





































Aplicativo para análise multivariada
Faça uma análise de tarefa não supervisioada (PCA e kmeans) com apenas alguns clicks
![]()
![]()
Link do repositório no github: https://github.com/gomesfellipe/appPCAkmeans
Link de acesso do app : https://gomesfellipe.shinyapps.io/appPCAkmeans/
Esta pasta conta com os seguintes arquivos:
Base de dados iris (base de dados nativa do R)
- base-iris.csv - exemplo de base de dados como imput do aplicativo
Código do aplicativo:
- appPCAkmeans.Rmd - Script do código responsável por rodar o aplicativo
Agrupamento - Machine Learning
A análise de componentes principais e a busca por clusters é uma tarefa muito comum quando não conhecemos a classificação.
A tarefa de agrupamento (muitas vezes também chamada de clustering) pode ser compreendida como um processo que torna possível descobrir relações entre exemplares de um conjunto de dados que contam com uma série de características (atributos descritivos) porém não há presença de um rótulo associado (classe) a cada exemplar.
De maneira geral as análises realizadas por algorítimos de machine learning que implementam técnicas de agrupamento buscam por diferenças ou por similaridades entre exemplares, quantificadas por meio de medidas de distância (quanto menor a distância entre dois exemplares, maior será a similaridade), portanto uma estrutura de grupos é formada de maneira que a similaridade intragrupos tenha sido maximizada, e a similaridade intergrupos tenha sido minimizada.
Quando esse processo de minimização é feito por um algorítimo de Machine Learning, é considerado um processo indutivo e não supervisionado - também conhecido como treinamento não supervisionado ou ainda como aprendizado não supervisionado
Referência: Introdução a Mineração de Dados com aplicações em R
Obs.: Aqui nesse github existe um repósitório chamado Livro_Introducao_a_Mineracao_de_Dados que contém algumas das funções e idéias adquiridas ao estudar esse livro.
Além do post no meu blog que falo sobre Análise multivariada em R
Pacotes utilizados:
Pacotes utilizados no app:
- library(shiny) - Renderizar o aplicativo
- library(ggplot2) - Criar gráficos elegantes
- library(ggfortify) - Criar gráficos de análises com ggplot
- library(DT) - Renderizar tabelas elegantes e práticas
- library(plotly) - Transforma ggplot em interativo
Instruções
Carregamento
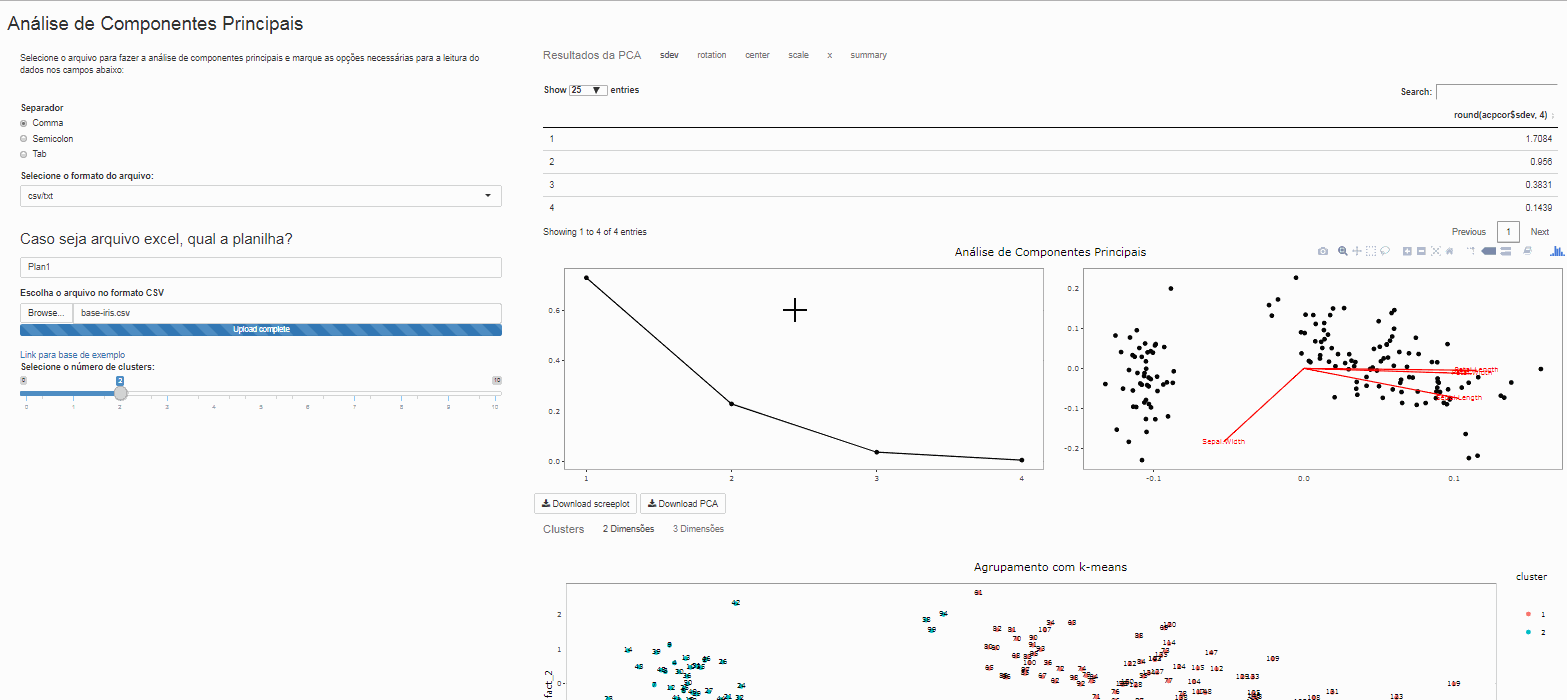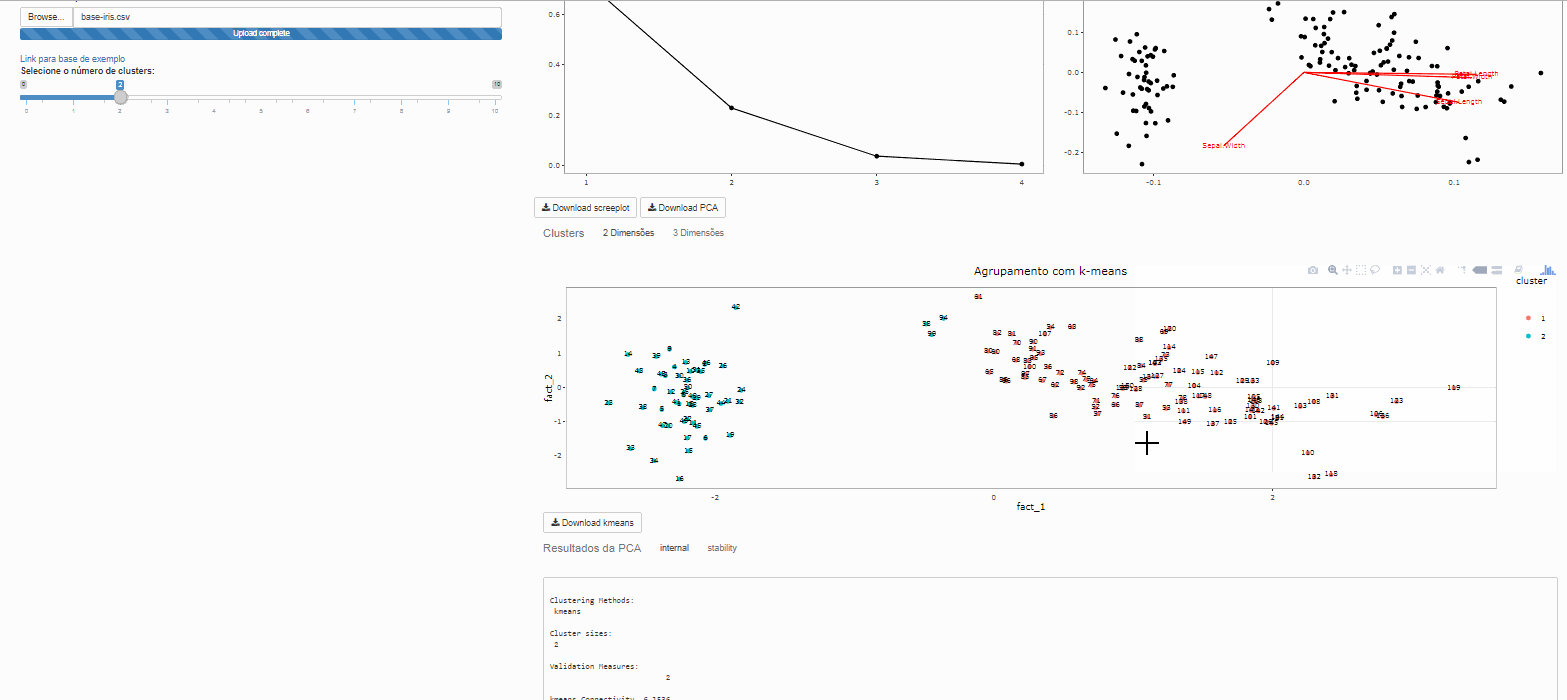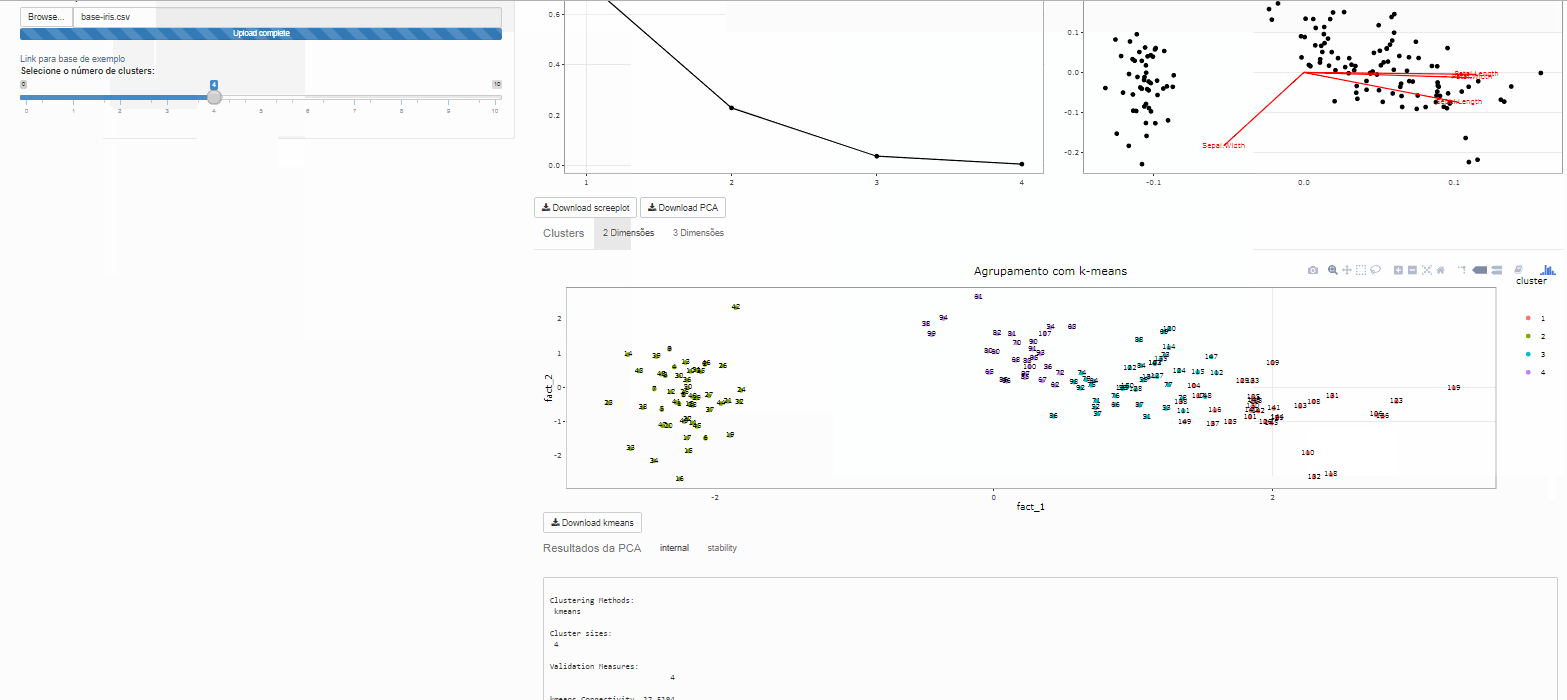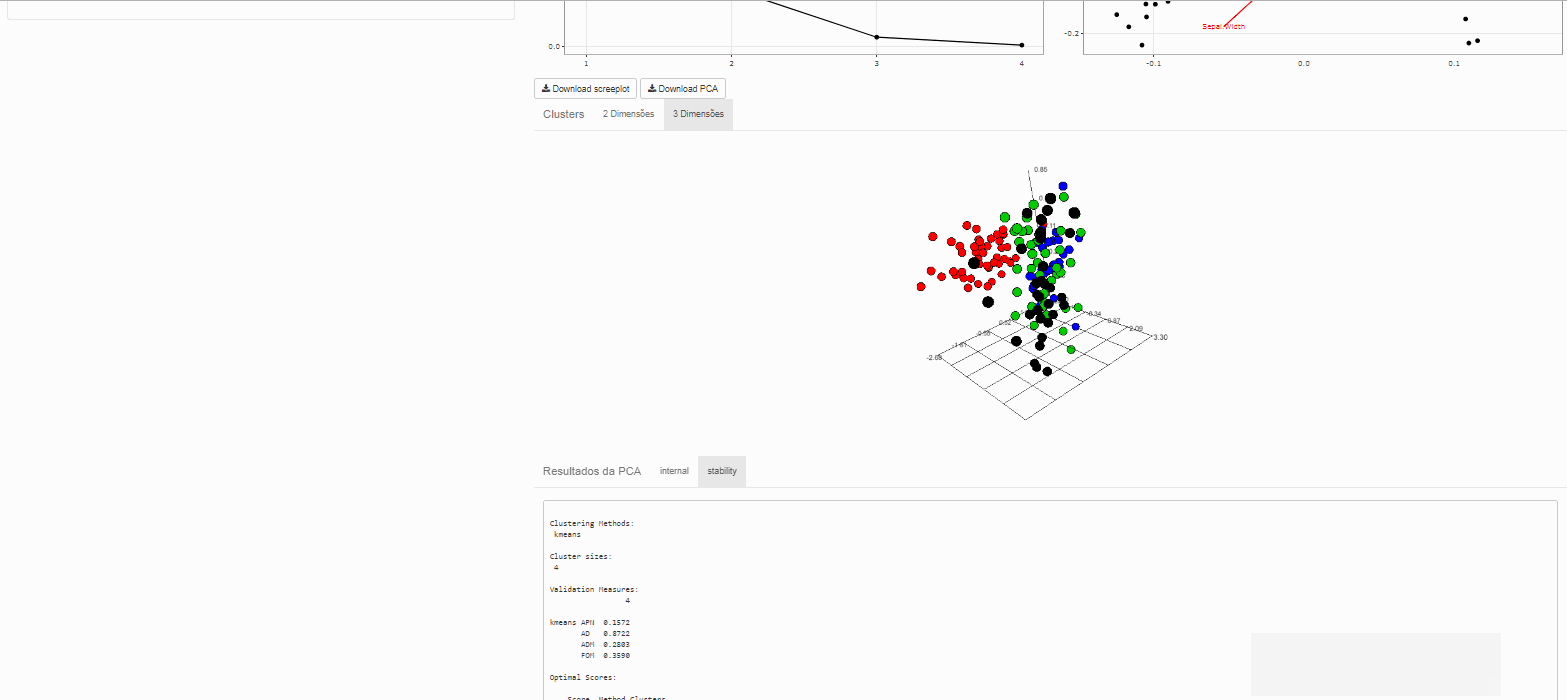
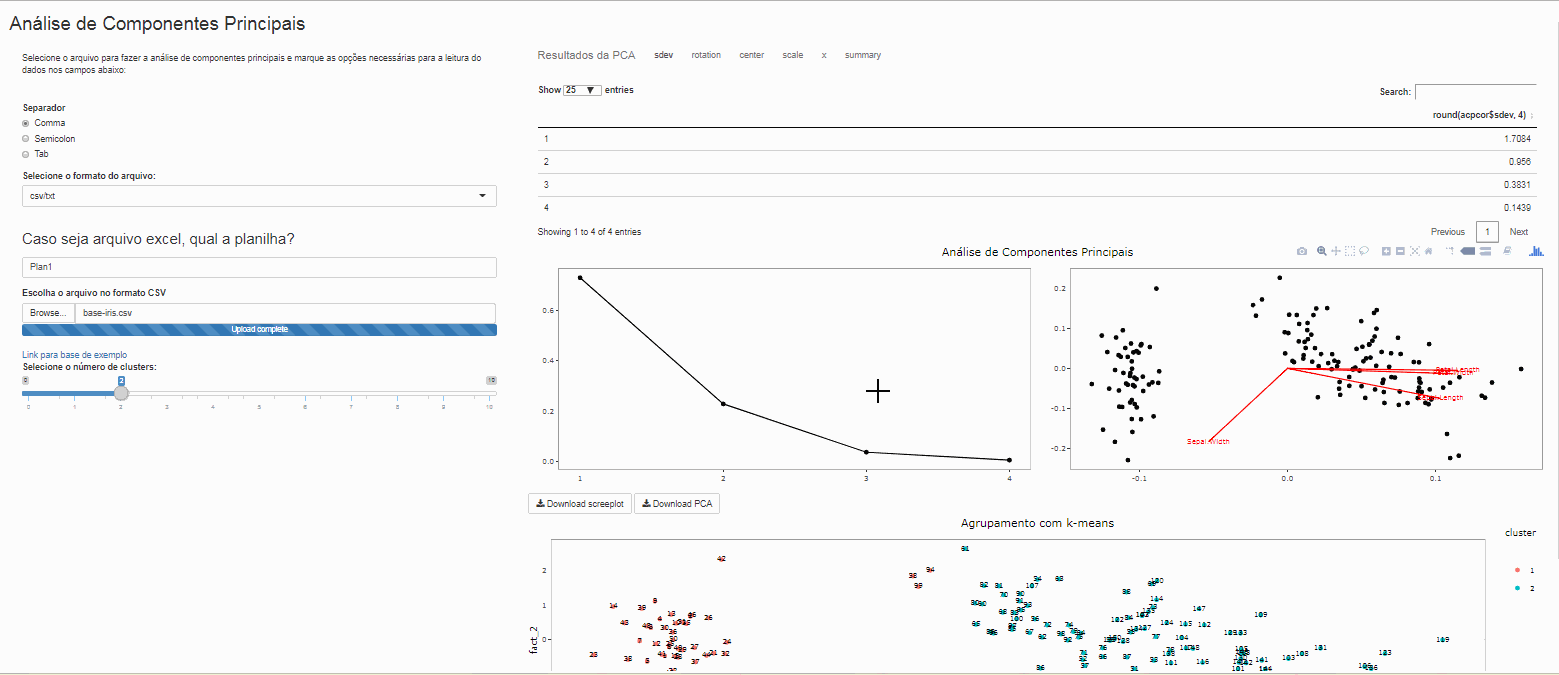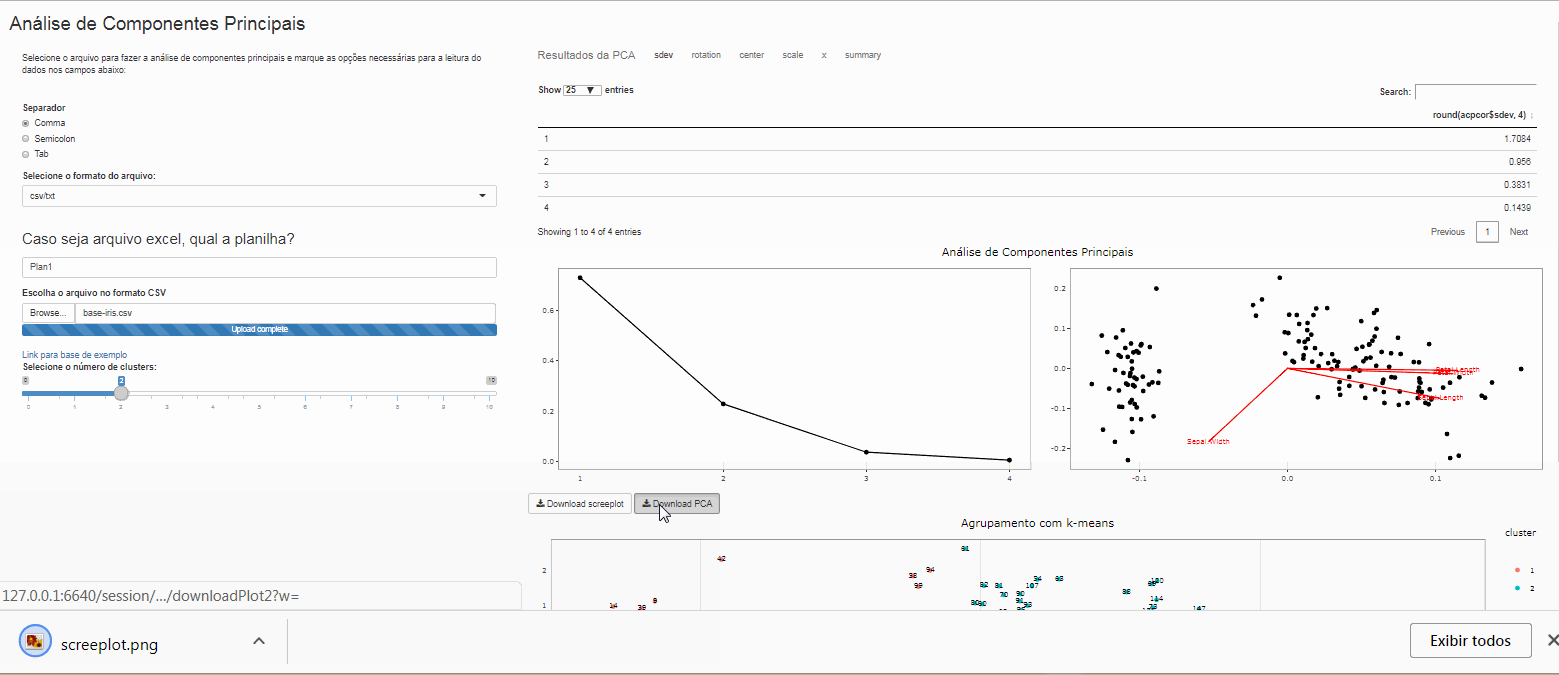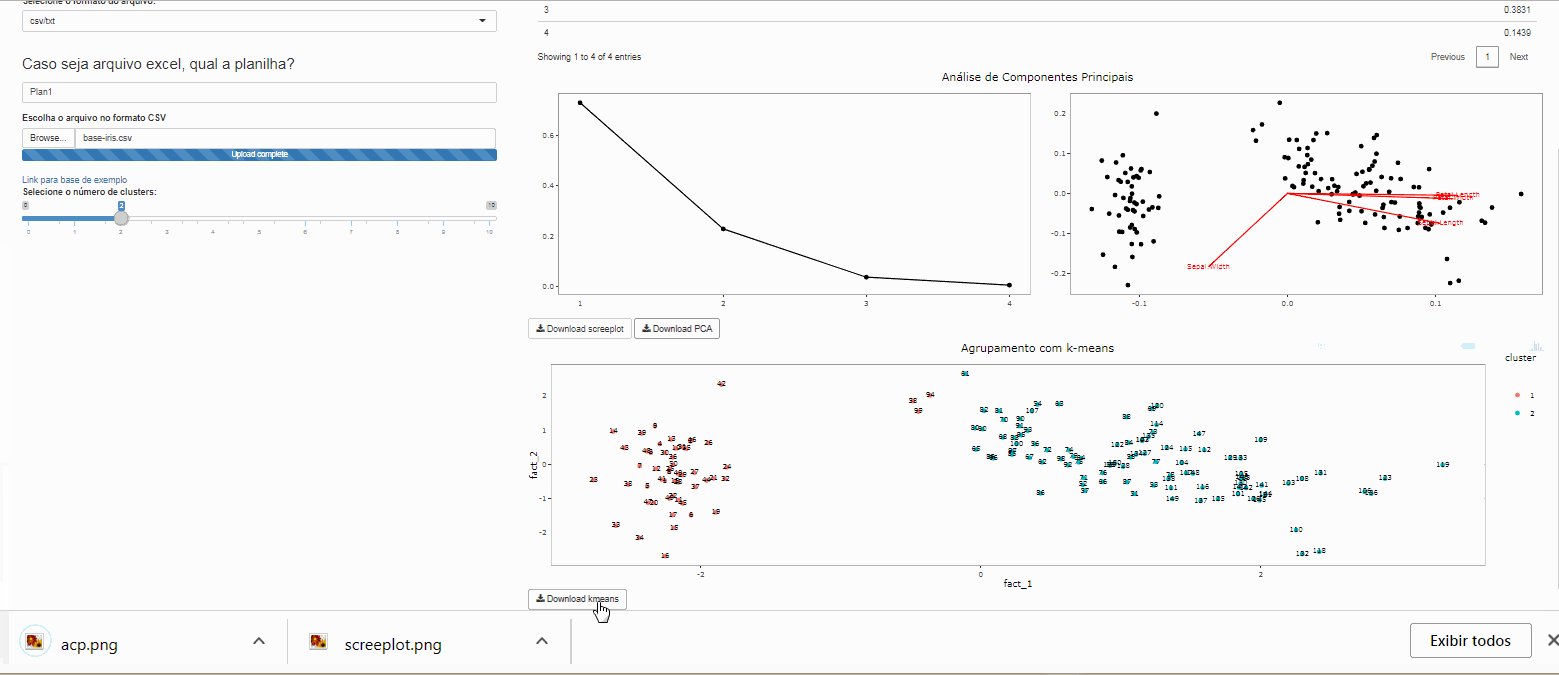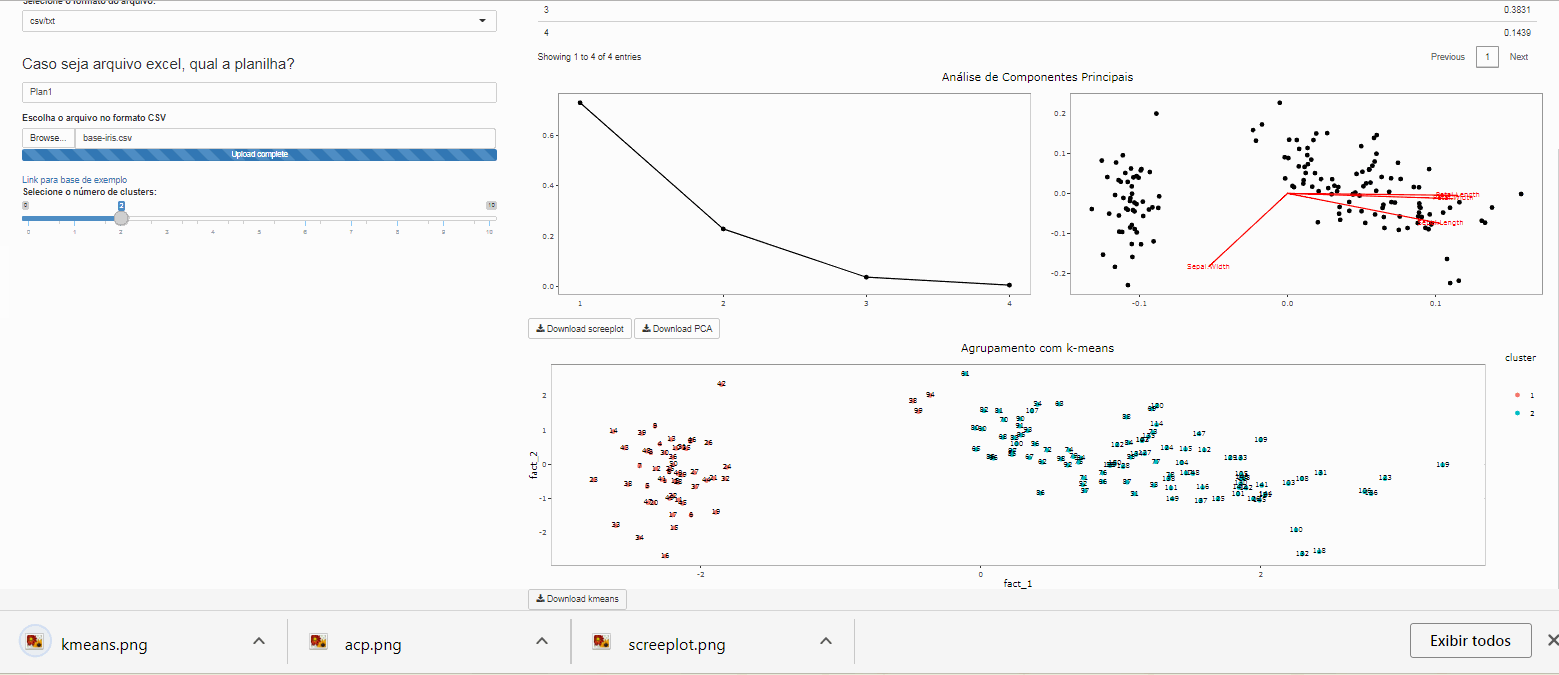
Este aplicativo permite que usuário selecione qualquer base pessoal para realizar a análise de componentes principais e executar o agrupamento de dados por partição Kmeans. Pode ser um arquivo do tipo csv, txt ou mesmo excel, caso seja um arquivo excel é necessário informar em qual planílha se encotram os dados

Análise de componentes principais
A análsie de componentes principais foi realizada com a função prcomp(), para mais informações sobre seu uso consultar o manual.
A análise é basicamente a mesma que a executada com a função princomp, porém o retorno da função é diferente, veja:
| prcomp() | princomp() | Descrição |
|---|---|---|
| sdev | sdev | Desvios-padrão dos principais componentes |
| rotation | loadings | A matriz de loadinds (carregamentos) das variáveis (as colunas são eigenvectors) |
| center | center | A variável means (significa que foram resgatados) |
| scale | scale | Escala aplicada a cada variável |
| x | scores | As coordenadas dos indivíduos (observações) nos componentes principais |
Seu uso no aplicativo:

Método não hierárquico de agrupamento K-means
Esta é uma das mais populares abordagens de agrupamento de dados por partição. A partir de uma escolha inicial para os centróides, o algorítmo procede verificando quais exemplares são mais similares a quais centroides.
Vantagens:
- Tendem a maximizar a dispersão entre os centros de gravidade dos clusters (mantem os clusters bem separados)
- Simplicidade de cálculo, calcula somente as distâncias entre os objetos e os centros de gravidade dos clusters
Desvantagens:
- Depende dos conjuntos de sementes iniciais, principalmente se a seleção das sementes é aleatória
- Não há garantias de um agrupamento ótimo dos objetos
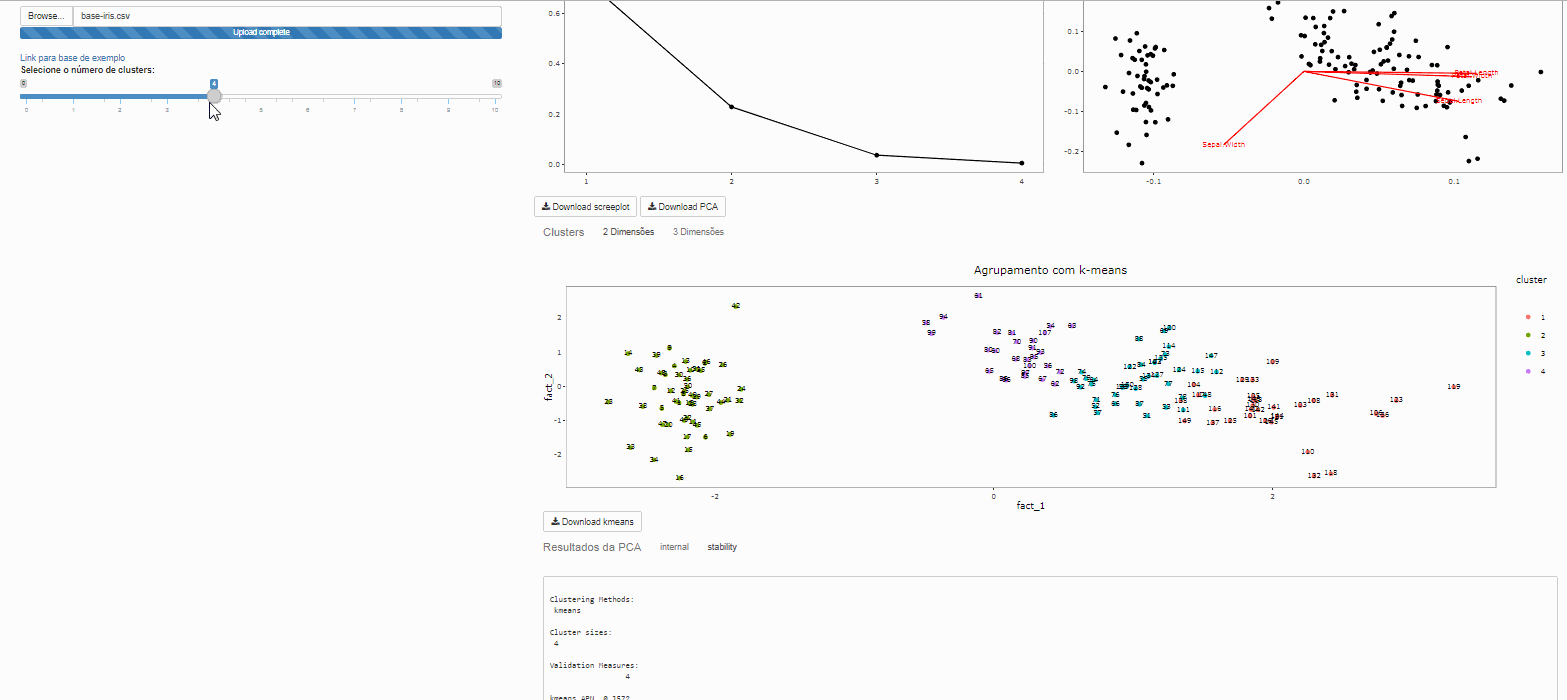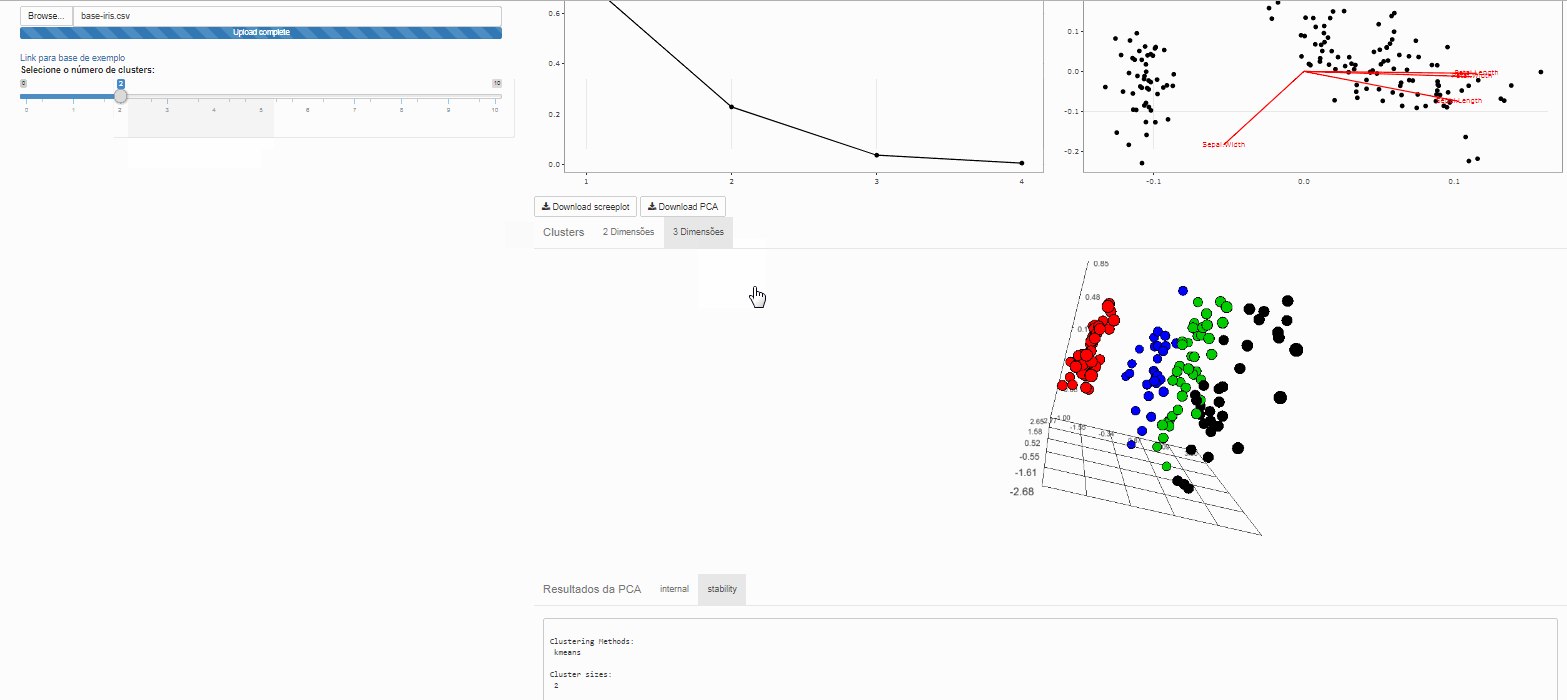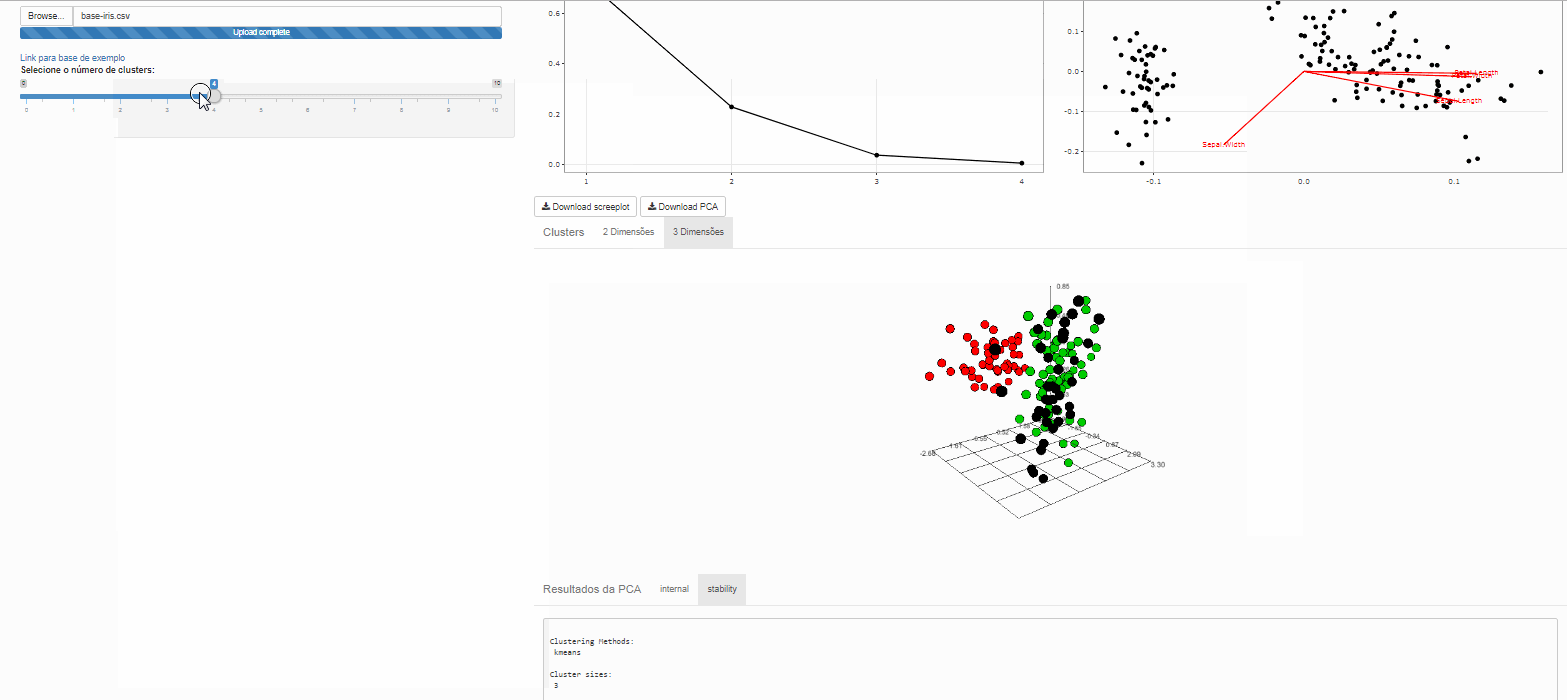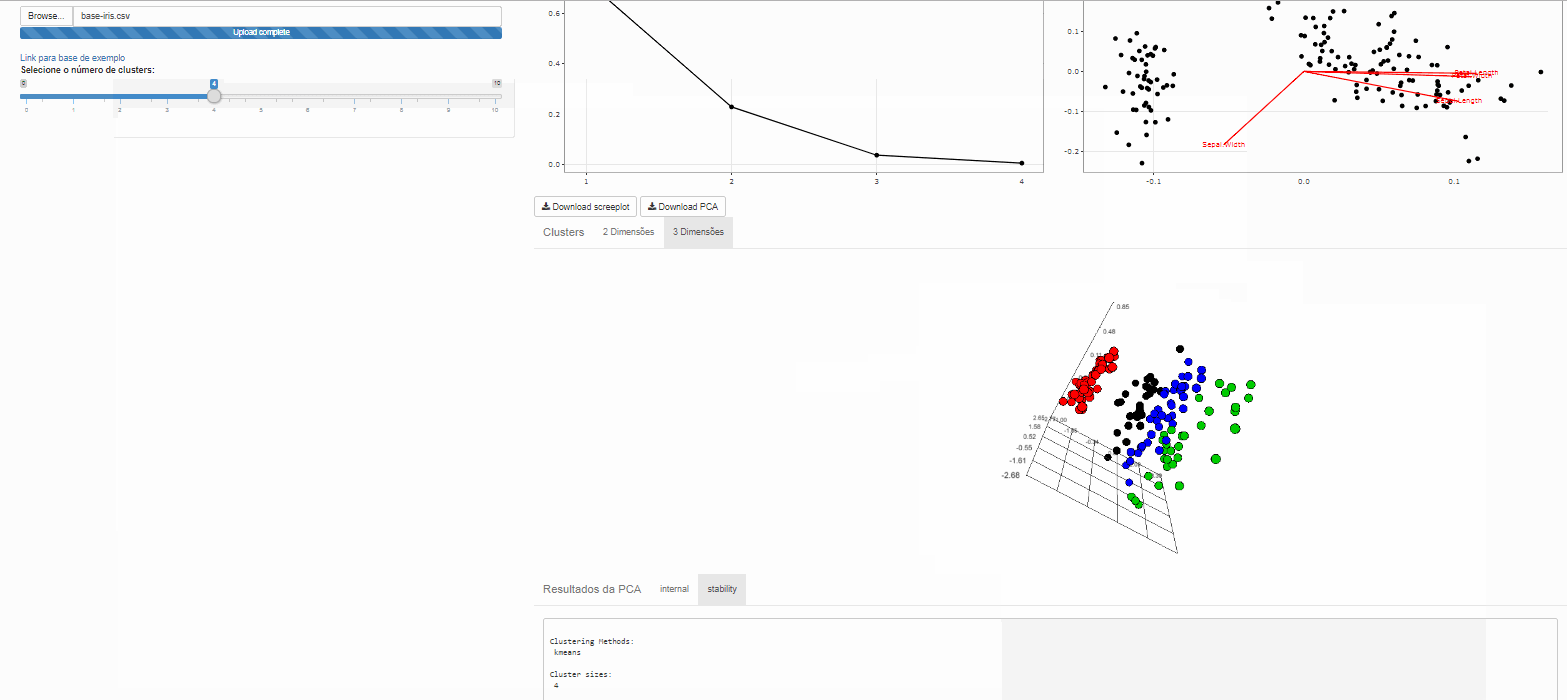
Clustes
Note que é possível variar o número de clusters de interesse

Download
Para fazer o download da versão estatica dos gráficos do aplicativo basta clicar no botão de Download
Avaliando os resultados com clvalid::clvalid()
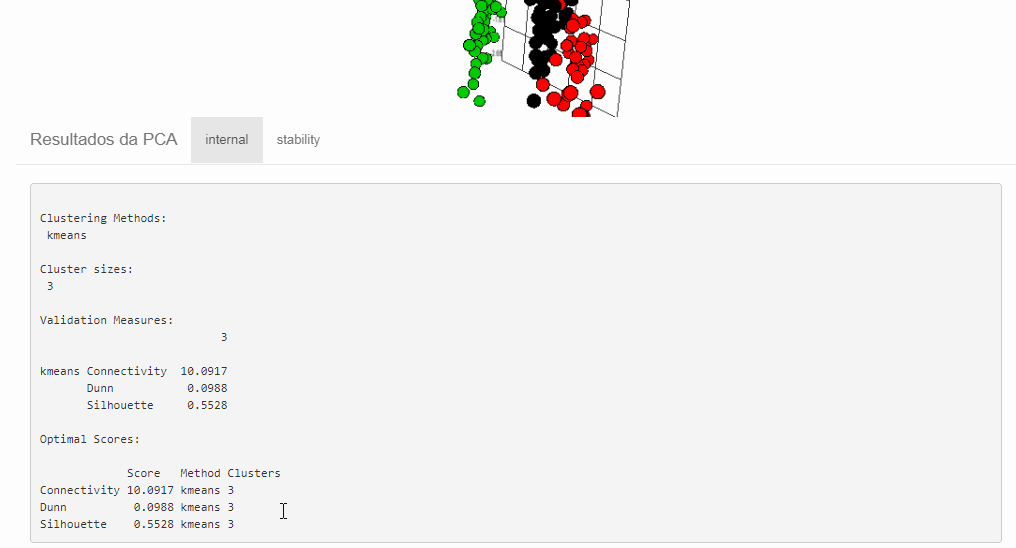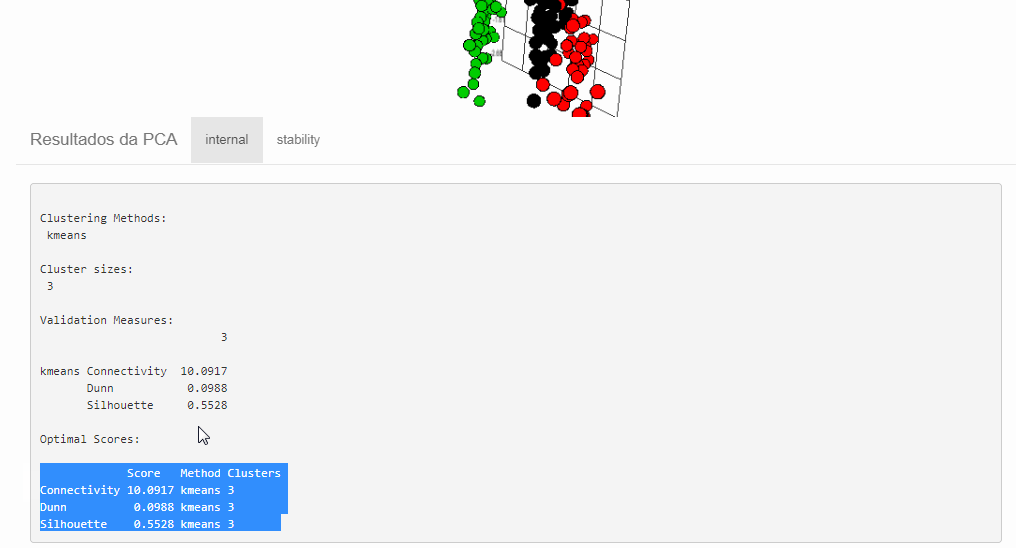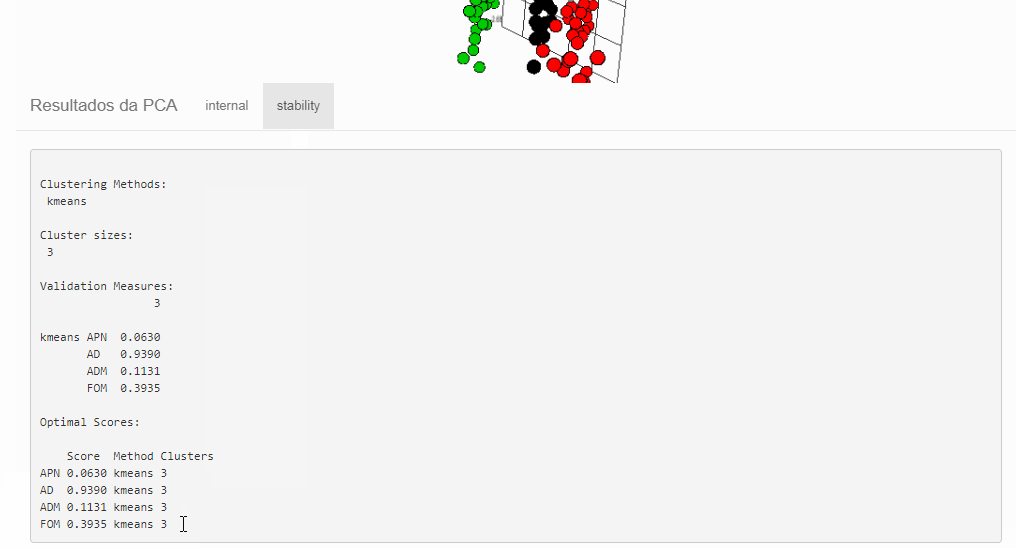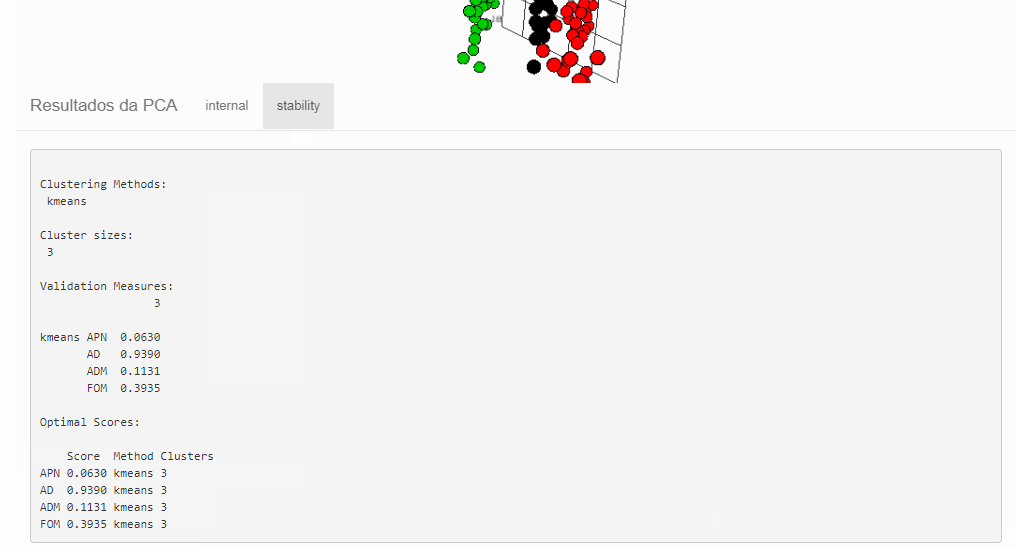
Este pacote faz os calculos das medidas que avaliam se os clusters são compactos, bem separados e estáveis.
Vejamos os tipos de medidas:
Medidas de validação:
- conectividade: relativa ao grau de vizinhança entre objetos em um mesmo cluster, varia entre 0 e infinito e quanto menor melhor.
- silhueta: homogeneidade interna, assume valores entre -1 e 1 e quanto mais próximo de 1 melhor.
- índice de Dunn: quantifica a separação entre os agrupamentos, assume valores entre 0 e 1 e quanto maior melhor.
Medidas de estabilidade:
- APN - average proportion of non-overlap: proporção média de observações não classificadas no mesmo cluster nos casos com dados completos e incompletos. Assume valor no intervalo [0,1], próximos de 0 indicam agrupamentos consistentes.
- AD - average distance: distância média entre observações classificadas no mesmo cluster nos casos com dados completos e incompletos. Assume valores não negativos, sendo preferíveis valores próximos de zero.
- ADM - average distance between means: distância média entre os centroides quando as observações estão em um mesmo cluster. Assume valores não negativos, sendo preferíveis valores próximos de zero.
- FOM - figure of merit: medida do erro cometido ao usar os centroides como estimativas das observações na coluna removida. Assume valores não negativos, sendo preferíveis valores próximos de zero.
Referências:
Mais informações sobre a avaliação dos resultados do agrupamento podem ser conferidas em um post que falo sobre Análise multivariada em R





Share this post
Twitter
LinkedIn
Email