




































Manipulação de Strings e Text Mining
Algumas dicas e truques úteis de pacotes especiais para a manipulação e tratamento de strings

Manipulação de strings e Text mining
Estudamos números e mais números na graduação de estatística (não sei nem se ainda consigo enxergar algarismos gregos como letras) e mesmo assim um problema frequente na vida de quem trabalha com dados é a manipulação de variáveis do tipo string.
Uma variável do tipo string é uma variável do tipo texto e esse tipo de objeto costuma causar alguns problemas na análise de dados se não forem devidamente tratados.
Desde modificações em nomes de colunas em data.frames até as mais espertas aplicações de text mining com corpus, a limpeza e manipulação de strings é quase sempre necessária
Criando funções
Antes de apresentar alguns pacotes com funções úteis para manipular strings, gostaria de comentar que pode ser bem útil desenvolvermos funções para nosso próprio uso, não é raro realizarmos o mesmo procedimento em diferentes etapas das análises, o que pode tornar o código desorganizado ou poluído com tantas linhas repetidas.
Trago aqui de exemplo uma função que encontrei recentemente para remover acentos no stackoverflow que já me ajudou bastante, veja a função:
rm_accent <- function(str,pattern="all") {
# Rotinas e funções úteis V 1.0
# rm.accent - REMOVE ACENTOS DE PALAVRAS
# Função que tira todos os acentos e pontuações de um vetor de strings.
# Parâmetros:
# str - vetor de strings que terão seus acentos retirados.
# patterns - vetor de strings com um ou mais elementos indicando quais acentos deverão ser retirados.
# Para indicar quais acentos deverão ser retirados, um vetor com os símbolos deverão ser passados.
# Exemplo: pattern = c("´", "^") retirará os acentos agudos e circunflexos apenas.
# Outras palavras aceitas: "all" (retira todos os acentos, que são "´", "`", "^", "~", "¨", "ç")
if(!is.character(str))
str <- as.character(str)
pattern <- unique(pattern)
if(any(pattern=="Ç"))
pattern[pattern=="Ç"] <- "ç"
symbols <- c(
acute = "áéíóúÁÉÍÓÚýÝ",
grave = "àèìòùÀÈÌÒÙ",
circunflex = "âêîôûÂÊÎÔÛ",
tilde = "ãõÃÕñÑ",
umlaut = "äëïöüÄËÏÖÜÿ",
cedil = "çÇ"
)
nudeSymbols <- c(
acute = "aeiouAEIOUyY",
grave = "aeiouAEIOU",
circunflex = "aeiouAEIOU",
tilde = "aoAOnN",
umlaut = "aeiouAEIOUy",
cedil = "cC"
)
accentTypes <- c("´","`","^","~","¨","ç")
if(any(c("all","al","a","todos","t","to","tod","todo")%in%pattern)) # opcao retirar todos
return(chartr(paste(symbols, collapse=""), paste(nudeSymbols, collapse=""), str))
for(i in which(accentTypes%in%pattern))
str <- chartr(symbols[i],nudeSymbols[i], str)
return(str)
}Criar nossas próprias funções é muito simples em R e eu encorajo a todos a começarem a trabalhar com funções próprias também (além das nativas do R), pois o programa fica muito mais dinâmico e limpo.
O pacote stringr
Além do pacote dplyr, mais uma vez Hadley Wickham trás uma solução bastante útil para facilitar nossa vida de programador estatístico (ou cientista de dados se preferir, seguindo as “tendências da moda” de “data scientist”) com o pacote stringr, que possui uma sintaxe consistente, permitindo a manipulação de textos com muito mais facilidade.
Seu uso consiste em uma variedade de utilidades que podem ser consultadas diretamente de dentro do R ao escrever str_ (após carregar o pacote) e aguardar um instante que a seguinte lista de funções será exibida:

Note que essa aplicação funciona para qualquer pacote do R
Portanto, inicialmente vamos carregar o pacote:
library(stringr)Com o pacote carregado já podemos fazer o uso de algumas das funções que são bem úteis.
Arrumando titulos de base de dados
É muito comum que os cabeçalhos de uma base de dados venha repleta de caracteres especiais como este exemplo:
nomes=c('Aniversário', 'Situação', 'Raça', 'IMC', 'Tipo físico', 'tabaco por dia (cig/dia)', 'Alcool (dose/semana)', 'Drogas/g', 'Café/dia', 'Suco/dia');nomes## [1] "Aniversário" "Situação"
## [3] "Raça" "IMC"
## [5] "Tipo físico" "tabaco por dia (cig/dia)"
## [7] "Alcool (dose/semana)" "Drogas/g"
## [9] "Café/dia" "Suco/dia"Unindo as funções deste pacote com a sintaxe do pacote dplyr podemos elaborar uma função que irá facilitar bastante nas chamadas das colunas do data.frame na hora da análise, veja:
ajustar_nomes=function(x){
x%>%
stringr::str_trim() %>% #Remove espaços em branco sobrando
stringr::str_to_lower() %>% #Converte todas as strings para minusculo
rm_accent() %>% #Remove os acentos com a funcao criada acima
stringr::str_replace_all("[/' '.()]", "_") %>% #Substitui os caracteres especiais por "_"
stringr::str_replace_all("_+", "_") %>% #Substitui os caracteres especiais por "_"
stringr::str_replace("_$", "") #Substitui o caracter especiais por "_"
}
nomes=ajustar_nomes(nomes)
nomes## [1] "aniversario" "situacao" "raca"
## [4] "imc" "tipo_fisico" "tabaco_por_dia_cig_dia"
## [7] "alcool_dose_semana" "drogas_g" "cafe_dia"
## [10] "suco_dia"Função str_replace() e str_replace_all()
Esse é o tipo de função que é utilizada com frequência. Utilizada para substituir ou remover uma (ou todas) as ocorrências de determinado carácter no objeto, suponha a seguinte situação:
exemplo <- c("o esperto", "o doido", "o normal")Para remover a primeira vogal de cada string:
str_replace(exemplo, "[aeiou]", "") ## [1] " esperto" " doido" " normal"Para substitui todas as vogais por "_"
str_replace_all(exemplo, "[aeiou]", "_") ## [1] "_ _sp_rt_" "_ d__d_" "_ n_rm_l"Considere este novo exemplo:
exemplo2 <- "O- ffffzx2, faifavuvuifoovvv fovvo"Para substitui o primeiro f (ou f’s) por “v”:
exemplo2 <- str_replace(exemplo2, "f+", "v")
exemplo2## [1] "O- vzx2, faifavuvuifoovvv fovvo"Para substituir todos os v’s (em sequência ou não) por “c”:
exemplo2 <- str_replace_all(exemplo2, "v+", "c")
exemplo2## [1] "O- czx2, faifacucuifooc foco"Função str_split() e str_split_fixed()
Essas funções separam uma string em várias de acordo com um separador.
frase <- 'Analisar palavras é muito legal. Apesar de todos os desafios as informações que podemos extrair podem revelar informações incrívelmente úteis. Esse exemplo esta sendo escrito pois vamos retirar cada frase desse paragrafo separadamente.'
str_split(frase, fixed('.'))## [[1]]
## [1] "Analisar palavras é muito legal"
## [2] " Apesar de todos os desafios as informações que podemos extrair podem revelar informações incrívelmente úteis"
## [3] " Esse exemplo esta sendo escrito pois vamos retirar cada frase desse paragrafo separadamente"
## [4] ""Função str_sub()
Para obter uma parte fixa de uma string podemos utilizar o comando str_sub() da seguinte maneira:
#Suponha as seguintes palavras:
words=c("00-casados", "01-casamento", "02-emprego", "03-empregado")Selecionado apenas do quarto até o último caracteres da string:
str_sub(words, start = 4) # começa no 4 caractere## [1] "casados" "casamento" "emprego" "empregado"Selecionando apenas os dois primeiros caracteres da string:
str_sub(words, end = 2) # termina no 2 caractere## [1] "00" "01" "02" "03"Para obter caracteres utilizando o sinal de negação -
#Suponha:
words <- c("casamento-01", "emprego-02", "empregado-03")
str_sub(words, end = -4) #Seleciona todos os valores menos os últimos 3## [1] "casamento" "emprego" "empregado"str_sub(words, start = -2) #Seleciona todos os valores até o segundo valor## [1] "01" "02" "03"Também é possível utilizar os argumentos end e start conjuntamente, veja
#É possível usar os argumentos start e end conjuntamente.
words <- c("__casamento__", "__emprego__", "__empregado__")
str_sub(words, start=3, end=-3)## [1] "casamento" "emprego" "empregado"A manipulação de strings é uma tarefa bem trabalhosa e algumas vezes até complexa porém cada desafio que surge ajuda bastante a entender esse mecanismo para manipulação de strings.
Pacote tm
O pacote tm é um clássico para o text mining em R, quando os dados se apresentam de forma não estrutura, necessitam de uma preparação prévia que pode ser considerada um tipo de pré-processamento.
Inicialmente, carregando o pacote:
library(tm)Em bases de dados textuais, conhecidos como corpus ou corpora são tratado como “documentos” e cada “documento” em um corpus pode assumir diferentes características em relação ao tamanho do texto (sequências de caracteres), tipo de conteúdo (assunto abordado), língua na qual é escrito ou tipo de linguagem adotada dentro outros exemplos.
A transformação de um corpus em um conjunto de dados que possa ser submetido à procedimentos de análise consiste em um processo que gera uma representação capaz de descrever cada documento em termos de suas características.
Para criar um corpus a partir de um data.frame basta utilizar o seguinte comando:
#Criando o corpus para o tratamento das variaveis com pacote library(tm):
corpus <- Corpus(DataframeSource(x))A seguir veremos algumas dos possíveis procedimentos para a manipulação de dados em um corpus.
Limpeza de um corpus
Uma sequência de comando interessantes para a limpeza de um corpus que já utilizei bastante é a seguinte:
#Realizando a limpeza da base de dados:
#Acrescentar mais stopwords para retirada;
#novas=c()
#Tratamento do corpus
tratar_corpus=function(x){
x%>%
tm_map(stripWhitespace)%>% #remover excessos de espaços em branco
tm_map(removePunctuation)%>% #remover pontuacao
tm_map(removeNumbers)%>% #remover numeros
tm_map(removeWords, c(stopwords("portuguese"),novas))%>% #remmover as stopwords,crie um vetor chamado "novas" para incluir novas stopwords
tm_map(stripWhitespace)%>% #remover excessos de espaços em branco novamente
tm_map(removeNumbers) #remover numeros novamente
# tm_map(content_transformer(tolower))%>% #colocar todos caracteres como minusculo
#tm_map(stemDocument) #Extraindo os radicais
}
corpus=tratar_corpus(corpus)
#inspect(corpus[[3]]) #Leitura de algum documento específicoPara criar a matriz de termos podemos utilizar o comando:
#Criando a matrix de termos:
corpus_tf=TermDocumentMatrix(corpus, control = list(minWordLength=2,minDocFreq=5))Caso precise trabalhar com a transformação tf-idf basta utilizar:
#Caso precise utilizar a medida tf-idf em um corpus:
corpus_tf_idf=weightTfIdf(corpus_tf,normalize=T)Obtendo uma matriz de frequências a partir de um corpos
Criando uma matriz para facilitar a manipulação dos dados
#Transformando em matrix para permitir a manipulação:
matriz = as.matrix(corpus_tf)
#organizar os dados de forma decrescente
matriz = sort(rowSums(matriz), decreasing=T)
#criando um data.frame para a matriz
matriz = data.frame(word=names(matriz), freq = matriz)Caso seja necessário conferir visualmente as palavras mais mencionadas, também podemos utilizar gráficos, como por exemplo:
#Vejamos os primeiros 10 registros:
head(matriz, n=10)## word freq
## anos anos 242
## pra pra 226
## site site 156
## cadastro cadastro 134
## faz faz 124
## fazer fazer 124
## ver ver 114
## todo todo 110
## consegue consegue 102
## gente gente 100#Vejamos visualmente:
head(matriz, n=10) %>%
ggplot(aes(word, freq)) +
geom_bar(stat = "identity", color = "black", fill = "#87CEFA") +
geom_text(aes(hjust = 1.3, label = freq)) +
coord_flip() +
labs(title = "20 Palavras mais mensionadas", x = "Palavras", y = "Número de usos")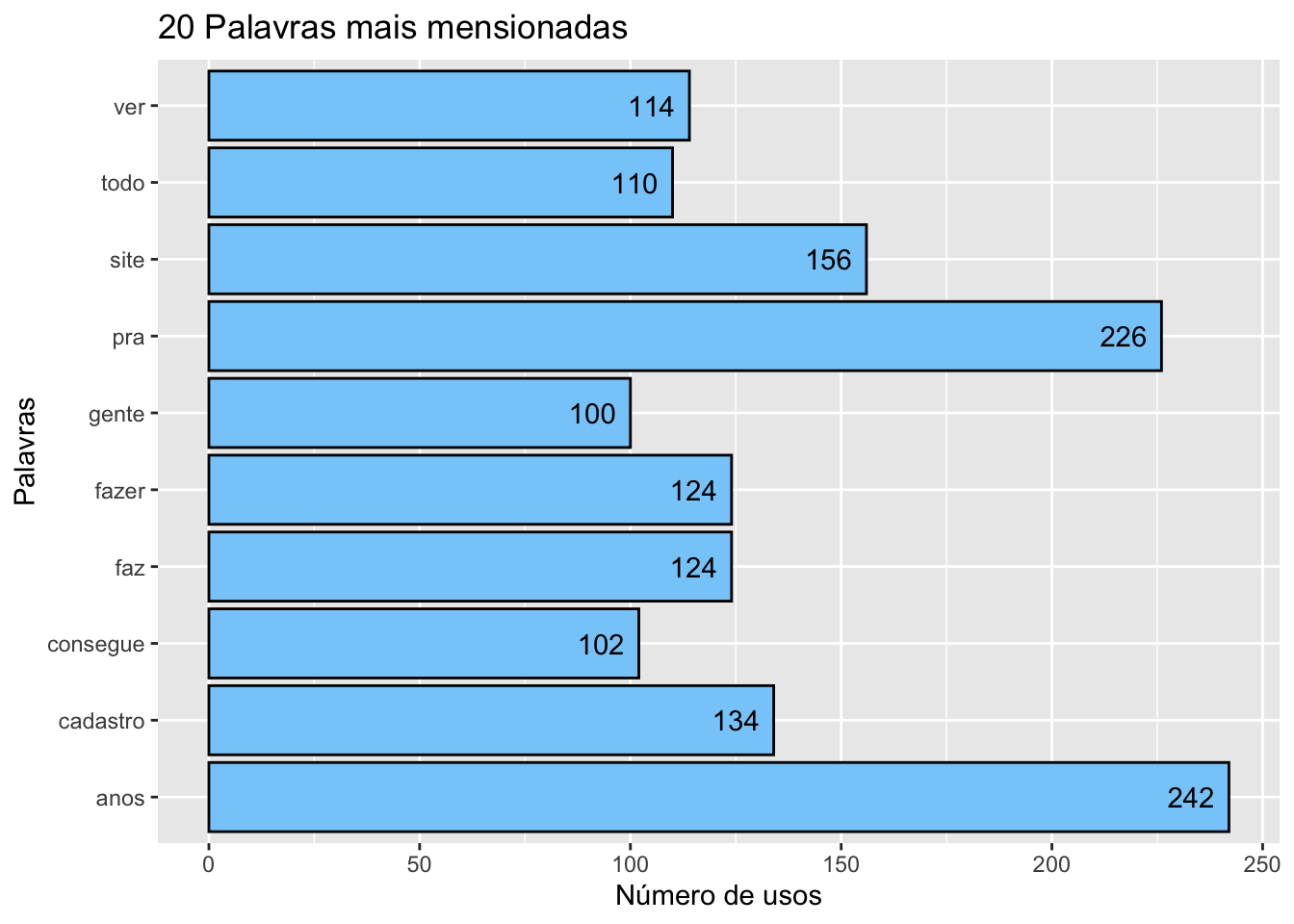
N-gram Dictionary com RWeka
Embora a análise de palavras realizada neste documento seja útil para a exploração inicial, o cientista de dados precisará construir um dicionário de bigrams, trigrams e quatro grams, coletivamente chamados de n-grams, que são frases de n palavras.
“O Weka tem como objectivo agregar algoritmos provenientes de diferentes abordagens/paradigmas na sub-área da inteligência artificial dedicada ao estudo de aprendizagem de máquina.”-Wikipedia
Carregando o pacote RWeka:
library(rJava)
suppressMessages(library(RWeka))
BigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 2, max = 2))
TrigramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 3, max = 3))
FourgramTokenizer <- function(x) NGramTokenizer(x, Weka_control(min = 4, max = 4))Como exemplo, criaremos um dicionário de trigrams (frases de três palavras) e a função para construir um dicionário de n-gramas utilizando o pacote tm e o RWeka é:
# tokenize into tri-grams
trigram.Tdm <- tm::TermDocumentMatrix(corpus, control = list(tokenize = TrigramTokenizer))Criando uma matriz para facilitar a manipulação dos dados
#Transformando em matrix para permitir a manipulação:
matriz = as.matrix(trigram.Tdm)
#organizar os dados de forma decrescente
matriz = sort(rowSums(matriz), decreasing=T)
#criando um data.frame para a matriz
matriz = data.frame(word=names(matriz), freq = matriz)#Vejamos os primeiros 20 registros:
head(matriz, n=10)
#Vejamos visualmente:
head(matriz, n=10) %>%
ggplot(aes(word, freq)) +
geom_bar(stat = "identity", color = "black", fill = "#87CEFA") +
geom_text(aes(hjust = 1.3, label = freq)) +
coord_flip() +
labs(title = "20 frases mais mensionadas", x = "Palavras", y = "Número de usos")Parece que este pacote parou de funcionar temporariamente, uma alternativa a este pacote pode ser o ngram e seu uso pode ser da seguinte forma:
library(ngram)
ngrams=3
temp=ngram::ngram(ngram::concatenate(corpus),ngrams) # Objeto temporario recebe objeto que guarda sequencias
temp=get.phrasetable(temp) # Obtendo tabela de sequencias do objeto acima
temp$ngrams=temp$ngrams%>% # Limpeza das sequencias obtidas:
str_replace_all(pattern = "^([A-Za-z] [A-Za-z])+","")%>% # Remover sequencias de apenas 1 letras
str_replace_all(pattern = "[:punct:]","")%>% # Remover caracteres especiais
str_replace_all(pattern = "\n","")%>% # Remover o marcador de "nova linha"
str_trim() # Remover espaços em branco sobrando
#Apos a limpeza..
temp=temp[temp$ngrams!="",] # Selecionando apenas as linhas que contenham informacao
temp=temp%>% # Novamente manipulando o objeto que contem a tabela de sequencias
group_by(ngrams) %>% # Agrupando por "ngrams" (sequencias obtidas)
summarise(freq=sum(freq))%>% # Resumir as linhas repetidas pela soma das frequencias
arrange(desc(freq))%>% # Organizando da maior para a menos frequencia
as.matrix() # Alterando o tipo de objeto para matrix
rownames(temp)=str_c(temp[,1]) # O nome das linhas passa a ser a sequencia correspondente
v=sort(temp[,2],decreasing = T) # Retorna um objeto com as frequencias em ordem decrescente e linhas nomeadas
data.frame(words = names(v),freq=v)%>%
head(n=25)%>%
ggplot(aes(words, freq)) +
geom_bar(stat = "identity", color = "black", fill = "#87CEFA") +
geom_text(aes(hjust = 1.3, label = freq)) +
coord_flip() +
labs(title = "25 frases mais mensionadas", x = "Palavras", y = "Número de usos")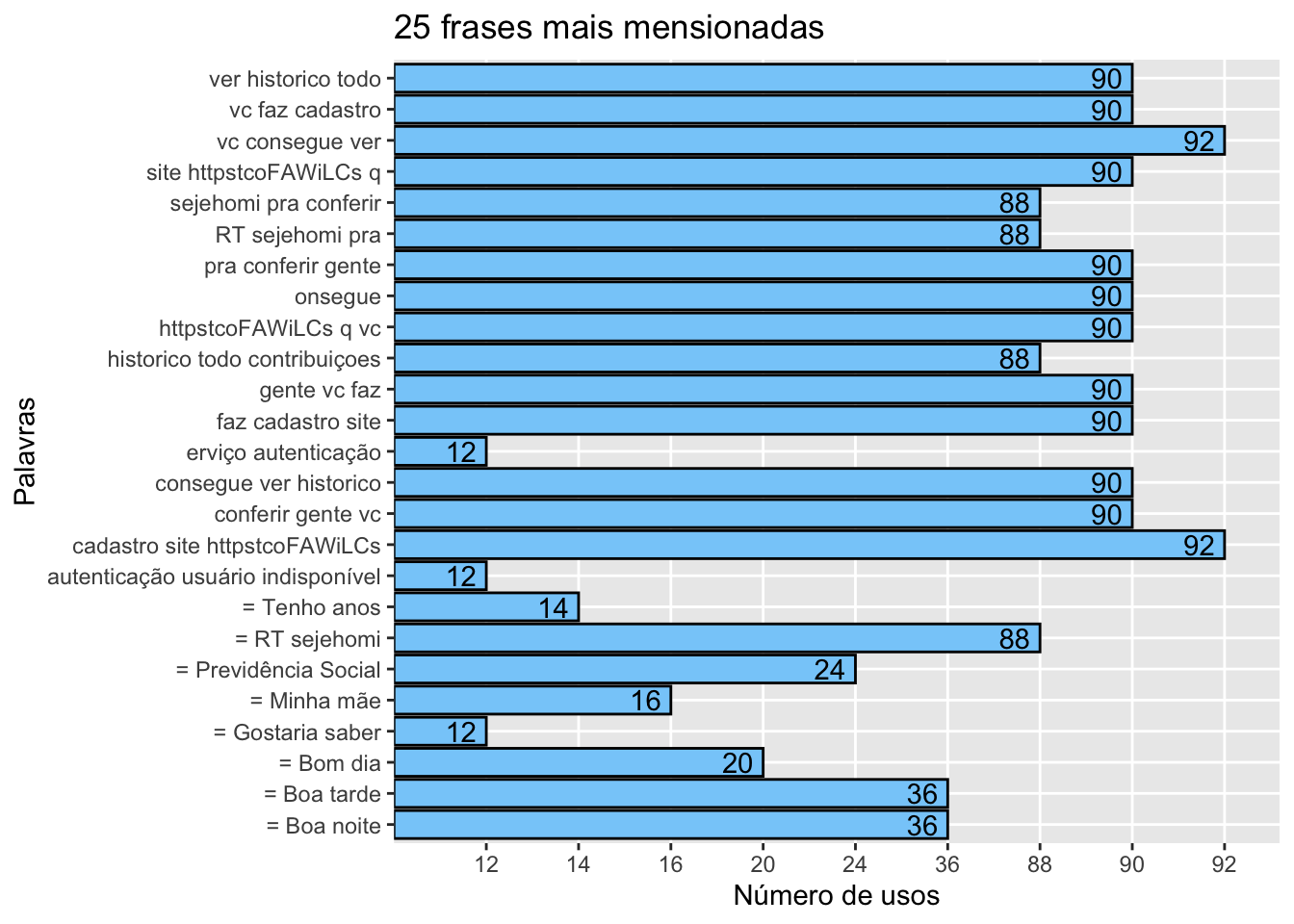
Package ‘SnowballC’
Caso seja necessário retirar o radical de um vetor de strings podemos utilizar a função ´wordStem´ do pacote SnowballC, caso queria conferir, existe o manual do pacote no CRAN
words=c("casados", "casamento", "emprego", "empregado")
SnowballC::getStemLanguages()## [1] "arabic" "basque" "catalan" "danish" "dutch"
## [6] "english" "finnish" "french" "german" "greek"
## [11] "hindi" "hungarian" "indonesian" "irish" "italian"
## [16] "lithuanian" "nepali" "norwegian" "porter" "portuguese"
## [21] "romanian" "russian" "spanish" "swedish" "tamil"
## [26] "turkish"SnowballC::wordStem(words, language = "portuguese")## [1] "cas" "casament" "empreg" "empreg"

Share this post
Twitter
LinkedIn
Email