





































Dashboard com textmining de mídias sociais
Códigos para gerar o painel que criei para auxiliar no estudo de dados do tipo string enquanto era estagiário. Executa mineração de texto, análise exploratória e análise de sentimentos de banco de dados de rede social adquiridos com o software Social Search.
Dashboard text mining v1
Link do repositório no github: https://github.com/gomesfellipe/dashboard-text-mining-1
Link de acesso ao dashboard : https://gomesfellipe.shinyapps.io/dashboard-text-mining-1/
Motivação
Elaborar este dashboard foi uma tarefa que decidi executar pois me foi perguntado se era possível “alguma coisa” com os dados obtidos através da ferramenta Social Searcher responsável por captar informações de diferentes mídias sociais sob algum tópico de interesse.
Decidi então praticar a criação de dashboards com R e juntei algumas abordagens simples de text mining em um dashboard produzido através do pacote flexdashboard, disponível no CRAN.
Portanto este dashboard não foi programado para funcionar de maneira genérica, as diversas funcionalidades devem ser adaptadas caso seja utilizado para analisar novas bases.
Arquivos
Esta pasta contém os seguintes arquivos:
-
Código responsável por gerar o dashboard
- dashboard-text-mining-1.Rmd
-
Bases:
-
base.xlsx - exemplo de dados obtidos com a ferramenta Social Searcher
-
sentimentos.csv - base com classificação de sentimentos (lexical)
-
-
Funções:
- catch_error.R
- cleanTweets.R
- cleanTweetsAndRemoveNAs.R
- html_to_text.R
- plot_kmeans.R
- rm_accent.R
- rquery_wordcloud.R
- score.sentiment.R
Mais informações sobre funções de textmining podem ser obtidas neste link ou no repositório deste guia no github
Dashboard
Este dashboard conta com 5 abas. Além da base de dados obtida com o Social Searcher, também foi utilizada o pacote lexiconPT que conta com alguns datasets léxicos para análise de texto em português. Com essa duas bases foi computada a interseção e os sentimentos de cada palavra foram registrados (qualquer nova palavra pode ser adicionada ao dicionário léxico posteriormente para enriquecer a apresentação visual).
“Sem remover sufixos”
A primeira parte do dashboard apresenta 4 nuvens de palavras, na parte superior a primeira nuvem não foi feita a transformação tf-idf, já na nuvem a direita essa transformação foi feita e ambas dispostas lado a lado para avaliar o efeito da transformação no shape da nuvem.
Já as nuvens da parte inferior são versões das nuvens acima, realizando a análise lexical.
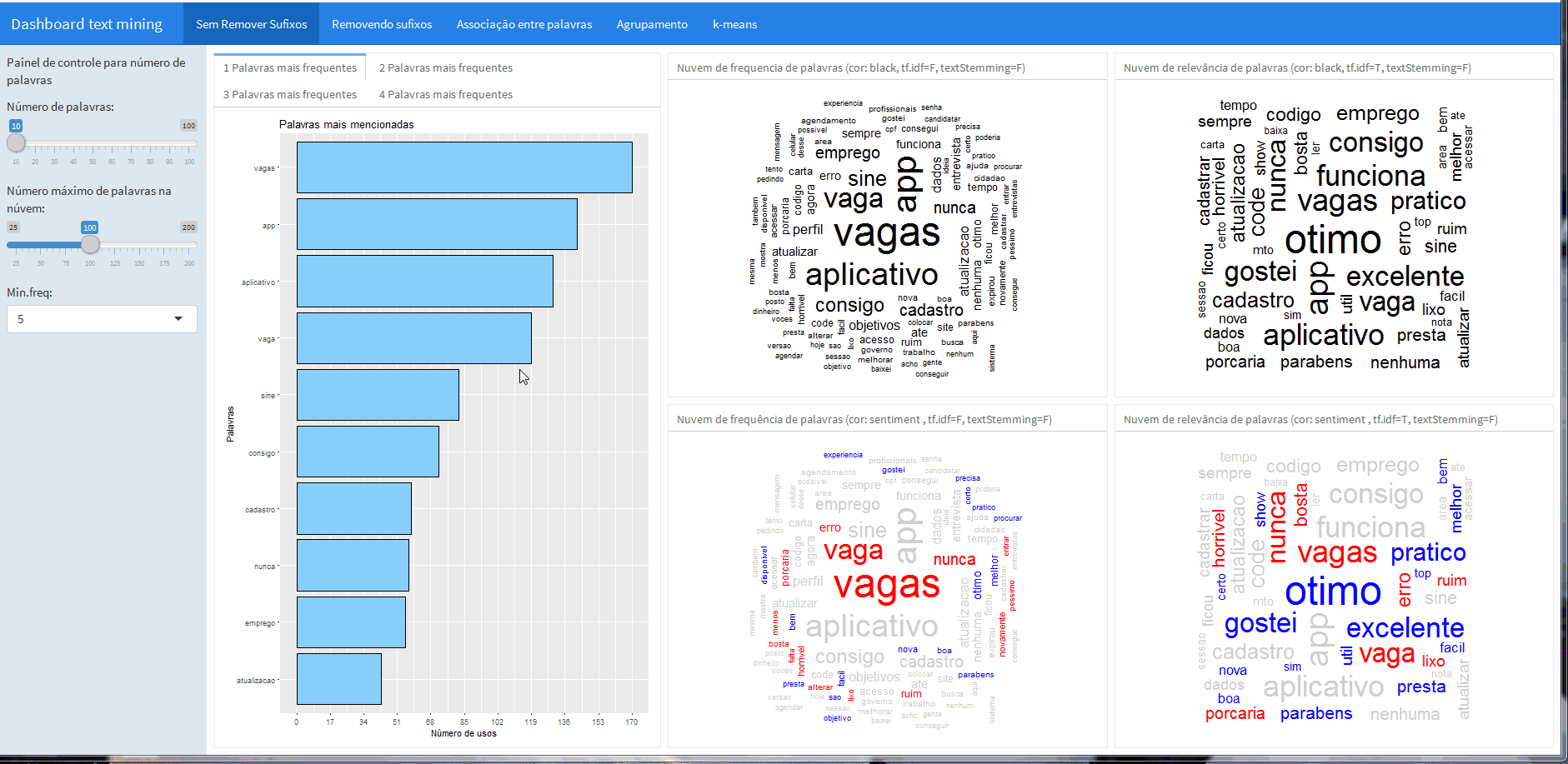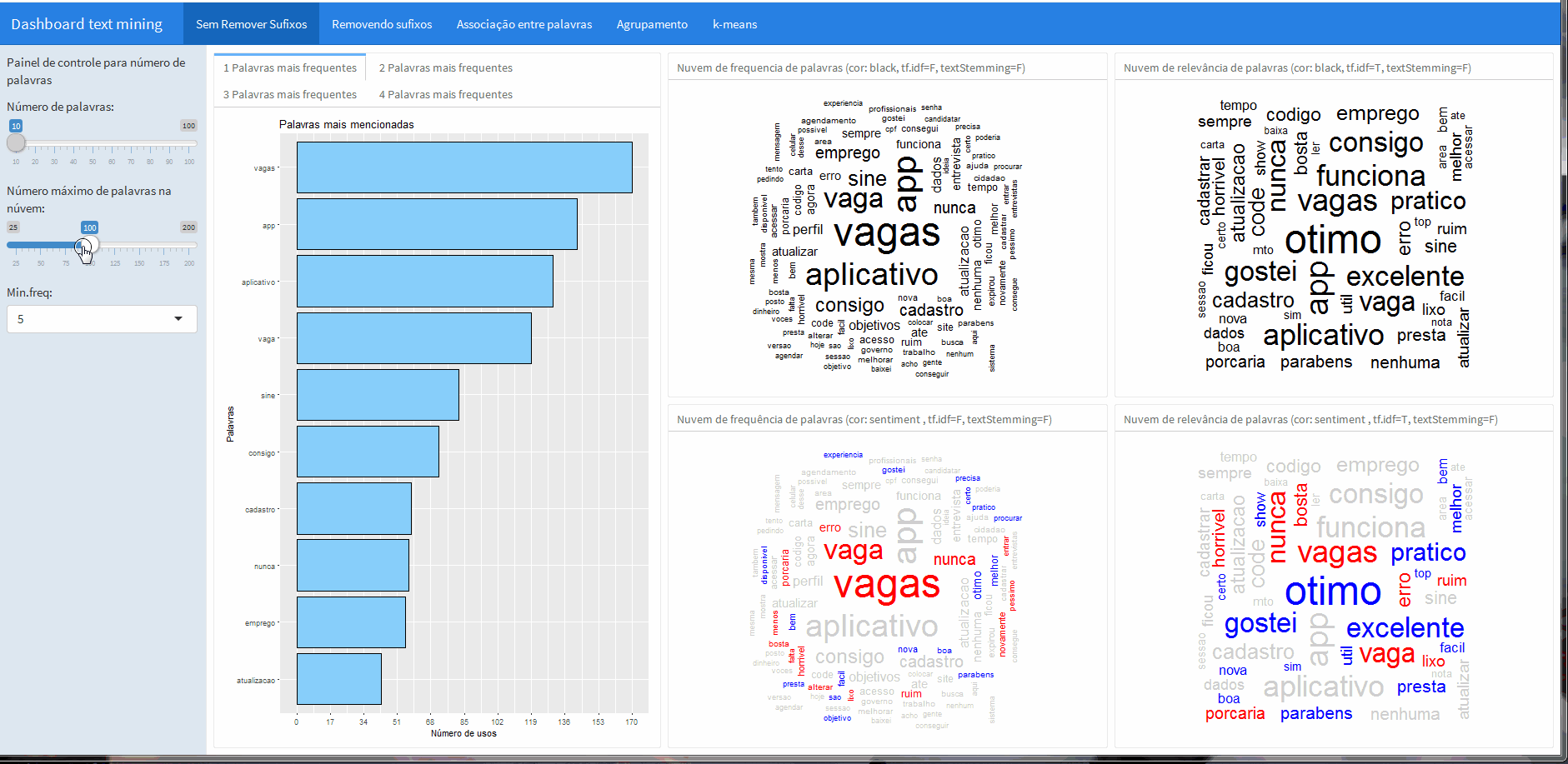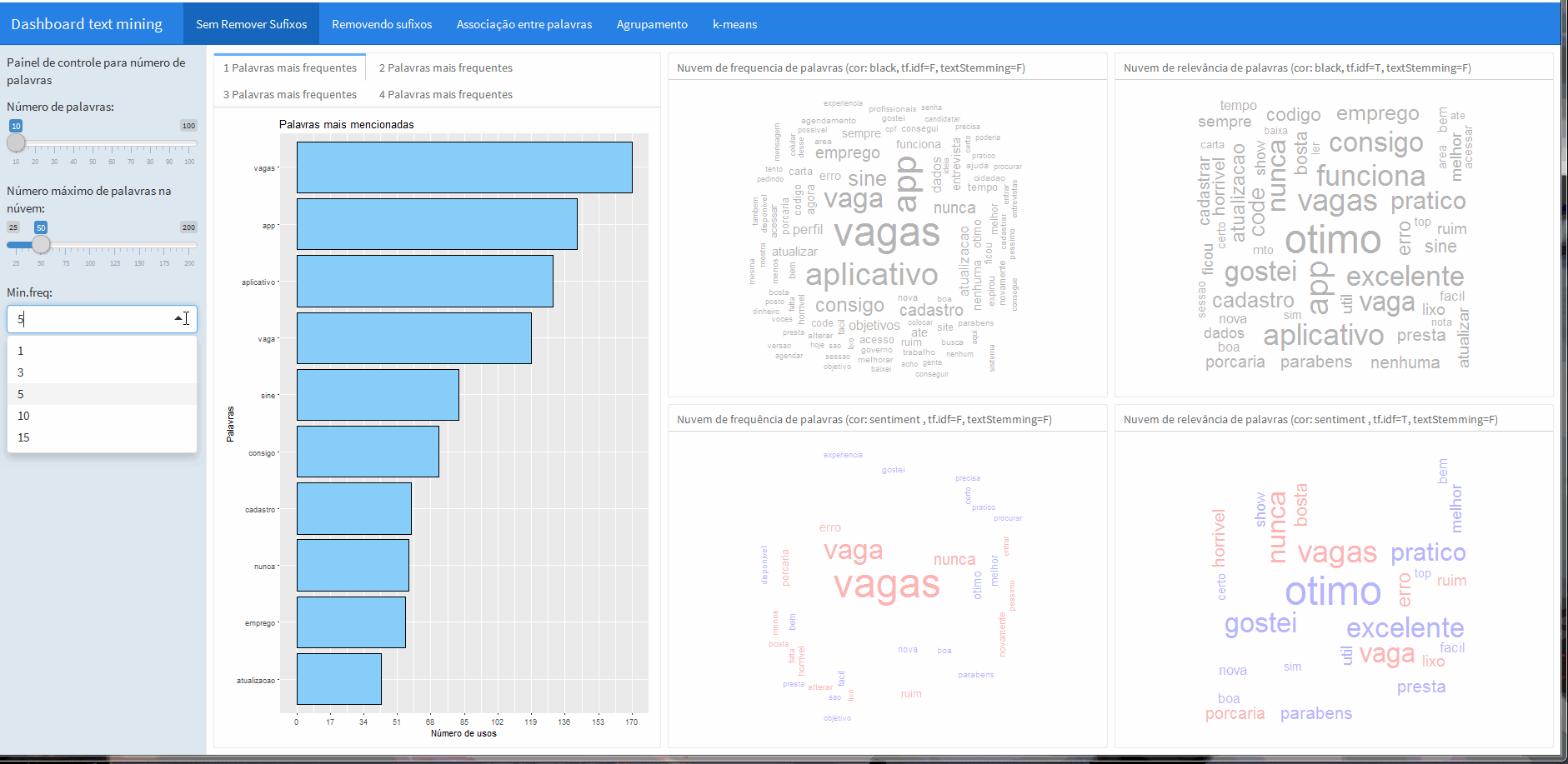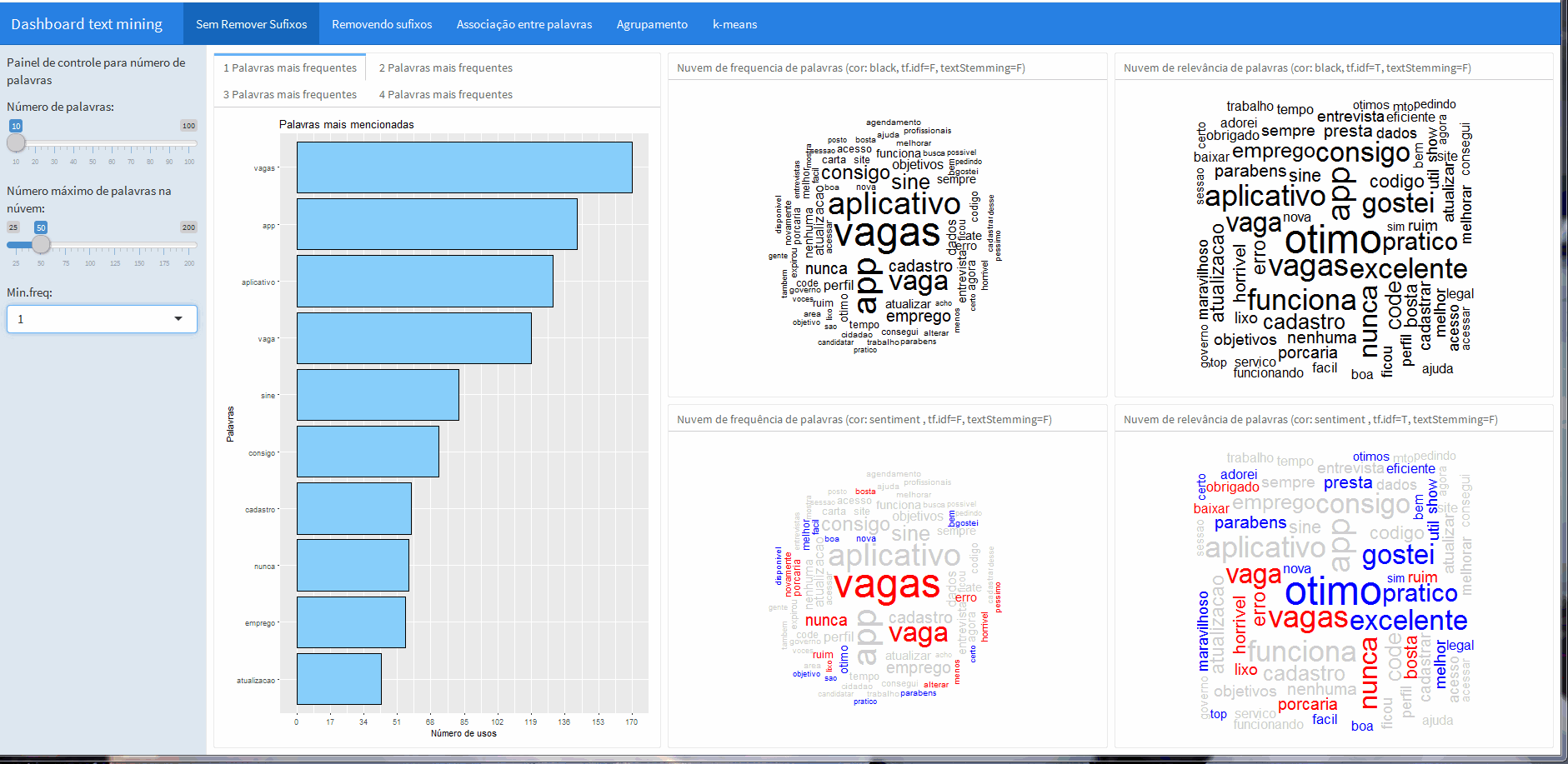
Com os botões é possível controlar a frequência minima e o número máximo de palavras na nuvem.
Além disso, ao lado da barra lateral dos botões é possível conferir a frequência de palavras únicas e também sequencias de palavras, que foram computadas com a ajuda do pacote RWeka (ferramenta interessante para aplicações de machine learning e data mining).

“Removendo sufixos”
A segunda aba possui basicamente as mesmas características da primeira, porém nesta seção foi realizada a retirada dos radicais com a função SnowballC::wordStem(), veja:

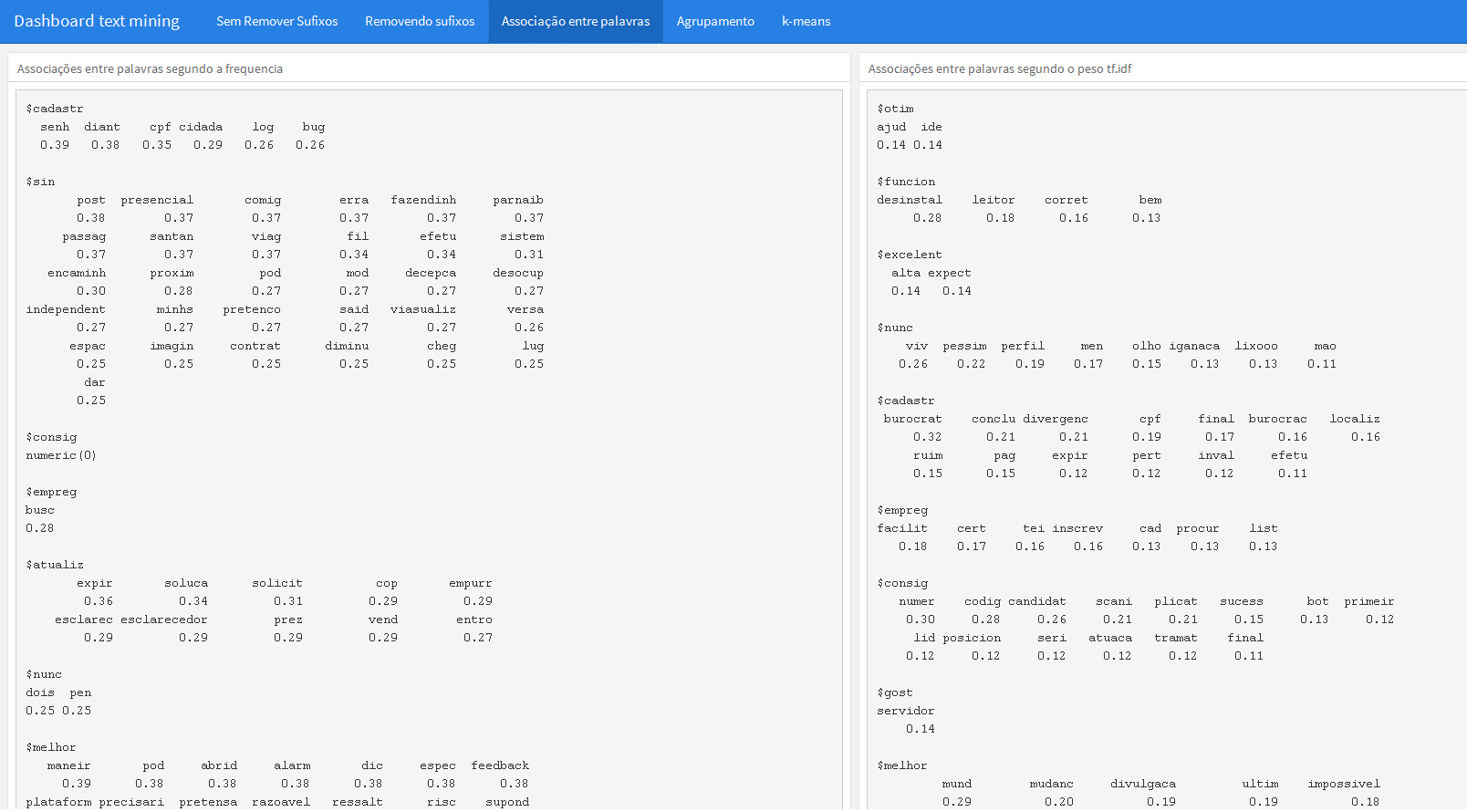
“Associação entre palavras”
A terceira aba é responsável por trazer o resultados do comando tm::findAssocs que busca associações entre palavras em um document-term ou uma term-document, do pacote tm, muito famoso quando o assunto é text mining.
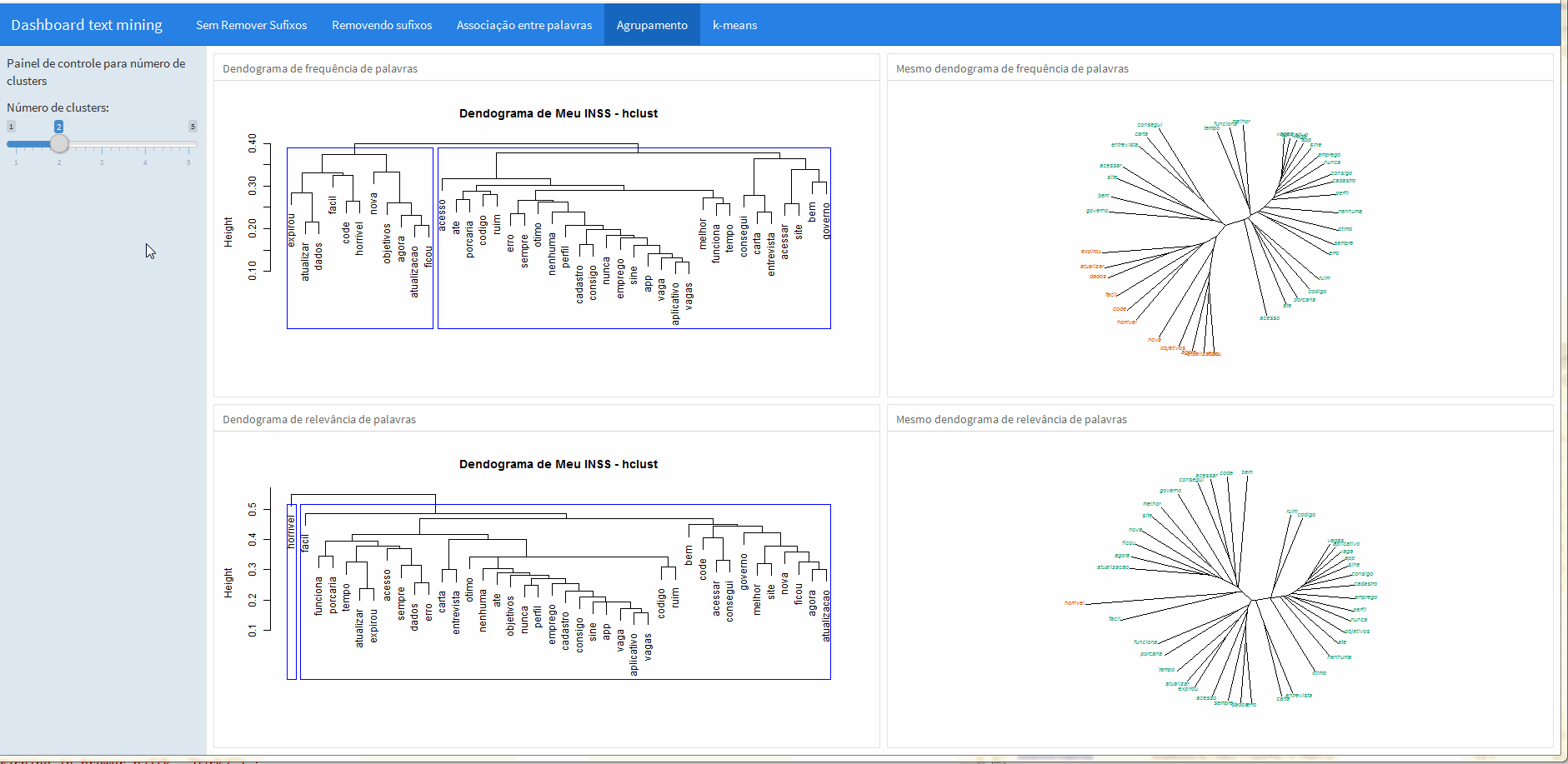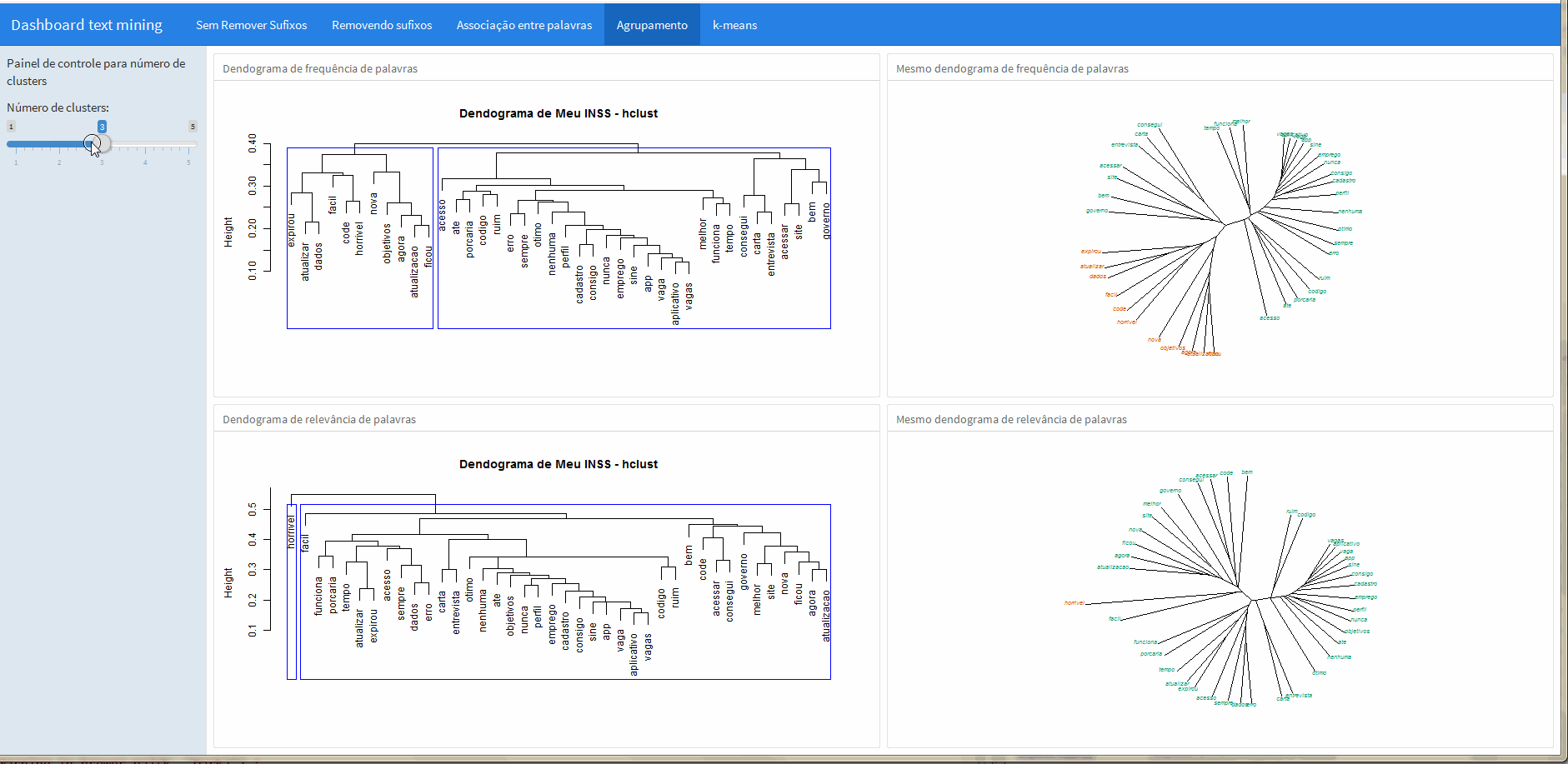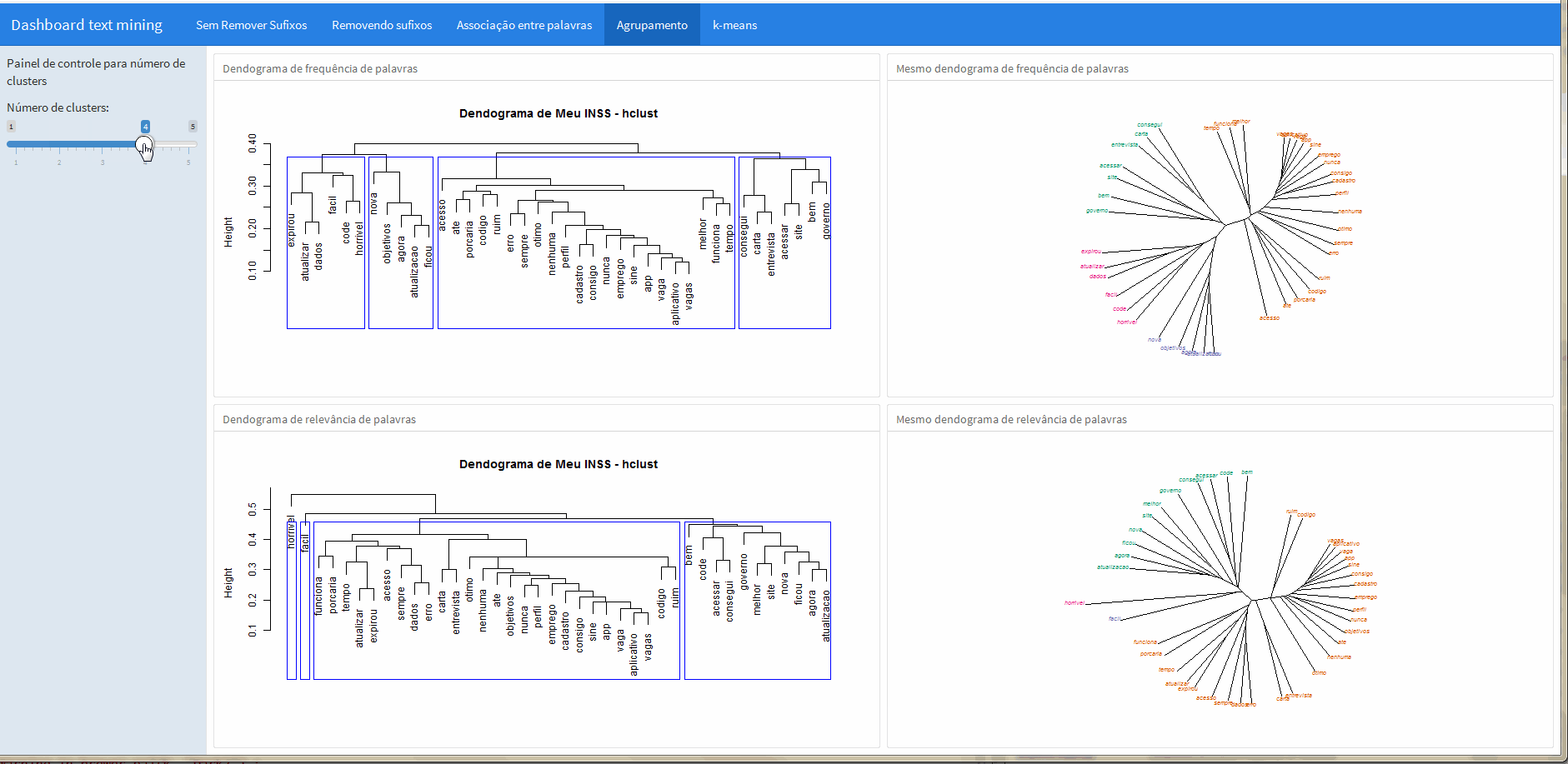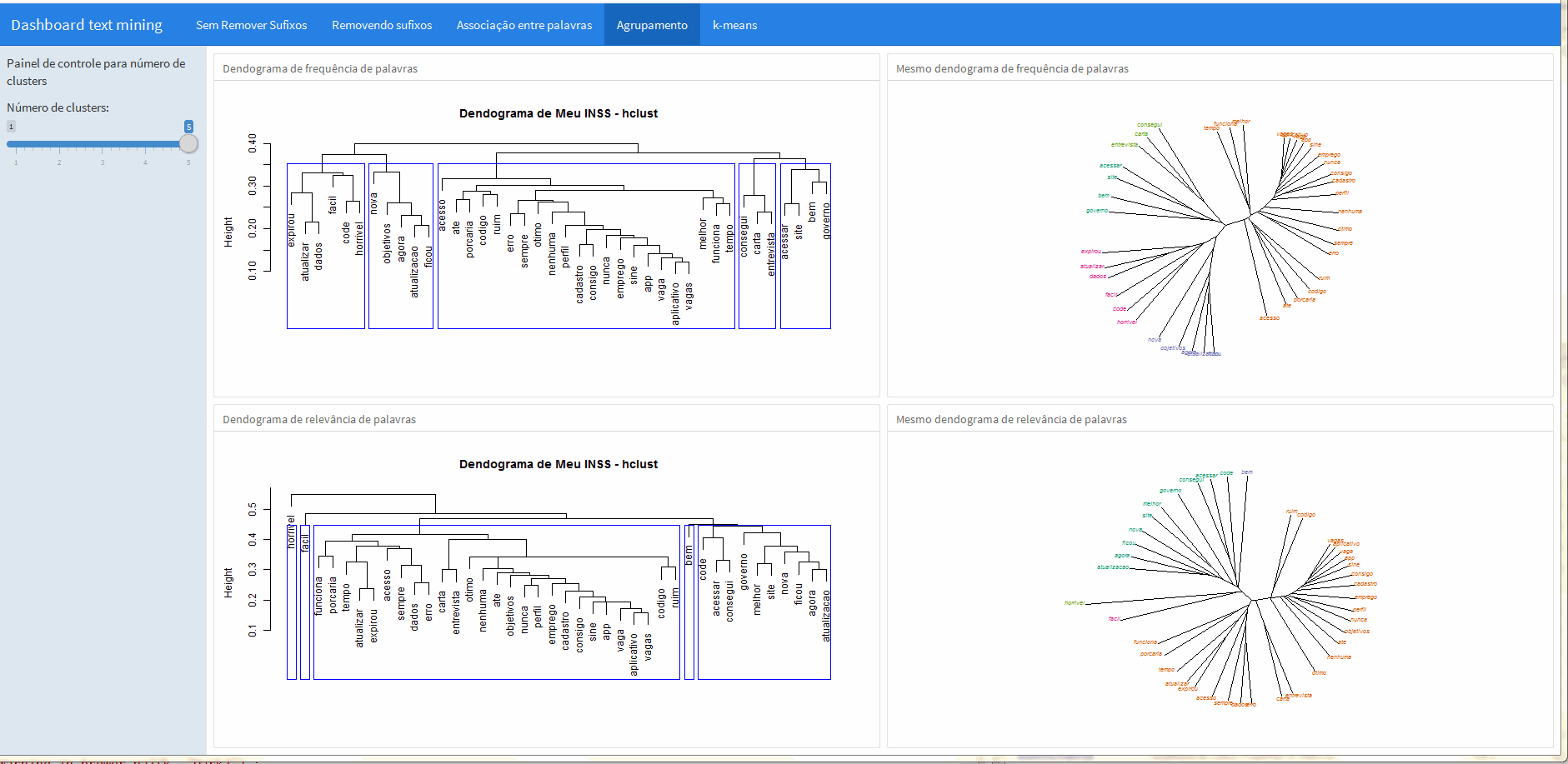
“Agrupamento”
Para efeito de ilustração do que pode ser feito, nesta aba foi feita uma análise de clusters calculando a distância euclideana e agrupando os dados de acordo com o método de Ward.
O dendograma pode ser apresentado de muitas formas diferentes, então nesta apresentação coloquei à direita a representação convencional e à direita o mesmo dendograma é apresentado de maneira “aberta” e colorida, facilitando a visualização dos grupos formados.
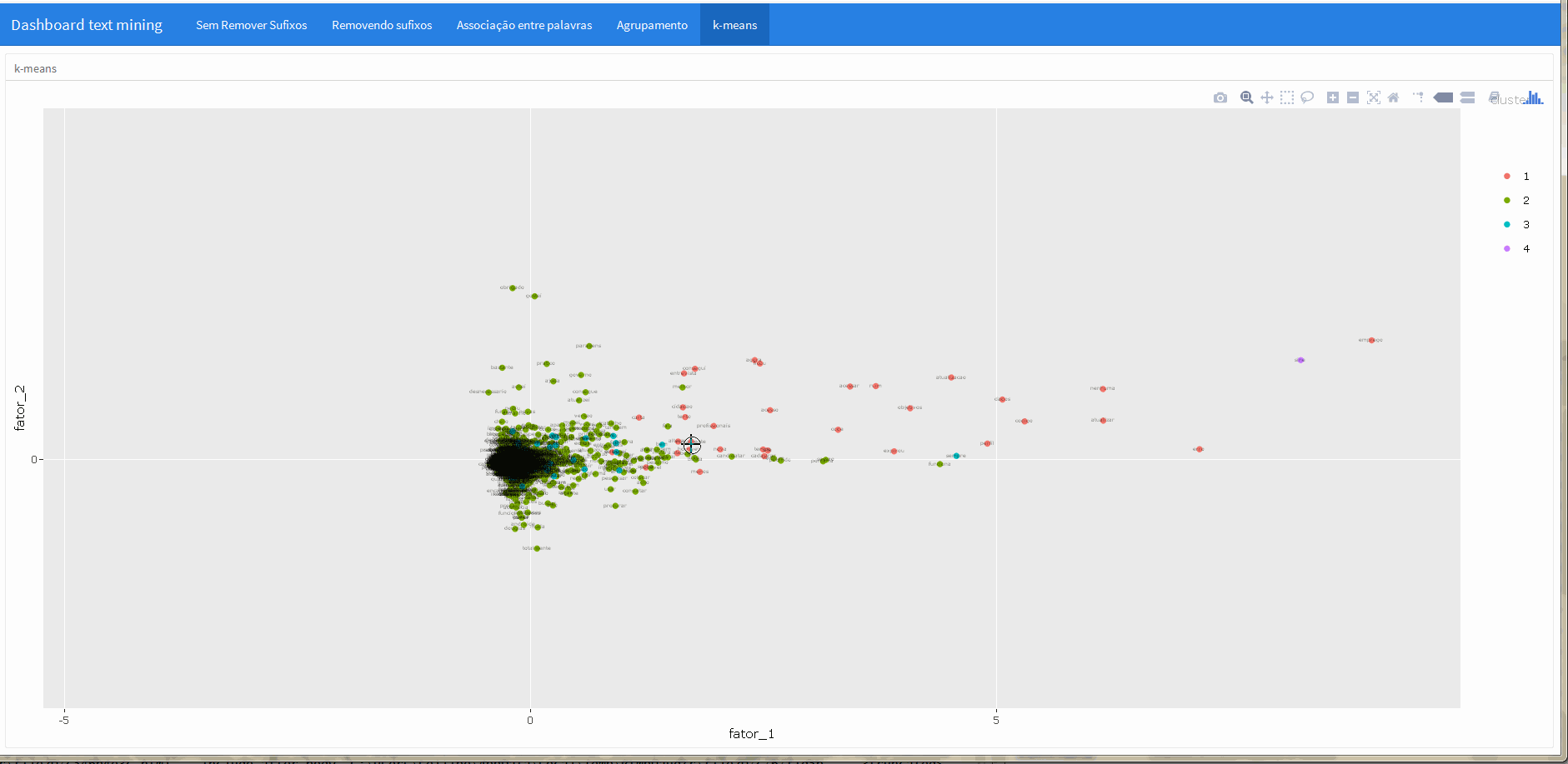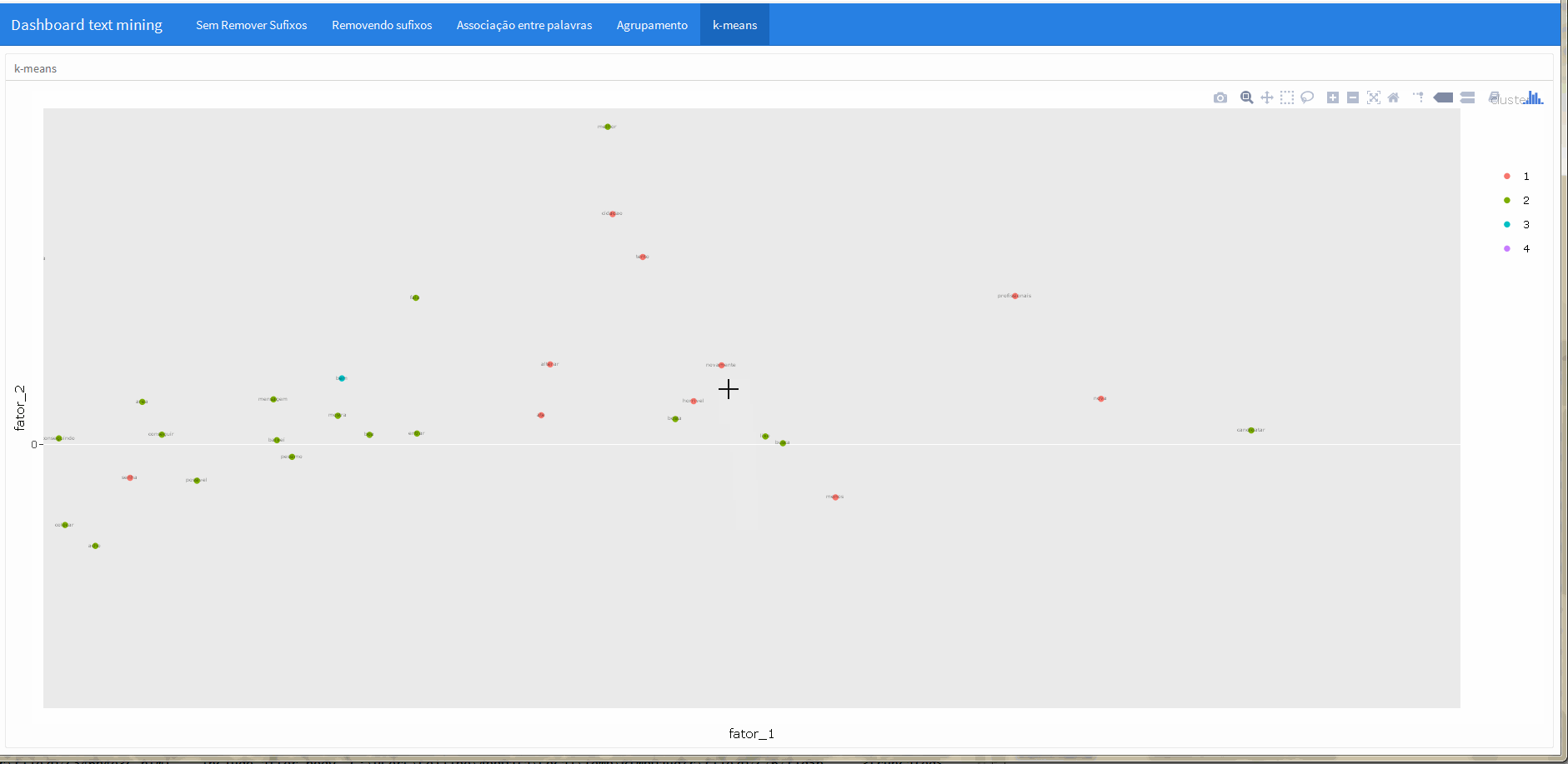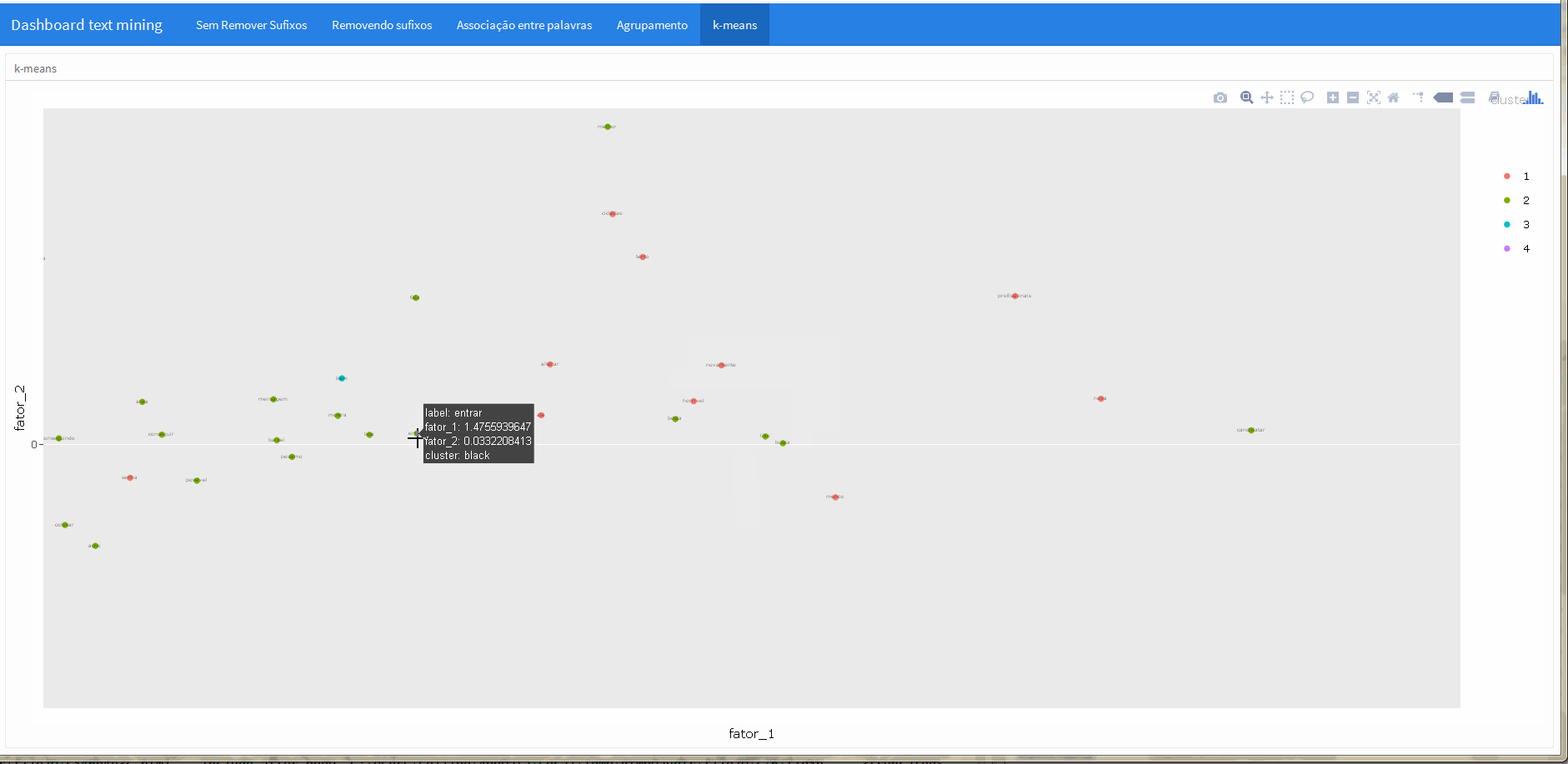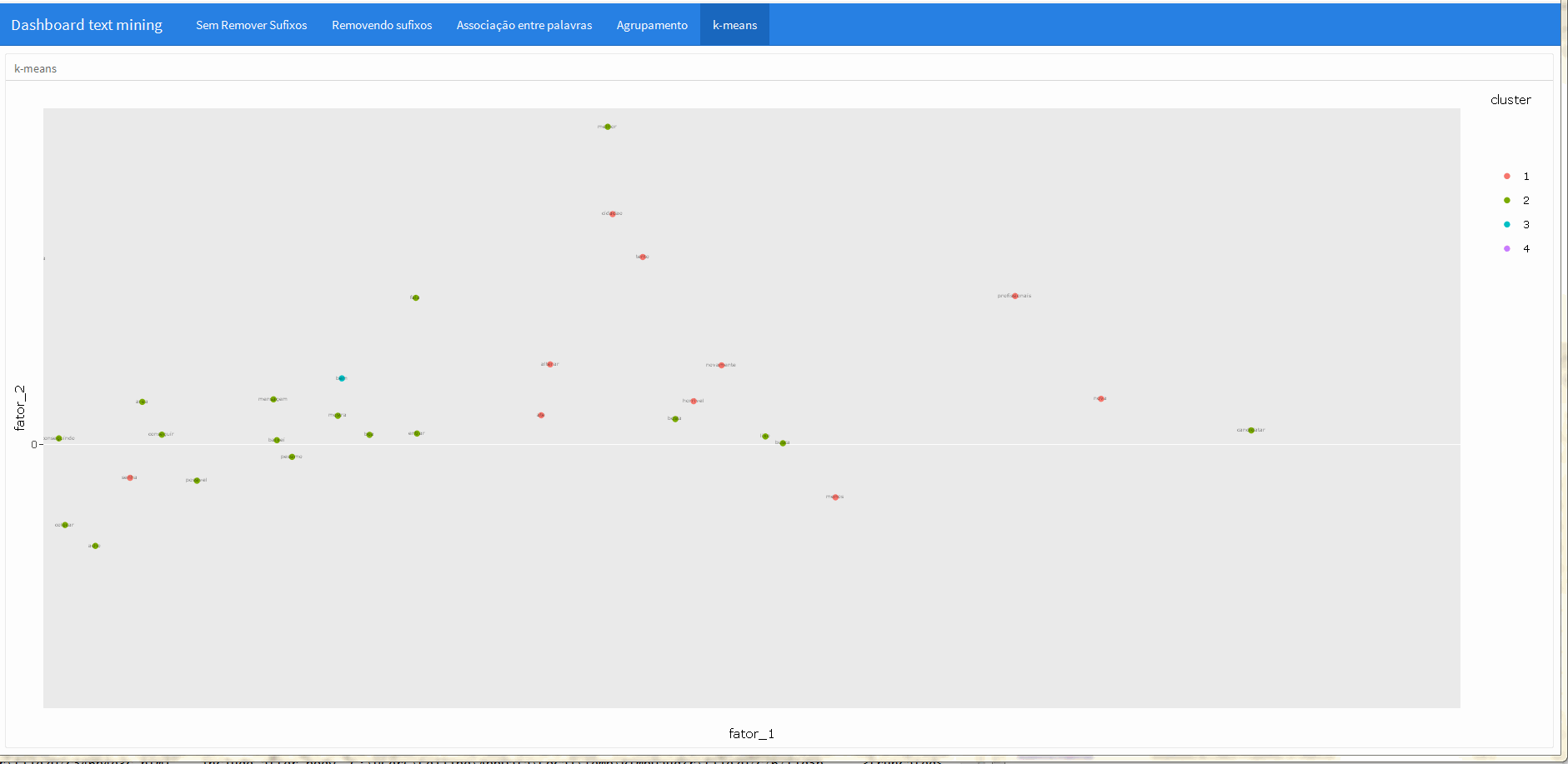
“k-means”
Na última aba foi apresentado uma aplicação do algorítimo k-means, uma técnica simples de agrupamento utilizado em procedimentos não supervisionados de machine learning.
Em conjunto com a função ggplotly do pacote plotly fica muito simples tornar esta imagem interativa, veja:


















Share this post
Twitter
LinkedIn
Email