




































Agente para análise interpretativa de ligações de telemarketing
Neste post vamos criar um agente para extrair insights estruturados de ligações de telemarketing, transformando gravações de áudio em um relatório analítico

Por que analisar ligações de telemarketing com IA?
Quem nunca recebeu aquela ligação de telemarketing no momento mais inoportuno? Seja oferecendo um cartão de crédito, cobrando uma dívida ou tentando vender internet, essas ligações fazem parte do nosso cotidiano. Mas você já parou para pensar na quantidade de informações valiosas que existem nessas conversas?
Para empresas que operam call centers, analisar essas ligações manualmente é uma tarefa hercúlea. Imagine ter que ouvir centenas ou milhares de ligações por dia para:
- Avaliar a qualidade do atendimento
- Identificar problemas recorrentes
- Detectar possíveis fraudes
- Treinar equipes com base em casos reais
- Garantir compliance e conformidade legal
O desafio vai além da transcrição de textos
Analisar ligações de telemarketing apresenta desafios que vão muito além da simples transcrição de áudio para texto. O grande volume de dados, a necessidade de identificar corretamente quem está falando em áudios mono (onde todas as vozes estão em um único canal) e a extração de informações relevantes a partir de conversas não estruturadas tornam o processo complexo e exigem soluções especializadas.
Entre os principais obstáculos técnicos estão: converter fala em texto com precisão mesmo diante de sotaques e ruídos, diarizar os speakers (diferenciar atendente e cliente), transformar transcrições em dados estruturados (como sentimento, tipo de ligação e problemas), além de garantir escalabilidade para processar milhares de ligações de forma eficiente, preferencialmente utilizando recursos como GPU.
Solução técnica: Abordagem em 4 etapas
Enquanto estudava para trablhar em um projeto com desafio semelhante, desenvolvi um pipeline em Python integrando três tecnologias de ponta, com foco em soluções gratuitas para estudo e prova de conceito. O projeto abrangeu desde a aquisição das ligações até a extração de insights estruturados, utilizando recursos pagos em ambiente de produção, mas priorizando ferramentas acessíveis para pesquisa e validação.
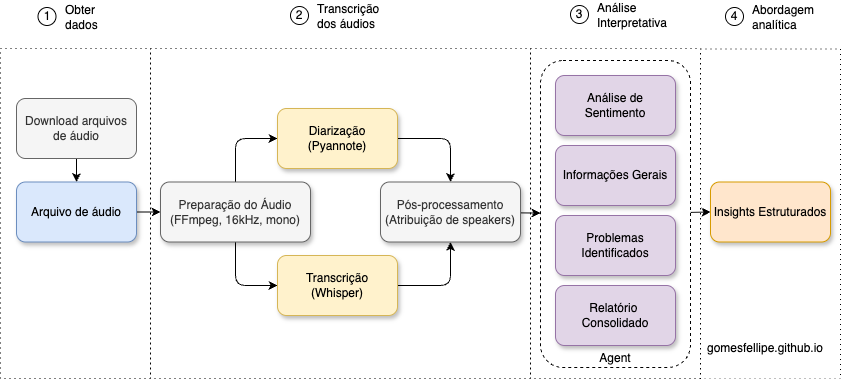
Fluxo de trabalho completo
As etapas principais foram:
- Coleta e preparação dos dados: Download e segmentação dos áudios com
yt_dlp,pydubeffmpeg. - Transcrição dos áudios:
- Diarização/segmentação por locutor: Utilizando o modelo de diarização do Pyannote.audio
- Reconhecimento automático de fala (ASR): Modelos gratuitos do Whisper da OpenAI hospedados na Hugging Face.
- Análise interpretativa: Extração de informações estruturadas com GPT da OpenAI e o framework LangChain .
- Abordagem analítica: Exploração dos dados, criação de dashboards e, eventualmente, construção de modelos preditivos (por exemplo, prever se a venda foi concluída).
Tecnologias Utilizadas:
- Whisper (OpenAI): Modelo state-of-the-art para transcrição de áudio
- Pyannote.audio: Framework especializado em diarização de speakers
- LangChain: Framework de LLMs para extração estruturada
- Python: Orquestração de todo o pipeline
- Google Colab: Ambiente com GPU gratuita
Este post vai cobrir apenas a terceira etapa do pipeline: a análise interpretativa das transcrições. Vamos mostrar como transformar o texto bruto das ligações em informações estruturadas e acionáveis usando agentes de GenAI, detalhando o processo de extração automática de sentimentos, problemas, resultados e respostas criativas a partir das conversas.
Dados utilizados
Para este experimento, selecionei alguns vídeos de esquetes de comédia sobre telemarketing disponíveis no YouTube e extraí um arquivo de áudio para cada ligação, segmentando as conversas individualmente. Veja um exemplo:
A transcrição dos áudios foi realizada utilizando Whisper para reconhecimento de fala e Pyannote para diarização dos locutores. Desenvolvi um script que integra essas ferramentas utilizando recursos de GPU em ambientes como Kaggle e Google Colab, o que permite processar grandes volumes de áudio gratuitamente.
Veja como ficou o resultado após a atribuição dos speakers no pós-processamento:
SPEAKER_00: Eu gostaria de falar com o Eliel Clayton de Oliveira.
SPEAKER_01: Ele não tá, tá pra fazenda. Liga amanhã, ele deixou o celular.
SPEAKER_00: Ah, tudo bem. Eu posso deixar o telefone pra contato com ele no internet? Quem é você? Você é namorada dele? Não, eu sou uma da assessoria de cobrança.
SPEAKER_01: Da onde? Da outra fazenda? Da fazenda Bonança?
SPEAKER_00: Não, senhora. Eu sou da assessoria da bebê financeira. Ah, estavam então da Bahia, né? Vou falar pra ele que ligaram pra ele então, tá?
SPEAKER_01: É da bebê financeira, assessoria da bebê financeira.
SPEAKER_00: Você teve um bebê com ele? Aonde você tá, minha filha? Não, senhora, assessoria da bebê financeira.
SPEAKER_01: Estão falando que tem uma mulher que tem um bebê do Eliel.
SPEAKER_00: Acho melhor você ligar amanhã então, pra ver com ele, pra ver o DNA.⚠️ Naturalmente, todo modelo de transcrição apresenta uma taxa de acerto que pode variar de acordo com a qualidade do áudio, sotaques e presença de ruídos.
Neste post o foco está na construção do agente de análise interpretativa, assumindo que as transcrições já estão disponíveis e prontas para uso. Na versão do projeto que foi para produção, utilizamos uma ferramenta diferente para a etapa de transcrição, mas como prova de conceito até que achei o resultado bem descente.
Análise estruturada com Agente de GenAI
É aqui que a mágica realmente acontece: com o poder do LangChain e o recurso de Structured Output, conseguimos transformar transcrições brutas de ligações em dados estruturados e acionáveis. Em vez de apenas ler textos longos e desorganizados, extraímos automaticamente sentimentos, problemas, resultados e até respostas criativas. Tudo pronto para análise, visualização ou integração com sistemas de negócio.
A ideia central se baseia no conceito de saída estruturada (Pydantic models) para fornecer ferramentas que forçam o modelo a devolver um JSON consistente que depois é facilmente consumido por pipelines e dashboards.
Schema Pydantic (Ver código)
# Análise de Sentimento
class SentimentoLigacao(BaseModel):
"""Análise de sentimento da ligação."""
sentimento_cliente: Literal["positivo", "neutro", "negativo", "irritado"]
sentimento_atendente: Literal["profissional", "neutro", "agressivo", "impaciente"]
nivel_conflito: Literal["baixo", "medio", "alto"]
# Informações da Ligação
class InformacaoLigacao(BaseModel):
"""Informações extraídas da ligação."""
tipo_ligacao: Literal["cobranca", "oferta_produto", "suporte", "pesquisa", "fraude"]
empresa_mencionada: Optional[str] = None
produto_servico: Optional[str] = None
resultado_ligacao: Literal["sucesso", "recusa", "desligou", "nao_resolvido", "fraude_detectada"]
cliente_interessado: bool
# Identificação de Problemas
class ProblemaIdentificado(BaseModel):
"""Problemas identificados na ligação."""
tem_problema: bool
tipo_problema: Optional[Literal["cobranca_indevida", "cancelamento",
"atendimento_ruim", "fraude", "outro"]] = None
descricao_problema: Optional[str] = None
requer_followup: bool
# Respostas Criativas
class RespostasCriativas(BaseModel):
"""Respostas criativas ou inusitadas do cliente."""
teve_resposta_criativa: bool
tipo_resposta: Optional[Literal["humor", "desculpa_criativa",
"contra_ataque", "confusao_proposital"]] = None
citacao: Optional[str] = None
# Schema agregador: um único resultado que engloba todos
class RelatorioLigacao(BaseModel):
"""Relatório consolidado da ligação. Preencha apenas os blocos aplicáveis."""
sentimento: Optional[SentimentoLigacao] = None
informacao: Optional[InformacaoLigacao] = None
problema: Optional[ProblemaIdentificado] = None
respostas_criativas: Optional[RespostasCriativas] = NonePara criar o agente de análise interpretativa, encapsulamos toda a configuração do modelo de linguagem, defindo o schema de saída estruturada e estabelecendo as instruções para que o agente atue como um verdadeiro especialista em ligações de telemarketing. Com essa abordagem, garantimos que apenas informações realmente presentes na transcrição sejam extraídas, tornando o processo robusto, auditável e pronto para uso em escala, ou seja, para protótipos ou aplicações em produção.
Instanciando o agente (exemplo)
def instance_agent(api_key: str):
model = ChatOpenAI(model="gpt-4o", api_key=api_key, temperature=0)
agent = create_agent(
model=model,
tools=[],
response_format=ToolStrategy(
schema=RelatorioLigacao,
handle_errors=True
),
system_prompt=(
"Você é um especialista em análise de ligações de telemarketing.\n"
"Dado uma transcrição, preencha somente os blocos do relatório que fizerem sentido.\n"
"- Se não houver problema, deixe 'problema' como null.\n"
"- Se não houver respostas criativas, deixe 'respostas_criativas' como null.\n"
"- Seja conservador: só preencha quando tiver evidência no texto."
),
)
return agent
agent = instance_agent(api_key=OPENAI_API_KEY)
result = agent.invoke({
"messages": [{"role": "user", "content": transcriptions['audio_00']}]
})
result["structured_response"].model_dump()Veja qual foi a saída obtida aplicando no nosso exemplo de áudio:
{
'sentimento': {
'sentimento_cliente': 'irritado',
'sentimento_atendente': 'impaciente',
'nivel_conflito': 'alto'
},
'informacao': {
'tipo_ligacao': 'cobranca',
'empresa_mencionada': None,
'produto_servico': None,
'resultado_ligacao': 'nao_resolvido',
'cliente_interessado': False
},
'problema': None,
'respostas_criativas': {
'teve_resposta_criativa': True,
'tipo_resposta': 'humor',
'citacao': 'Eu agora, eu tô tomando é uma Heineken, uma hora dessa. Tá entendendo?'
}
}Loop para processar todos os áudios (Ver código)
extractions = {}
for file_name, transcription in transcriptions.items():
analysis = agent.invoke({"messages": [{"role": "user", "content": transcription}]})
structured = analysis.get("structured_response")
extracted = structured.model_dump() if structured is not None else None
extractions[file_name] = extracted
# Salvar cache da execução
with open(os.path.join(path_extractions, f"{file_name}.json"), "w", encoding="utf-8") as fh:
json.dump(extracted, fh, ensure_ascii=False, indent=2)Insights estruturados
Após processar todos os áudios podemos criar um dashboard que transforma as extrações em KPIs acionáveis, permitindo visualizar rapidamente métricas como taxa de ligações não resolvidas, distribuição dos tipos de ligação, níveis de conflito, frequência de respostas criativas e outros indicadores essenciais para tomada de decisão e melhoria contínua dos processos.Ver código do Dashboard
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.patches import Rectangle
import numpy as np
# criar DataFrame a partir do dicionário de extrações
df = pd.DataFrame.from_dict(extractions, orient='index')
# garantir que campos nulos sejam tratados como dicts vazios para normalização
for col in ['sentimento', 'informacao', 'problema', 'respostas_criativas']:
df[col] = df[col].apply(lambda x: x if isinstance(x, dict) else {})
# normalizar cada bloco e juntar
sent_df = pd.json_normalize(df['sentimento']).add_prefix('sentimento_')
info_df = pd.json_normalize(df['informacao']).add_prefix('informacao_')
prob_df = pd.json_normalize(df['problema']).add_prefix('problema_')
resp_df = pd.json_normalize(df['respostas_criativas']).add_prefix('respostas_')
df_extractions = pd.concat([sent_df, info_df, prob_df, resp_df], axis=1)
df_extractions.index = df.index
df_extractions.index.name = 'file'
df_extractions.reset_index(inplace=True)
# Configurar estilo
sns.set_style("white")
plt.rcParams.update({
'figure.facecolor': 'white',
'axes.facecolor': 'white',
'savefig.facecolor': 'white'
})
sns.set_palette("husl")
# Criar figura com subplots
fig = plt.figure(figsize=(14, 12))
gs = fig.add_gridspec(4, 4, hspace=0.4, wspace=0.4)
# Cores personalizadas
colors_main = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#FFA07A', '#98D8C8', '#F7DC6F']
colors_sentiment = {'neutro': '#95E1D3', 'irritado': '#F38181', 'profissional': '#4A90E2'}
colors_conflict = {'baixo': '#A8E6CF', 'medio': '#FFD93D', 'alto': '#FF6B6B'}
# ============= TÍTULO PRINCIPAL =============
fig.suptitle('Análise de Ligações de Telemarketing com Agent',
fontsize=28, fontweight='bold', y=0.9)
# ============= 1. MÉTRICAS PRINCIPAIS (agora vem primeiro) =============
ax7 = fig.add_subplot(gs[0, :])
ax7.axis('off')
# Calcular métricas
total_ligacoes = len(df_extractions)
taxa_criatividade = (df_extractions['respostas_teve_resposta_criativa'].sum() / total_ligacoes) * 100
taxa_irritacao = (df_extractions['sentimento_sentimento_cliente'] == 'irritado').sum() / total_ligacoes * 100
taxa_nao_resolvido = (df_extractions['informacao_resultado_ligacao'] == 'nao_resolvido').sum() / total_ligacoes * 100
taxa_conflito_alto = (df_extractions['sentimento_nivel_conflito'] == 'alto').sum() / total_ligacoes * 100
# Criar caixas de métricas
metrics = [
('Total de Ligações', f'{total_ligacoes}', '#4A90E2'),
('Taxa de Criatividade', f'{taxa_criatividade:.1f}%', '#4ECDC4'),
('Taxa de Irritação', f'{taxa_irritacao:.1f}%', '#FF6B6B'),
('Não Resolvidos', f'{taxa_nao_resolvido:.1f}%', '#FFA07A'),
('Conflito Alto', f'{taxa_conflito_alto:.1f}%', '#F38181')
]
x_positions = np.linspace(0.05, 0.85, len(metrics))
for i, (label, value, color) in enumerate(metrics):
rect = Rectangle((x_positions[i], 0.25), 0.15, 0.5,
facecolor=color, linewidth=3,
transform=ax7.transAxes, zorder=2)
ax7.add_patch(rect)
ax7.text(x_positions[i] + 0.075, 0.58, value,
ha='center', va='center', fontsize=22, fontweight='bold',
color='white', transform=ax7.transAxes, zorder=3)
ax7.text(x_positions[i] + 0.075, 0.18, label,
ha='center', va='center', fontsize=11, fontweight='bold',
transform=ax7.transAxes, zorder=3, wrap=True)
# ============= 2. SENTIMENTO DO CLIENTE =============
ax1 = fig.add_subplot(gs[1, 0:2])
sentimento_counts = df_extractions['sentimento_sentimento_cliente'].value_counts()
# usar cinza para "neutro" (case-insensitive), caso contrário usar palette existente
neutral_color = '#B0B0B0'
colors_sent = [
neutral_color if str(x).strip().lower() == 'neutro' else colors_sentiment.get(x, '#95E1D3')
for x in sentimento_counts.index
]
sent_labels = [str(x).replace('_', ' ').upper() for x in sentimento_counts.index]
bars1 = ax1.bar(sent_labels, sentimento_counts.values, color=colors_sent, linewidth=2)
ax1.set_title('Sentimento do Cliente', fontsize=16, fontweight='bold', pad=15)
ax1.set_ylabel('', fontsize=12, fontweight='bold')
ax1.set_xlabel('', fontsize=12, fontweight='bold')
for bar in bars1:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height,
f'{int(height)}',
ha='center', va='bottom', fontsize=14, fontweight='bold')
ax1.grid(axis='y', alpha=0.3)
# aumentar limite do eixo y em 5%
max_h1 = max(bar.get_height() for bar in bars1)
ax1.set_ylim(0, max_h1 * 1.15)
# ============= 3. NÍVEL DE CONFLITO =============
ax2 = fig.add_subplot(gs[1, 2:4])
conflito_counts = df_extractions['sentimento_nivel_conflito'].value_counts()
colors_conf = [colors_conflict.get(x, '#A8E6CF') for x in conflito_counts.index]
conf_labels = [str(x).replace('_', ' ').upper() for x in conflito_counts.index]
bars2 = ax2.bar(conf_labels, conflito_counts.values, color=colors_conf, linewidth=2)
ax2.set_title('Nível de Conflito', fontsize=16, fontweight='bold', pad=15)
ax2.set_ylabel('', fontsize=12, fontweight='bold')
ax2.set_xlabel('', fontsize=12, fontweight='bold')
for bar in bars2:
height = bar.get_height()
ax2.text(bar.get_x() + bar.get_width()/2., height,
f'{int(height)}',
ha='center', va='bottom', fontsize=14, fontweight='bold')
ax2.grid(axis='y', alpha=0.3)
# aumentar limite do eixo y em 5%
if len(bars2) > 0:
max_h2 = max(bar.get_height() for bar in bars2)
ax2.set_ylim(0, max_h2 * 1.15)
# ============= 4. TIPO DE LIGAÇÃO =============
ax3 = fig.add_subplot(gs[2, 0:2])
tipo_counts = df_extractions['informacao_tipo_ligacao'].value_counts()
explode = [0.05 if i == 0 else 0 for i in range(len(tipo_counts))]
wedges, texts, autotexts = ax3.pie(tipo_counts.values, labels=tipo_counts.index, autopct='%1.1f%%',
colors=colors_main, explode=explode, startangle=90,
textprops={'fontsize': 11})
ax3.set_title('Tipo de Ligação', fontsize=16, fontweight='bold', pad=15)
for autotext in autotexts:
autotext.set_color('white')
autotext.set_fontsize(12)
# ============= 5. RESULTADO DA LIGAÇÃO =============
ax4 = fig.add_subplot(gs[2, 2:4])
resultado_counts = df_extractions['informacao_resultado_ligacao'].value_counts()
res_labels = [str(x).replace('_', ' ').upper() for x in resultado_counts.index]
bars4 = ax4.barh(res_labels, resultado_counts.values, color=colors_main[:len(resultado_counts)], linewidth=2)
ax4.set_title('Resultado da Ligação', fontsize=16, fontweight='bold', pad=15)
ax4.set_xlabel('', fontsize=12, fontweight='bold')
for i, bar in enumerate(bars4):
width = bar.get_width()
ax4.text(width, bar.get_y() + bar.get_height()/2.,
f' {int(width)}',
ha='left', va='center', fontsize=12, fontweight='bold')
ax4.grid(axis='x', alpha=0.3)
# ============= 6. RESPOSTAS CRIATIVAS =============
ax5 = fig.add_subplot(gs[3, 0:2])
criativas_counts = df_extractions['respostas_teve_resposta_criativa'].fillna(False).astype(bool).value_counts()
counts5 = [criativas_counts.get(True, 0), criativas_counts.get(False, 0)]
labels5 = ['Com Resposta\nCriativa', 'Sem Resposta\nCriativa']
colors_criativas = ['#4ECDC4', '#FF6B6B']
wedges5, texts5, autotexts5 = ax5.pie(counts5,
labels=labels5,
autopct='%1.1f%%',
colors=colors_criativas,
startangle=90,
textprops={'fontsize': 12})
ax5.set_title('Respostas Criativas', fontsize=16, fontweight='bold', pad=15)
for autotext in autotexts5:
autotext.set_color('white')
autotext.set_fontsize(13)
# ============= 7. TIPOS DE RESPOSTA CRIATIVA =============
ax6 = fig.add_subplot(gs[3, 2:4])
tipo_resposta = df_extractions['respostas_tipo_resposta'].dropna().value_counts()
tipo_labels = [str(x).replace('_', ' ').upper() for x in tipo_resposta.index]
bars6 = ax6.barh(tipo_labels, tipo_resposta.values, color=colors_main[:len(tipo_resposta)], linewidth=2)
ax6.set_title('Tipos de Resposta Criativa', fontsize=16, fontweight='bold', pad=15)
ax6.set_xlabel('', fontsize=12, fontweight='bold')
for i, bar in enumerate(bars6):
width = bar.get_width()
ax6.text(width, bar.get_y() + bar.get_height()/2.,
f' {int(width)}',
ha='left', va='center', fontsize=12, fontweight='bold')
ax6.grid(axis='x', alpha=0.3)
plt.show()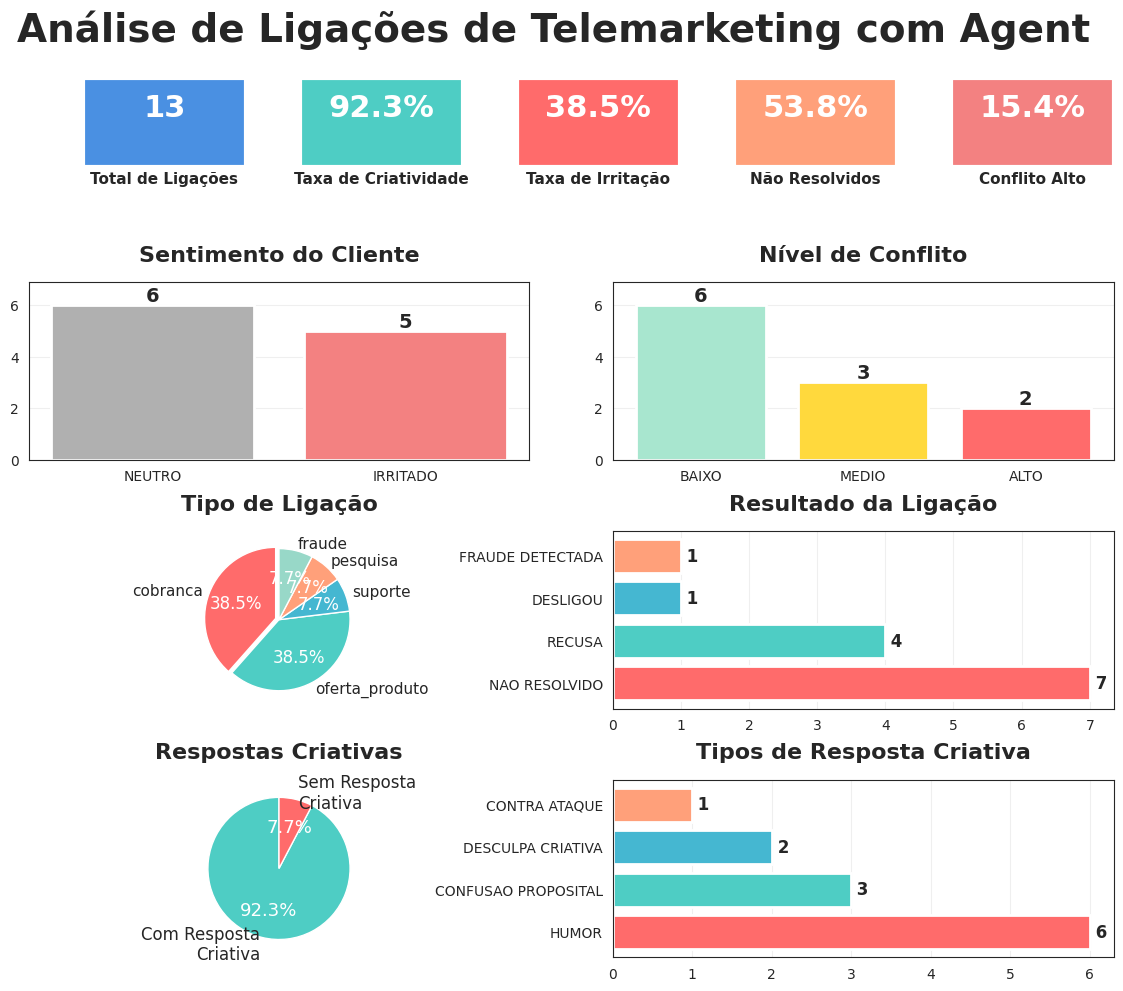
Fluxo de trabalho completo
Benefícios Práticos e ROI Mensurável
Para equipes que operam call centers e compliance, os ganhos são claros:
- Automação de QA (Análise de 100% das ligações vs. amostragem manual);
- Redução drástica no tempo de análise;
- Detecção precoce de problemas e fraudes;
- Treinamento baseado em casos reais e dados;
- Evidências estruturadas para auditoria;
- KPIs em tempo real e otimização de scripts (A/B testing).
Para empresas, isso significa decisões mais rápidas, menos custos com retrabalho e ROI tangível na operação.
Ética, licença e privacidade
O dataset aqui usado é público (sketches de comédia) e foi apenas para fins pessoal/educacional. Para qualquer uso comercial:
- Verifique licença dos materiais originais;
- Obtenha consentimento quando necessário;
- Anonimizar dados pessoais;
- Adotar práticas de privacidade e conformidade (LGPD / GDPR).
Conclusão: O futuro da análise de conversas
O que começou como um experimento com ligações de telemarketing se transformou em uma demonstração poderosa do que é possível quando combinamos as melhores tecnologias de IA disponíveis hoje. Em menos de 4 minutos, processamos 13 ligações e extraímos insights que levariam horas para analistas humanos descobrirem.
Recursos adicionais
Tutoriais Complementares:
- Meu post sobre Agentes Multiagente - LangChain em ação
- Detecção de Linguagem Tóxica - LLMs para análise de texto
- Análise de Sentimentos com LLM - Processamento de linguagem natural
Sobre o autor
Me chamo Fellipe Gomes, sou formado em estatística e atuo como cientista de dados desde 2018. Compartilho meus estudos e evolução por meio de artigos, tutoriais e projetos de código aberto. Se quiser saber mais sobre meu trabalho, sinta-se à vontade para entrar em contato através das minhas redes sociais LinkedIn, GitHub e Kaggle.
Gostou do conteúdo? Compartilhe e deixe suas dúvidas nos comentários. Sua experiência e feedback são fundamentais para continuar criando conteúdo de qualidade!


Share this post
Twitter
LinkedIn
Email