




































Vou te provar que da para fazer Grafos bonitos em R!
Neste post vamos coletar notícias via web scrapping, detectar entidades dos textos e criar um grafo utilizando ggplot2

Introdução e contexto
Durante os anos de 2020 e 2021 fiz um MBA Executivo em Business Analytics e Big Data na FGV e uma das disciplinas que gostei bastante abordou a análise de mídias sociais com técnicas de mineração de texto e processamento de linguagem natural.
No trabalho final fomos desafiados a extrair dados da internet via api ou scraping, aplicar a metodologia apropriada para extrair informações de interesse e contruir um Grafo.
Como esse gráfico deu mais de trabalho do que eu esperava e fiquei bem satisfeito com o resultado final, resolvi fazer uma nova análise para praticar e publicar aqui no blog, espero que gostem!
O que são Grafos?
📎 Segundo o Wikipedia:
“A teoria dos grafos é um ramo da matemática que estuda as relações entre os objetos de um determinado conjunto”
São muito úteis para análises de redes sociais, redes de amizades ou qualquer rede com relações de dependências. Existem muitos tipos de grafos como conectados, desconectados, esparsos, densos, direcionados, não direcionados e por ai vai…
Além disso existe toda uma nomenclatura específica, mas não entrarei em detalhes teóricos neste post pois também estou estudado sobre o tema! Caso queira aprofundar na teoria por trás recomendo este material gratuito muito bom!
Como contruir um?
No curso que fiz aprendemos a mexer no Gephi para a contrução desses Grafos (ferramenta incrível, diga-se de passagem) porém ouvi dizer diversas vezes, tanto dentro quanto fora da FGV, que R e Python eram muito limitados para construção de Grafos bonitos e que esse software sempre a melhor opção.
Apesar do enorme potencial do Gephi, fiquei um pouco entediado estudando-o pois não sou grande fã de ferramentas point-and-click e quando o professor falou que a escolha da ferramenta para a construção do Grafo era livre, resolvi tentar fazê-lo em R!
Carregar dependências
Pacotes utilizados neste post:
library(rvest) # web scrapping
library(dplyr) # manipulate data
library(purrr) # functional prog
library(stringr) # str toolkit
library(spacyr) # ner
library(igraph) # base graph
library(tidygraph) # tidy graph
library(ggraph) # plot graphFonte dos dados
Os dados utilizados neste post foram coletados via web scrapping do site do G1 - Globo. Optei por trabalhar com textos jornalísticos neste post pois apresentam a vantagem de serem bem escritos, o que facilita na tarefa de mineração de texto.
Também fiz um grafo analisando tweets sobre a CPI da pandemia que será apresentado como bônus no final deste post e para quem tiver curiosidade de conferir os códigos vai notar que foi necessário um tratamento muito mais extensivo para corrigir os nomes de cada um dos senadores, deputados e personagens políticos detectados.
Confira abaixo todos os códigos necessários para realizar tal extração:
(Clique aqui para exibir as funções scrape_post_links e scrape_post_body )
# Funcao para coletar os links de cada noticia
scrape_post_links <- function(site) {
cat(paste0(site, "\n"))
source_html <- read_html(site)
links <- source_html %>%
html_nodes("div.widget--info__text-container") %>%
html_nodes("a") %>%
html_attr("href")
links <- links[!is.na(links)]
return(links)
}
# Funcao para coletar o texto da materia em cada link
scrape_post_body <- function(site) {
text <- tryCatch({
cat(paste0(site, "\n"))
body <- site %>%
read_html %>%
html_nodes("article") %>%
html_nodes("p.content-text__container") %>%
html_text %>%
paste(collapse = '')
}, error = function(e){
cat(paste("ERRO 404", "\n"))
body <- NA
})
return(body)
}
# criar matriz de adjacencias
get_adjacent_list <- function(edge_list) {
gtools::combinations(length(edge_list), 2, edge_list)
}
# raiz
root <- "https://g1.globo.com/busca/?q=economia+brasil"
# gerar links das proximas 100 paginas
all_pages <- c(root, paste0(root, "&page=", 1:50))
# coletar os links dos posts de cada pagina
all_links <- map(all_pages, scrape_post_links) %>% unlist()
# extrair urls
cleaned_links <- map_chr(all_links, ~{
.x %>%
urltools::param_get() %>%
pull(u) %>%
urltools::url_decode()
})
# reter apenas links que falam de economia
cleaned_links <- cleaned_links %>% .[str_detect(., "g1.globo.com/economia")]
# nao reter links do globoplay
cleaned_links <- cleaned_links %>% .[!str_detect(., "globoplay")]
# coletar conteudo de cada link
data <- map_chr(cleaned_links, scrape_post_body) %>% unique()NER - Named Entity Recognition
Utilizaremos um modelo de reconhecimento de entidades pré-treinado fornecido pela Spacy (que fornece essa e muitas outras soluções interessantes quando se trata de processamento de linguagem natural).
Primeiramente vamos configurar o spacyr na máquina para utilizar o modelo pré treinado para reconhecimento de entidades em português:
# Executar apenas 1 vez
spacyr::spacy_install()
spacy_download_langmodel("pt_core_news_sm")Inicializar modelo pré-treinado em português:
spacy_initialize(model="pt_core_news_sm")Aplicar modelo carregado para o reconhecimento de entidades:
entities <- spacy_extract_entity(data)Filtrar apenas entidades cujo tipo são pessoas ou organizações:
filtered_entities <-
entities %>%
filter(ent_type=='ORG'| ent_type=='PER')Preparar dados
Precisamos criar uma lista de arestas:
edges <-
filtered_entities %>%
group_by(doc_id) %>%
summarise(entities = paste(text, collapse = ",")) %>%
pull(entities) %>%
str_split(",") %>%
map(~unique(unlist(.x))) %>%
.[map_dbl(., length) != 1]Agora criaremos a matriz de adjacências, que envolvem todas as combinações 2 a 2 das entidades detectadas em cada notícia:
adjacent_matrix <-
map_dfr(edges, ~ as.data.frame(get_adjacent_list(.x))) %>%
as_tibble() %>%
set_names(c('item1', 'item2'))Aplicaremos algum tratamento para padronizar as entidades, reter apenas combinações que aconteceram pelo menos 3 vezes e remover algum resíduo que veio no processo de NER:
# Padronizar entidades
adjacent_matrix <- adjacent_matrix %>%
mutate_all(~.x %>%
str_replace_all("Fundação Getulio Vargas", "FGV") %>%
str_replace_all("FMI", "Fundo Monetário Internacional") %>%
str_replace_all("Paulo Guedes", "Guedes") %>%
str_replace_all("Estados Unidos( da Am[ée]rica)?", "EUA") %>%
str_replace_all("Donald Trump", "Trump") %>%
str_replace_all("CEF", "Caixa Econômica Federal") %>%
str_replace_all("CMN", "Conselho Monetário Nacional") %>%
str_replace_all("Cl[áa]udio Considera", "Cláudio") %>%
str_replace_all("OCDE", "Organização para a Cooperação e
Desenvolvimento Econômico") %>%
str_replace_all("(André )?Brandão", "André Brandão") %>%
str_replace_all("(Maur[ií]cio )?Macri", "Mauricio Macri") %>%
str_remove_all("^(?i)(no|de)\\s")
)
# remover residuos
{
entities_to_drop <- c("Assine", "Google Podcasts", "Spotify", "Focus do",
"Focus", "Segundo", "Ninguém", "Haverá", "G1",
"Começa", "LEIA", "R$", "Considera", "Caixa Aqui")
weighted_edgelist <- adjacent_matrix %>%
filter_at(1:2, ~ !.x %in% entities_to_drop) %>%
group_by(item1, item2) %>%
summarise(n=n()) %>%
ungroup() %>%
filter(n>3)
}Definir alguns objetos para o grafo:
# Instanciar objeto das setas
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
# Definir pesos conforme numero de ocorrencias
subt <- weighted_edgelist
# Instanciar objeto dos vertices
vert <- subt %>%
tidyr::gather(item, word, item1, item2) %>%
group_by(word) %>%
summarise(n = sum(n))
# Obter componentes para colorir os clusters do grafo
tidy_graph_components <-
subt %>%
select(item1, item2) %>%
as.matrix() %>%
graph.edgelist(directed = FALSE) %>%
as_tbl_graph() %>%
activate("edges") %>%
# definir pesos como numero de ocorrencias
mutate(weight = subt$n) %>%
activate("nodes") %>%
# obter clusters:
mutate(component = as.factor(tidygraph::group_edge_betweenness()))
# outros tipos de agrupamentos:
# tidygraph.data-imaginist.com/reference/group_graph.html
# Atualizar vertice para incluir grupos
vert <- vert %>%
left_join( as.data.frame(activate(tidy_graph_components, "nodes")) %>%
rename(word = name))Finalmente, vamos criar o grafo utilizando ggplot2:
set.seed(1)
subt %>%
graph_from_data_frame(vertices = vert) %>%
# https://www.data-imaginist.com/2017/ggraph-introduction-layouts/ # layouts
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n), show.legend = FALSE,
arrow = a, end_cap = circle(.07, 'inches'), color = "#D9D9D9A0") +
geom_node_point() +
geom_node_text(aes(label = name, size = n, alpha = n, color = component),# color = "#EAFF00",
repel = TRUE, point.padding = unit(0.2, "lines"),
show.legend = F) +
scale_size(range = c(2,10)) +
scale_alpha(range = c(0.5,1))+
theme_dark() +
theme(
panel.background = element_rect(fill = "#2D2D2D"),
legend.key = element_rect(fill = "#2D2D2D")
) +
theme_graph(background = "black")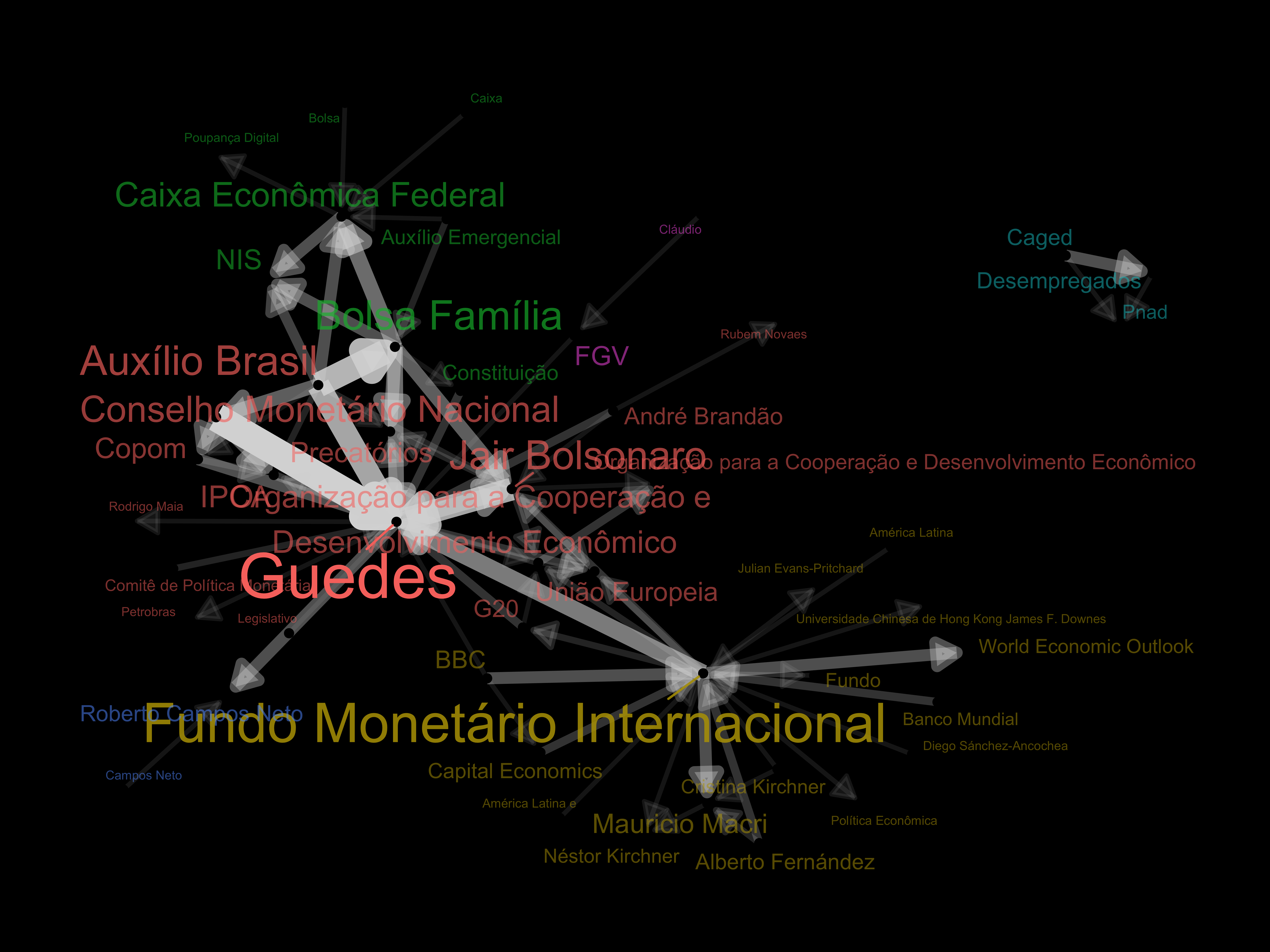
📌 Interpretação
Este grafo resume algumas informações interessantes sobre como o cenário da economia no brasil estava no dia 30 de novembro de 2021. Vejamos alguns pontos relevantes que podem ser envontrados no cenário atual:
☞ Bolsa familia
O Auxílio Brasil é referido como o “Novo Bolsa Família” pelos jornais e por isso deve ter sido criada tal relação no Grafo. Já a Caixa Econômica Federal é o agente que executa os pagamentos.
☞ Guedes
Paulo Guedes é nosso atual ministro da economia e envolta de seu nome aparecem diversos assuntos que estão em pauta atualmente como a PEC dos precatórios, (a privatização da) Petrobrás, Copom, IPCA, Auxílio Brasil dentre outros.
☞ Fundo Monetário Internacional
O FMI trabalha para melhorar as economias dos países e além da Argentina estar endividada e em acordo com o FMI, é época de eleição, o que explica haver alguns personagens de sua política relacionados.
Salvar localmente em alta resolução:
ggsave(filename = 'grafo.png', width = 8, height = 6, device='png', dpi=700)O legal de salvar em alta resolução é poder dar zoom e navegar pelo grafo!
Bônus
Antes de criar este post trabalhei em um outro grafo com banco de dados de aproximadamente 27GB de tweets coletados e fornecidos gentilmente pelo Janderson Toth (Para quem não o conheçe, recomendo fortemente segui-lo no linkedin pois ele tem compartilhado uma série de posts com insights obtidos destes dados!)
Para quem tiver interesse, o código está disponível no github!
Conclusão
Convenhamos que, de fato, criar um grafo no R não é uma tarefa super simples. No Gelphi é possível criar grafos até mais bonitos que este, porém, no longo prazo, ganhamos em produtividade e em escalabilidade pois poderíamos reaproveitar muito código e tranquilamente desenvolver uma rotina para criar novos grafos a partir de dados streaming, por exemplo, automatizando todo o processo!
Outras bibliotecas para construção de grafos
Depois de conversar com algumas pessoas que leram o post, achei que merecia um update com mais idéias de mais bibliotecas que poderiam ter sido utilizadas:


Share this post
Twitter
LinkedIn
Email