)
clf.fit(X, y, eval_set = (X_eval, y_eval), verbose=False, plot=True)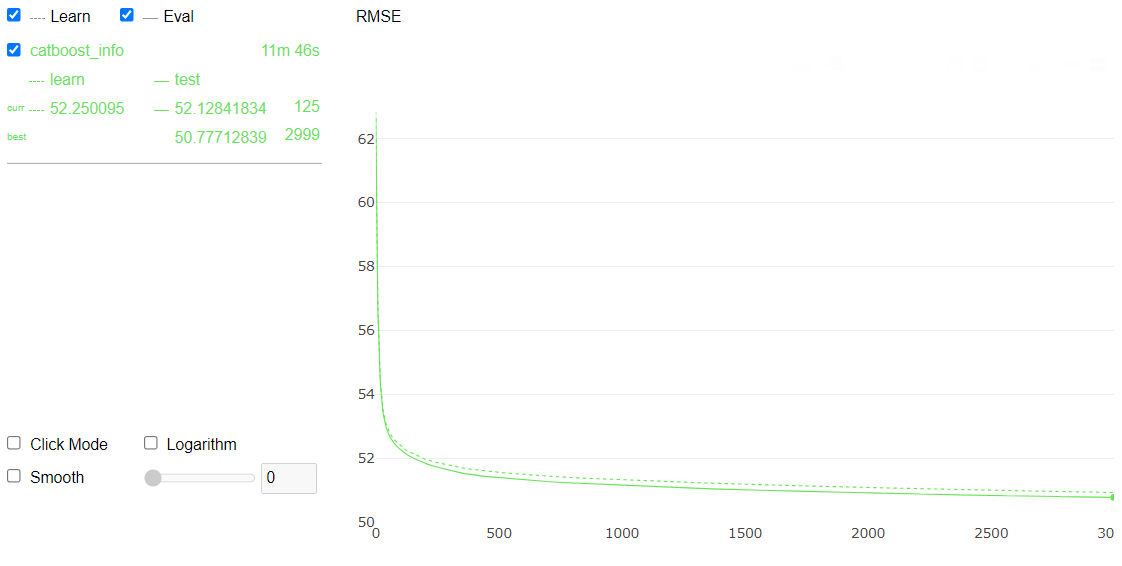
Salvar previsões:
sub.loc[:, 'NU_NOTA_LC'] = clf.predict(X_test)
# alunos que nao foram fazer a prova tiraram zero
sub.loc[test.TP_PRESENCA_LC!=1, 'NU_NOTA_LC'] = 0Comparar distribuição da target nos dados de treino com relação às previsões do modelo:
sns.kdeplot(train.loc[:, target], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, target], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(target)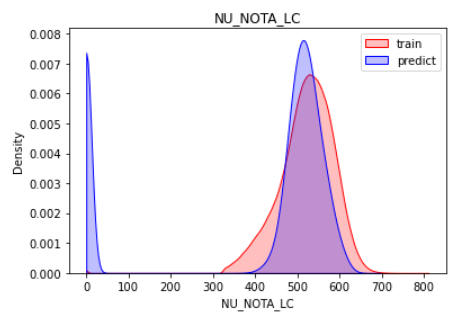
Ciências Humanas
Novas features desenvolvidas especificamente para este modelo:
def fe_ch(df):
df.loc[:, 'FE_RENDA'] = df.loc[:, 'Q006'].map({'A':0, 'B':1000,
'C':1500, 'D':2000, 'E':2500, 'F':3000, 'G':4000, 'H':5000, 'I':6000,
'J':7000, 'K':8000,'L':9000, 'M':10000, 'N':12000, 'O':15000,
'P':20000, 'Q':30000}).astype(int)
df.loc[:, 'FE_NU_IDADE*TP_ANO_CONCLUIU'] = df.TP_ANO_CONCLUIU * df.NU_IDADE
df.loc[:, 'FE_Q002+Q024'] = df.loc[:, 'Q002'].map({'A':0, 'B':1, 'C':2,
'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}).astype(int) +
df.loc[:, 'Q024'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4}).astype(int)
df.loc[:, 'FE_SCORE'] = (1/df.TP_ANO_CONCLUIU) + np.sqrt(df.NU_IDADE) +
np.where(df.TP_ESCOLA==3, 1, 0)
return dfDefinir finalidade de algumas colunas:
# colunas que serao dropadas
to_drop = ['IN_PROVA_DEITADO',
'NU_INSCRICAO',
'CO_MUNICIPIO_ESC',
'CO_UF_NASCIMENTO',
'CO_UF_RESIDENCIA',
'CO_UF_ESC',
'CO_UF_PROVA',
'CO_MUNICIPIO_PROVA',
'CO_MUNICIPIO_RESIDENCIA',
'CO_MUNICIPIO_NASCIMENTO']
# definir target e presenca
target = "NU_NOTA_CH"
presenca = "TP_PRESENCA_CH"
# demais notas para dropar (menos lc)
notas = list(set(targets)-set([target, 'NU_NOTA_LC']))Pré-processamento nos dados de treino
X = train.copy()
X.loc[:, 'knn_feature'] = knn_train.knn_oof
X = X.drop(to_drop, axis=1)
X = X[X[presenca]==1]
X = X[~X[target].isnull()]
X = X.loc[:, ~X.columns.isin([target]+[presenca]+notas)]
X = fe_ch(X)
X = prep_data_questionarios(X)
X = fe_mun(X)
X = fe_questionario(X)
#X = fe_in(X)
X = prep_co_escola(X)
X = fe_extra(X)
y = train.loc[(train[presenca]==1)&(~train[target].isnull()), target].astype(np.float64)Pré-processamento nos dados de teste
X_test = test.copy()
X_test.loc[:, 'knn_feature'] = knn_test.knn_test
X_test = X_test.drop(to_drop, axis=1)
X_test = X_test.loc[:, ~X_test.columns.isin([presenca])]
X_test = fe_ch(X_test)
X_test = prep_data_questionarios(X_test)
X_test = fe_mun(X_test)
X_test = fe_questionario(X_test)
#X_test = fe_in(X_test)
X_test = prep_co_escola(X_test)
X_test = fe_extra(X_test)Feature engineering separada para evitar data leak:
# calcular estatisticas nos dados de treino
co_escola_renda_media = X.groupby('CO_ESCOLA').FE_RENDA.mean()
co_escola_idade_media = X.groupby('CO_ESCOLA').NU_IDADE.mean()
co_escola_nota_lc = X.groupby('CO_ESCOLA').NU_NOTA_LC.mean()
X = X.drop('NU_NOTA_LC', axis=1)
# instanciar objeto com as estatisticas por escola
co_escola_aux = pd.DataFrame({
'CO_ESCOLA': co_escola_renda_media.index,
'FE_ESCOLA_RENDA_MEDIA': co_escola_renda_media,
'FE_IDADE_MEDIA': co_escola_idade_media,
'FE_NOTA_LC': co_escola_nota_lc
}).reset_index(drop=True)
# Concatenar estatisticas nas bases de treino e teste
X = pd.merge(X, co_escola_aux, how='left', on='CO_ESCOLA')
X_test = pd.merge(X_test, co_escola_aux, how='left', on='CO_ESCOLA')
# Codigo da escola para categorico
X.loc[:, 'CO_ESCOLA'] = X.CO_ESCOLA.astype('object').astype('category')
X_test.loc[:, 'CO_ESCOLA'] = X_test.CO_ESCOLA.astype('object').astype('category')
# Features de contagem
X.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X_test.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X.NO_MUNICIPIO_RESIDENCIA.map({x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X_test.NO_MUNICIPIO_RESIDENCIA.map({ x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X.NO_MUNICIPIO_NASCIMENTO.map({ x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X_test.NO_MUNICIPIO_NASCIMENTO.map({x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X.loc[:, 'FE_COUNT_ESCOLA'] = X.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_ESCOLA'] = X_test.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})Ajustar modelo:
%%time
cat_feat = X.columns[X.dtypes=='category']
cat_indices = [X.columns.get_loc(x) for x in cat_feat]
for c in list(cat_feat):
X.loc[:, c] = X.loc[:, c].astype(object).fillna("XXX").astype("category")
X_test.loc[:, c] = X_test.loc[:, c].astype(object).fillna("XXX").astype("category")
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.1, random_state=SEED)
clf = CatBoostRegressor(random_state=314,
cat_features=cat_indices,
verbose=0,
loss_function = "RMSE",
od_type = "Iter",
od_wait = 100,iterations=3000,
use_best_model=True)
clf.fit(X, y, eval_set = (X_eval, y_eval), verbose=False, plot=True)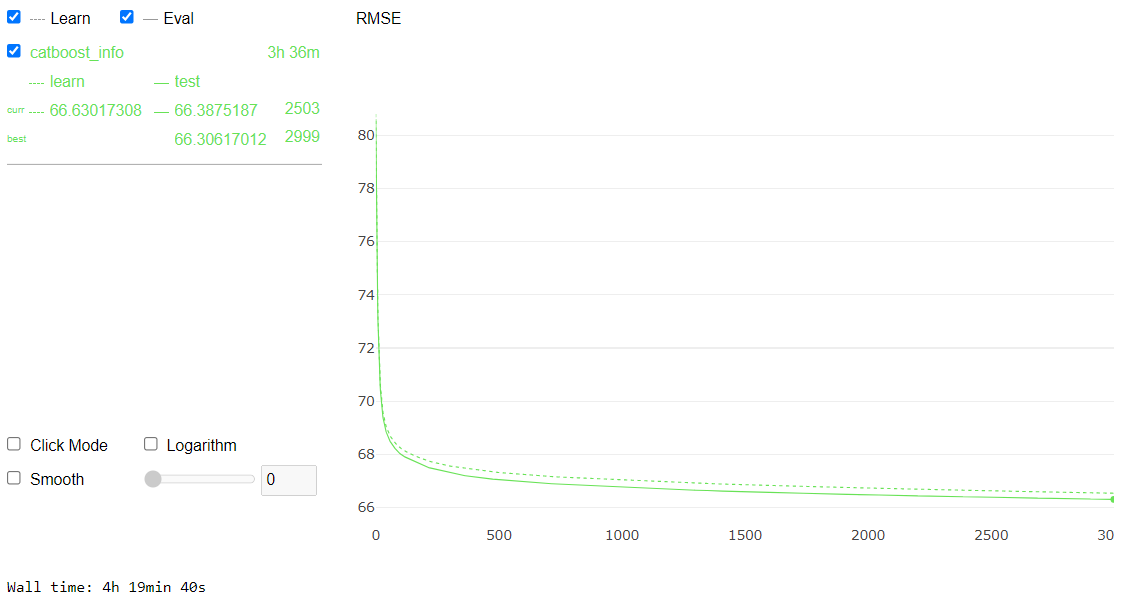
Salvar previsões:
sub.loc[:, 'NU_NOTA_CH'] = clf.predict(X_test)
# alunos que nao foram fazer a prova tiraram zero
sub.loc[test.TP_PRESENCA_CH!=1, 'NU_NOTA_CH'] = 0Comparar distribuição da target nos dados de treino com relação às previsões do modelo:
sns.kdeplot(train.loc[:, target], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, target], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(target)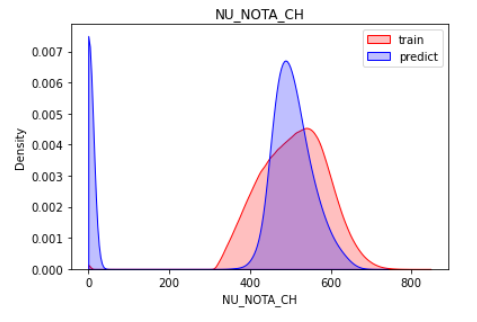
Ciências da Natureza
Novas features desenvolvidas especificamente para este modelo:
def fe_cn(df):
df.loc[:, 'FE_RENDA'] = df.loc[:, 'Q006'].map({'A':0, 'B':1000,
'C':1500, 'D':2000, 'E':2500, 'F':3000, 'G':4000, 'H':5000,
'I':6000, 'J':7000, 'K':8000,'L':9000, 'M':10000, 'N':12000,
'O':15000, 'P':20000, 'Q':30000}).astype(int)
df.loc[:, 'FE_NU_IDADE*TP_ANO_CONCLUIU'] = df.TP_ANO_CONCLUIU * df.NU_IDADE
df.loc[:, 'FE_Q002+Q024'] = df.loc[:, 'Q002'].map({'A':0, 'B':1, 'C':2,
'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}).astype(int) +
df.loc[:, 'Q024'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4}).astype(int)
df.loc[:, 'FE_SCORE'] = (1/df.TP_ANO_CONCLUIU) + np.sqrt(df.NU_IDADE) + np.where(df.TP_ESCOLA==3, 1, 0)
df.loc[:, 'FE_UF_ESCOLA'] = df.SG_UF_ESC.map({
'AM':'Norte', 'RR':'Norte', 'AP':'Norte', 'PA':'Norte', 'TO':'Norte', 'RO':'Norte', 'AC':'Norte',
'MA':'Nordeste', 'PI':'Nordeste', 'CE':'Nordeste', 'RN':'Nordeste', 'PE':'Nordeste', 'PB':'Nordeste', 'SE':'Nordeste', 'AL':'Nordeste', 'BA':'Nordeste',
'MT': 'CentroOeste', 'MS': 'CentroOeste', 'GO': 'CentroOeste',
'SP': 'Sudeste', 'RJ': 'Sudeste', 'ES': 'Sudeste', 'MG': 'Sudeste',
'PR': 'Sul', 'RS': 'Sul', 'SC': 'Sul'}).astype('category')
return dfDefinir finalidade de algumas colunas:
# colunas que serao dropadas
to_drop = ['IN_PROVA_DEITADO',
'NU_INSCRICAO',
'CO_MUNICIPIO_ESC',
'CO_UF_NASCIMENTO',
'CO_UF_RESIDENCIA',
'CO_UF_ESC',
'CO_UF_PROVA',
'CO_MUNICIPIO_PROVA',
'CO_MUNICIPIO_RESIDENCIA',
'CO_MUNICIPIO_NASCIMENTO']
# definir target e presenca
target = "NU_NOTA_CN"
presenca = "TP_PRESENCA_CN"
# demais notas para dropar (menos mt)
notas = list(set(targets)-set([target, 'NU_NOTA_MT']))Pré-processamento nos dados de treino
X = train.copy()
X = X.drop(to_drop, axis=1)
X = X[X[presenca]==1]
X = X[~X[target].isnull()]
X = X.loc[:, ~X.columns.isin([target]+[presenca]+notas)]
X = fe_cn(X)
X = prep_data_questionarios(X)
X = fe_mun(X)
X = fe_questionario(X)
X = fe_in(X)
X = prep_co_escola(X)
X = fe_extra(X)
y = train.loc[(train[presenca]==1)&(~train[target].isnull()), target].astype(np.float64)Pré-processamento nos dados de teste
X_test = test.copy()
X_test = X_test.drop(to_drop, axis=1)
X_test = X_test.loc[:, ~X_test.columns.isin([presenca])]
X_test = fe_cn(X_test)
X_test = prep_data_questionarios(X_test)
X_test = fe_mun(X_test)
X_test = fe_questionario(X_test)
X_test = fe_in(X_test)
X_test = prep_co_escola(X_test)
X_test = fe_extra(X_test)Feature engineering separada para evitar data leak:
# calcular estatisticas nos dados de treino
co_escola_renda_media = X.groupby('CO_ESCOLA').FE_RENDA.mean()
co_escola_idade_media = X.groupby('CO_ESCOLA').NU_IDADE.mean()
co_escola_nota_mt = X.groupby('CO_ESCOLA').NU_NOTA_MT.mean()
X = X.drop('NU_NOTA_MT', axis=1)
# instanciar objeto com as estatisticas por escola
co_escola_aux = pd.DataFrame({
'CO_ESCOLA': co_escola_renda_media.index,
'FE_ESCOLA_RENDA_MEDIA': co_escola_renda_media,
'FE_IDADE_MEDIA': co_escola_idade_media,
'FE_NOTA_MT': co_escola_nota_mt
}).reset_index(drop=True)
# Concatenar estatisticas nas bases de treino e teste
X = pd.merge(X, co_escola_aux, how='left', on='CO_ESCOLA')
X_test = pd.merge(X_test, co_escola_aux, how='left', on='CO_ESCOLA')
# Codigo da escola para categorico
X.loc[:, 'CO_ESCOLA'] = X.CO_ESCOLA.astype('object').astype('category')
X_test.loc[:, 'CO_ESCOLA'] = X_test.CO_ESCOLA.astype('object').astype('category')
# Features de contagem
X.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X_test.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X.NO_MUNICIPIO_RESIDENCIA.map({x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X_test.NO_MUNICIPIO_RESIDENCIA.map({ x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X.NO_MUNICIPIO_NASCIMENTO.map({ x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X_test.NO_MUNICIPIO_NASCIMENTO.map({x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X.loc[:, 'FE_COUNT_ESCOLA'] = X.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_ESCOLA'] = X_test.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})Ajustar modelo:
%%time
cat_feat = X.columns[X.dtypes=='category']
cat_indices = [X.columns.get_loc(x) for x in cat_feat]
for c in list(cat_feat):
X.loc[:, c] = X.loc[:, c].astype(object).fillna("XXX").astype("category")
X_test.loc[:, c] = X_test.loc[:, c].astype(object).fillna("XXX").astype("category")
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.1, random_state=SEED)
clf = CatBoostRegressor(random_state=314,
cat_features=cat_indices,
verbose=0,
loss_function = "RMSE",
od_type = "Iter",
od_wait = 100,iterations=3000,
use_best_model=True)
clf.fit(X, y, eval_set = (X_eval, y_eval), verbose=False, plot=True)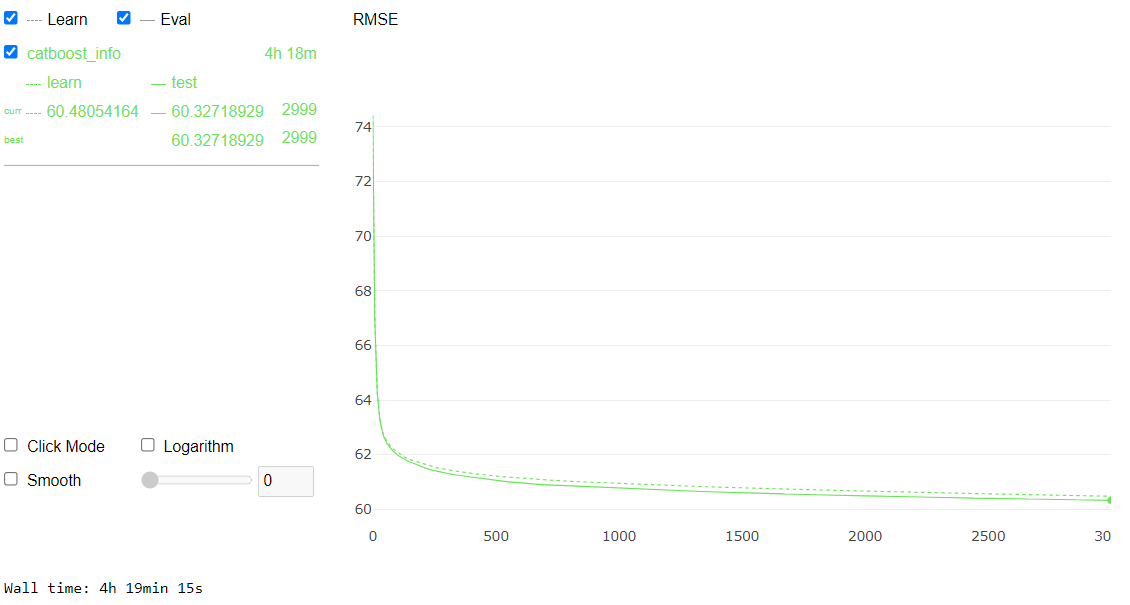
Salvar previsões:
sub.loc[:, 'NU_NOTA_CN'] = clf.predict(X_test)
# alunos que nao foram fazer a prova tiraram zero
sub.loc[test.TP_PRESENCA_CN!=1, 'NU_NOTA_CN'] = 0Comparar distribuição da target nos dados de treino com relação às previsões do modelo:
sns.kdeplot(train.loc[:, target], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, target], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(target)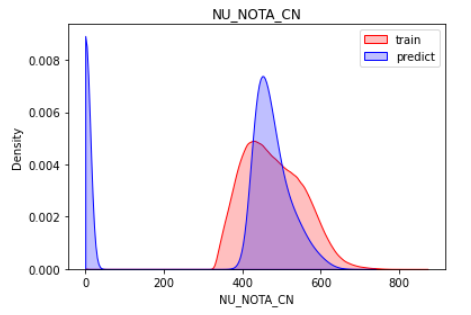
Matemática
Novas features desenvolvidas especificamente para este modelo:
def fe_mt(df):
df.loc[:, 'FE_RENDA'] = df.loc[:, 'Q006'].map({'A':0, 'B':1000, 'C':1500, 'D':2000, 'E':2500, 'F':3000, 'G':4000, 'H':5000, 'I':6000, 'J':7000, 'K':8000,'L':9000, 'M':10000, 'N':12000, 'O':15000, 'P':20000, 'Q':30000}).astype(int)
df.loc[:, 'FE_NU_IDADE*TP_ANO_CONCLUIU'] = df.TP_ANO_CONCLUIU * df.NU_IDADE
df.loc[:, 'FE_Q002+Q024'] = df.loc[:, 'Q002'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}).astype(int) + df.loc[:, 'Q024'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4}).astype(int)
df.loc[:, 'FE_SCORE'] = (1/df.TP_ANO_CONCLUIU) + np.sqrt(df.NU_IDADE) + np.where(df.TP_ESCOLA==3, 1, 0)
df.loc[:, 'FE_UF_ESCOLA'] = df.SG_UF_ESC.map({'AM':'Norte', 'RR':'Norte', 'AP':'Norte', 'PA':'Norte', 'TO':'Norte', 'RO':'Norte', 'AC':'Norte',
'MA':'Nordeste', 'PI':'Nordeste', 'CE':'Nordeste', 'RN':'Nordeste', 'PE':'Nordeste', 'PB':'Nordeste', 'SE':'Nordeste', 'AL':'Nordeste', 'BA':'Nordeste',
'MT': 'CentroOeste', 'MS': 'CentroOeste', 'GO': 'CentroOeste',
'SP': 'Sudeste', 'RJ': 'Sudeste', 'ES': 'Sudeste', 'MG': 'Sudeste',
'PR': 'Sul', 'RS': 'Sul', 'SC': 'Sul'}).astype('category')
return dfDefinir finalidade de algumas colunas:
# colunas que serao dropadas
to_drop = ['IN_PROVA_DEITADO',
'NU_INSCRICAO',
'CO_MUNICIPIO_ESC',
'CO_UF_NASCIMENTO',
'CO_UF_RESIDENCIA',
'CO_UF_ESC',
'CO_UF_PROVA',
'CO_MUNICIPIO_PROVA',
'CO_MUNICIPIO_RESIDENCIA',
'CO_MUNICIPIO_NASCIMENTO']
# definir target e presenca
target = "NU_NOTA_MT"
presenca = "TP_PRESENCA_MT"
# demais notas para dropar (menos cn)
notas = list(set(targets)-set([target, 'NU_NOTA_CN']))Pré-processamento nos dados de treino
X = train.copy()
X = X.drop(to_drop, axis=1)
X = X[X[presenca]==1]
X = X[~X[target].isnull()]
X = X.loc[:, ~X.columns.isin([target]+[presenca]+notas)]
X = fe_mt(X)
X = prep_data_questionarios(X)
X = fe_mun(X)
#X = fe_questionario(X)
#X = fe_in(X)
X = prep_co_escola(X)
X = fe_extra(X)
y = train.loc[(train[presenca]==1)&(~train[target].isnull()), target].astype(np.float64)Pré-processamento nos dados de teste
X_test = test.copy()
X_test = X_test.drop(to_drop, axis=1)
X_test = X_test.loc[:, ~X_test.columns.isin([presenca])]
X_test = fe_mt(X_test)
X_test = prep_data_questionarios(X_test)
X_test = fe_mun(X_test)
#X_test = fe_questionario(X_test)
#X_test = fe_in(X_test)
X_test = prep_co_escola(X_test)
X_test = fe_extra(X_test)Feature engineering separada para evitar data leak:
# calcular estatisticas nos dados de treino
co_escola_renda_media = X.groupby('CO_ESCOLA').FE_RENDA.mean()
co_escola_idade_media = X.groupby('CO_ESCOLA').NU_IDADE.mean()
co_escola_nota_cn = X.groupby('CO_ESCOLA').NU_NOTA_CN.mean()
X = X.drop('NU_NOTA_CN', axis=1)
# instanciar objeto com as estatisticas por escola
co_escola_aux = pd.DataFrame({
'CO_ESCOLA': co_escola_renda_media.index,
'FE_ESCOLA_RENDA_MEDIA': co_escola_renda_media,
'FE_IDADE_MEDIA': co_escola_idade_media,
'FE_NOTA_CN': co_escola_nota_cn
}).reset_index(drop=True)
# Concatenar estatisticas nas bases de treino e teste
X = pd.merge(X, co_escola_aux, how='left', on='CO_ESCOLA')
X_test = pd.merge(X_test, co_escola_aux, how='left', on='CO_ESCOLA')
# Codigo da escola para categorico
X.loc[:, 'CO_ESCOLA'] = X.CO_ESCOLA.astype('object').astype('category')
X_test.loc[:, 'CO_ESCOLA'] = X_test.CO_ESCOLA.astype('object').astype('category')
# Features de contagem
X.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X_test.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X.NO_MUNICIPIO_RESIDENCIA.map({x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X_test.NO_MUNICIPIO_RESIDENCIA.map({ x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X.NO_MUNICIPIO_NASCIMENTO.map({ x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X_test.NO_MUNICIPIO_NASCIMENTO.map({x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X.loc[:, 'FE_COUNT_ESCOLA'] = X.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_ESCOLA'] = X_test.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})Ajustar modelo:
%%time
cat_feat = X.columns[X.dtypes=='category']
cat_indices = [X.columns.get_loc(x) for x in cat_feat]
for c in list(cat_feat):
X.loc[:, c] = X.loc[:, c].astype(object).fillna("XXX").astype("category")
X_test.loc[:, c] = X_test.loc[:, c].astype(object).fillna("XXX").astype("category")
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.1, random_state=SEED)
clf = CatBoostRegressor(random_state=314,
cat_features=cat_indices,
verbose=0,
loss_function = "RMSE",
od_type = "Iter",
od_wait = 100,iterations=3000,
use_best_model=True)
clf.fit(X, y, eval_set = (X_eval, y_eval), verbose=False, plot=True)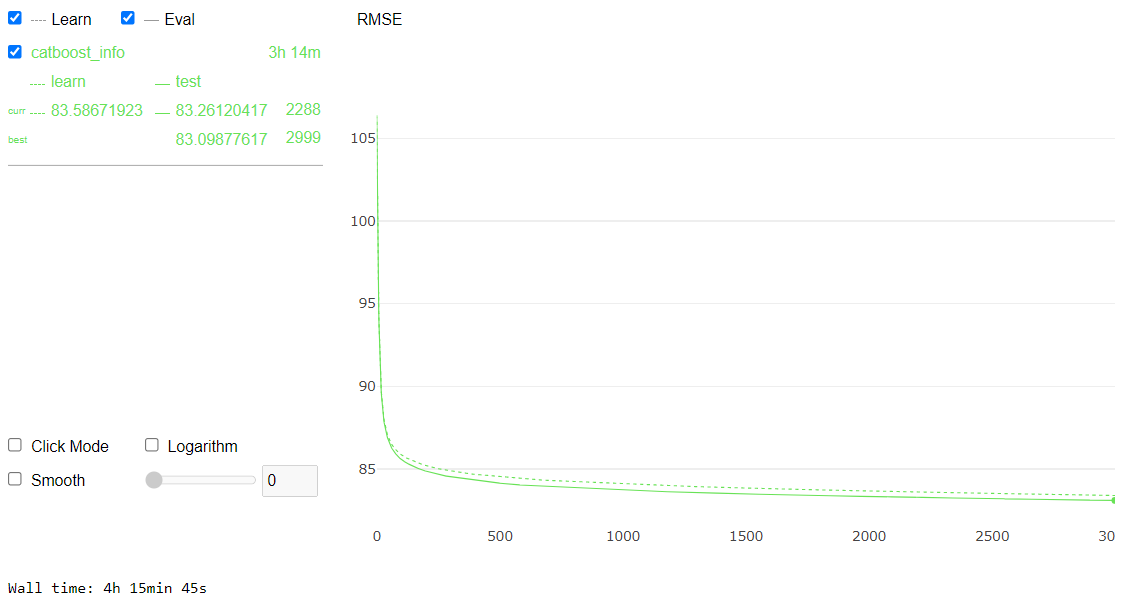
Salvar previsões:
sub.loc[:, 'NU_NOTA_MT'] = clf.predict(X_test)
# alunos que nao foram fazer a prova tiraram zero
sub.loc[test.TP_PRESENCA_CN!=1, 'NU_NOTA_MT'] = 0Comparar distribuição da target nos dados de treino com relação às previsões do modelo:
sns.kdeplot(train.loc[:, target], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, target], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(target)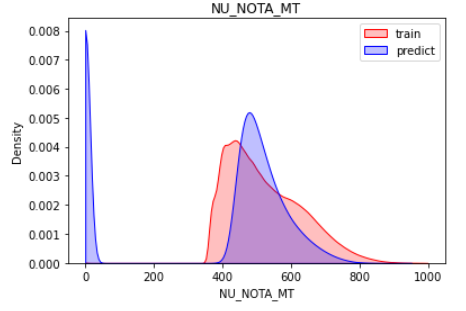
Redação
Novas features desenvolvidas especificamente para este modelo:
def fe_rd(df):
df.loc[:, 'FE_RENDA'] = df.loc[:, 'Q006'].map({'A':0, 'B':1000, 'C':1500, 'D':2000, 'E':2500, 'F':3000, 'G':4000, 'H':5000, 'I':6000, 'J':7000, 'K':8000,'L':9000, 'M':10000, 'N':12000, 'O':15000, 'P':20000, 'Q':30000}).astype(int)
df.loc[:, 'FE_NU_IDADE*TP_ANO_CONCLUIU'] = df.TP_ANO_CONCLUIU * df.NU_IDADE
df.loc[:, 'FE_Q002+Q024'] = df.loc[:, 'Q002'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F': 5, 'G': 6, 'H': -1}).astype(int) + df.loc[:, 'Q024'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4}).astype(int)
df.loc[:, 'FE_SCORE'] = (1/df.TP_ANO_CONCLUIU) + np.sqrt(df.NU_IDADE) + np.where(df.TP_ESCOLA==3, 1, 0)
df.loc[:, 'FE_RENDA_FAMILIA_+_IDADE'] = df.loc[:, 'Q006'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F':5, 'G':6, 'H':7, 'I':8, 'J':9, 'K':10,'L':11, 'M':12, 'N':13, 'O':14, 'P':15, 'Q':16}).astype(int) + df.NU_IDADE
df.loc[:, 'FE_RENDA_FAMILIA_+_ANO_CONCLUIU'] = df.loc[:, 'Q006'].map({'A':0, 'B':1, 'C':2, 'D':3, 'E':4, 'F':5, 'G':6, 'H':7, 'I':8, 'J':9, 'K':10,'L':11, 'M':12, 'N':13, 'O':14, 'P':15, 'Q':16}).astype(int)+ df.TP_ANO_CONCLUIU
return dfDefinir finalidade de algumas colunas:
# colunas que serao dropadas
to_drop = ['IN_PROVA_DEITADO',
'NU_INSCRICAO',
'CO_MUNICIPIO_ESC',
'CO_UF_NASCIMENTO',
'CO_UF_RESIDENCIA',
'CO_UF_ESC',
'CO_UF_PROVA',
'CO_MUNICIPIO_PROVA',
'CO_MUNICIPIO_RESIDENCIA',
'CO_MUNICIPIO_NASCIMENTO']
# definir target e presenca
target = "NU_NOTA_REDACAO"
presenca = "TP_STATUS_REDACAO"
# demais notas para dropar
notas = list(set(targets)-set([target]))Pré-processamento nos dados de treino
X = train.copy()
X = X.drop(to_drop, axis=1)
X = X[X[presenca]==1]
X = X[~X[target].isnull()]
X = X.loc[:, ~X.columns.isin([target]+[presenca]+notas)]
X = fe_rd(X)
X = prep_data_questionarios(X)
X = fe_mun(X)
#X = fe_questionario(X)
X = fe_in(X)
X = prep_co_escola(X)
X = fe_extra(X)
y = train.loc[(train[presenca]==1)&(~train[target].isnull()), target].astype(np.float64)Pré-processamento nos dados de teste
X_test = test.copy()
X_test = X_test.drop(to_drop, axis=1)
X_test = X_test.loc[:, ~X_test.columns.isin([presenca])]
X_test = fe_rd(X_test)
X_test = prep_data_questionarios(X_test)
X_test = fe_mun(X_test)
#X_test = fe_questionario(X_test)
X_test = fe_in(X_test)
X_test = prep_co_escola(X_test)
X_test = fe_extra(X_test)Feature engineering separada para evitar data leak:
# calcular estatisticas nos dados de treino
co_escola_renda_media = X.groupby('CO_ESCOLA').FE_RENDA.mean()
co_escola_idade_media = X.groupby('CO_ESCOLA').NU_IDADE.mean()
# instanciar objeto com as estatisticas por escola
co_escola_aux = pd.DataFrame({
'CO_ESCOLA': co_escola_renda_media.index,
'FE_ESCOLA_RENDA_MEDIA': co_escola_renda_media,
'FE_IDADE_MEDIA': co_escola_idade_media
}).reset_index(drop=True)
# Concatenar estatisticas nas bases de treino e teste
X = pd.merge(X, co_escola_aux, how='left', on='CO_ESCOLA')
X_test = pd.merge(X_test, co_escola_aux, how='left', on='CO_ESCOLA')
# Codigo da escola para categorico
X.loc[:, 'CO_ESCOLA'] = X.CO_ESCOLA.astype('object').astype('category')
X_test.loc[:, 'CO_ESCOLA'] = X_test.CO_ESCOLA.astype('object').astype('category')
# Features de contagem
X.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_PROVA'] = X_test.NO_MUNICIPIO_PROVA.map({x: y for x, y in zip(X.NO_MUNICIPIO_PROVA.value_counts().index.values, X.NO_MUNICIPIO_PROVA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X.NO_MUNICIPIO_RESIDENCIA.map({x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_RESIDENCIA'] = X_test.NO_MUNICIPIO_RESIDENCIA.map({ x: y for x, y in zip(X.NO_MUNICIPIO_RESIDENCIA.value_counts().index.values, X.NO_MUNICIPIO_RESIDENCIA.value_counts().values)})
X.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X.NO_MUNICIPIO_NASCIMENTO.map({ x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X_test.loc[:, 'FE_COUNT_MUNICIPIO_NASCIMENTO'] = X_test.NO_MUNICIPIO_NASCIMENTO.map({x: y for x, y in zip(X.NO_MUNICIPIO_NASCIMENTO.value_counts().index.values, X.NO_MUNICIPIO_NASCIMENTO.value_counts().values)})
X.loc[:, 'FE_COUNT_ESCOLA'] = X.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})
X_test.loc[:, 'FE_COUNT_ESCOLA'] = X_test.CO_ESCOLA.map({x: y for x, y in zip(X.CO_ESCOLA.value_counts().index.values, X.CO_ESCOLA.value_counts().values)})Ajustar modelo:
%%time
cat_feat = X.columns[X.dtypes=='category']
cat_indices = [X.columns.get_loc(x) for x in cat_feat]
for c in list(cat_feat):
X.loc[:, c] = X.loc[:, c].astype(object).fillna("XXX").astype("category")
X_test.loc[:, c] = X_test.loc[:, c].astype(object).fillna("XXX").astype("category")
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.1, random_state=SEED)
clf = CatBoostRegressor(random_state=314,
cat_features=cat_indices,
verbose=0,
loss_function = "RMSE",
od_type = "Iter",
od_wait = 100,iterations=3000,
use_best_model=True)
clf.fit(X, y, eval_set = (X_eval, y_eval), verbose=False, plot=True)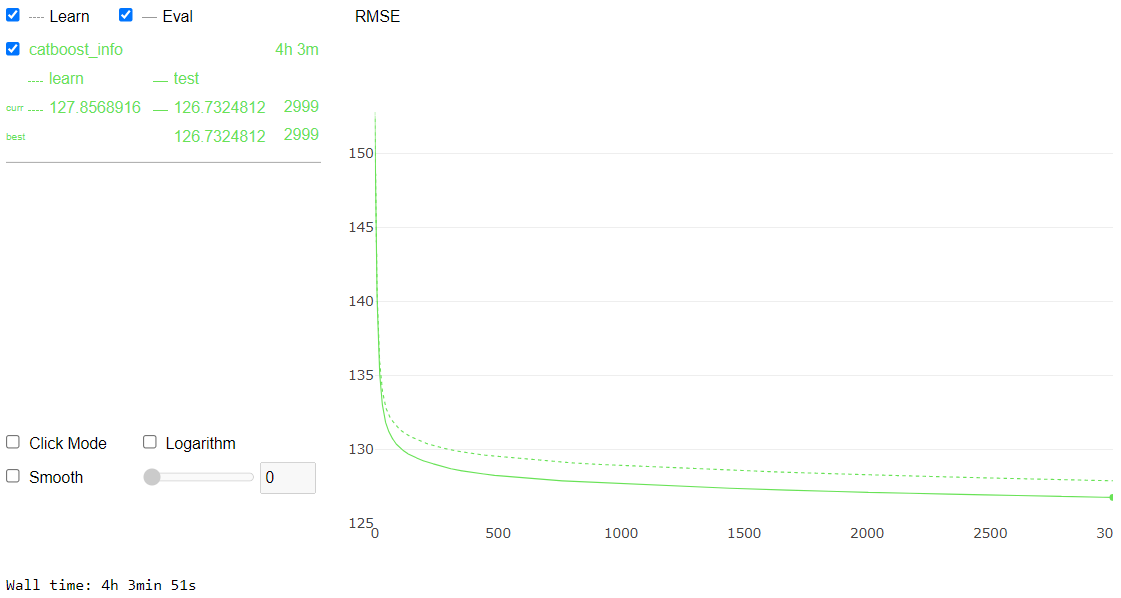
Salvar previsões:
sub.loc[:, 'NU_NOTA_REDACAO'] = clf.predict(X_test)
# alunos que nao foram fazer a prova tiraram zero
sub.loc[test.TP_STATUS_REDACAO!=1, 'NU_NOTA_REDACAO'] = 0Comparar distribuição da target nos dados de treino com relação às previsões do modelo:
sns.kdeplot(train.loc[:, target], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, target], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(target)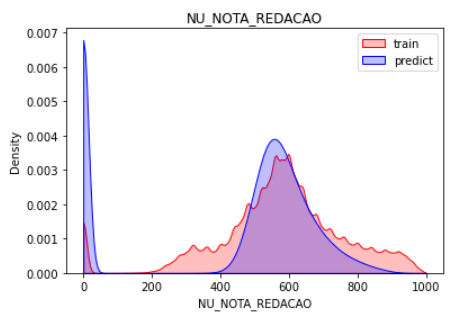
Submissão
Veja a seguir como ficou a distribuição das previsões comparada à distribuição da target nos dados de treino:
plt.figure(figsize=(16, 5))
notas = ['NU_NOTA_CH', 'NU_NOTA_CN', 'NU_NOTA_MT', 'NU_NOTA_LC', 'NU_NOTA_REDACAO']
for i in range(len(notas)):
plt.subplot(1, 5, i+1)
sns.kdeplot(train.loc[:, notas[i]], shade=True, color='r', clip=[0,1000])
sns.kdeplot(sub.loc[:, notas[i]], shade=True, color='b', clip=[0,1000])
plt.legend(labels=['train', 'predict'])
plt.title(notas[i])
plt.tight_layout()
plt.show()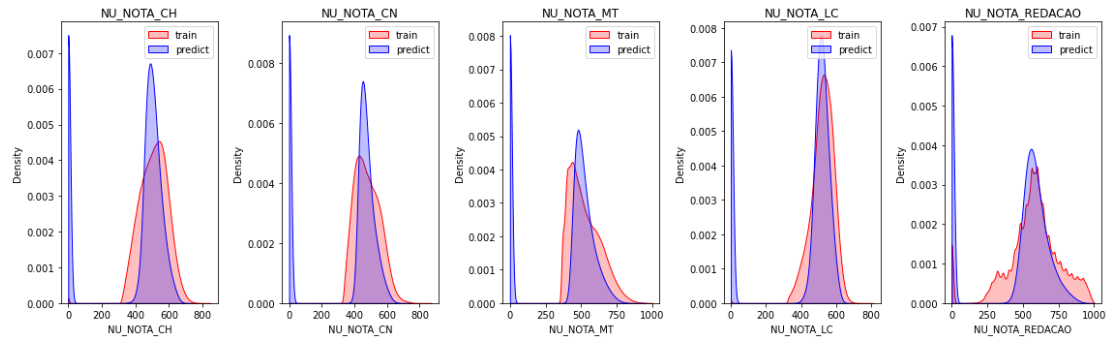
Acredito que talvez um tuning do modelo poderia trazer mais qualidade às previsões mas com o tempo limitado não pude investir muito nesta etapa.
Considerações Finais
Em resumo, essas foram as principais idéias para a solução da competição e acredito que um dos segredos era focar em feature engineering por 2 motivos:
- A base era muito grande e o processo de tuning seria muito custoso (a não ser que tenha um ótimo computador a disposição);
- Os atributos não eram anônimos, o que dá muita informação de contexto.
Agradeço aos organizadores e à todos os participantes que tornaram esta competição tão divertida! Por mais competições como esta, que valorizam a comunidade brasileira de Data Science!
Espero que tenham gostado e até logo!
Abraços!
Fellipe Gomes


Share this post
Twitter
LinkedIn
Email