Introdução Definição do problema de negócio Soluções Estratégia analítica Decisões sobre a target Processamento dos Dados Dados Externos Feature Engineering Modelos Ensemble Post Processing Considerações Finais Introdução O TFUG - TensorFlow Users Group de São Paulo lançou uma nova competição no Kaggle onde o objetivo era desenvolver modelos para previsão de diagnóstico de síndromes respiratórias, que é um tema relacionado com um dos 17 tópicos de Desenvolvimento Sustentável das Nações Unidas - Boa saúde e bem-estar.
Introdução Definição do problema de negócio Análise Exploratória (em R) Estrutura da base Ano da base de dados Target Machine Learning (em Python) Importar dependencias Carregar dados Modelagem Submissão Considerações Finais Introdução No final de Janeiro desde ano (2022) o TFUG - TensorFlow Users Group de São Paulo lançou uma competição no Kaggle para prever as notas do enem que tem relação com um dos 17 tópicos de Desenvolvimento Sustentável das Nações Unidas - Educação de Qualidade.
Introdução Definição do problema de negócio Análise Exploratória (em R) Machine Learning (em Python) Importar dependências Stage 0: Feature Extraction com KNN Stage 1: Tuning XGBoost com Optuna Stage 2: Calcular Out-Of-Fold SHAP values Stage 3: Modelo Final com AutoGluon Conclusão Referências Introdução Em Agosto e 2021 a Porto Seguro lançou um desafio no Kaggle que consistia em estimar a propensão de aquisição de novos produtos. Tratava-se de um problema de classificação e foi bem desafiador principalmente por 2 motivos:
O problema envolvendo dados desbalanceados Objetivo Dependências Preparar dados Breve análise exploratória Modelagem Baselines Preparar Pipeline de dados com workflowsets Benchmark Conclusão Referências O problema envolvendo dados desbalanceados A tarefa de classificação com dados desbalanceados é muito comum na vida real podendo variar desde um leve viés até um enorme desequilíbrio na distribuição da classe de interesse. Problemas mais comuns envolvem:
Problema de negócio Uma tarefa comum no dia a dia de um estatístico (ou cientista de dados) é a elaboração de relatórios para passar ao restante da equipe e/ou tomadores de decisão os resultados encontrados e muitas vezes essa tarefa pode parecer desgastante quando os relatórios são muitos extensos e repetitivos.
Com a linguagem R, escrever relatórios estatísticos utilizando RMarkdown acaba sendo a escolha padrão por ser tão simples transformar as análises em documentos, apresentações e dashboards de alta qualidade com poucas linhas de código.
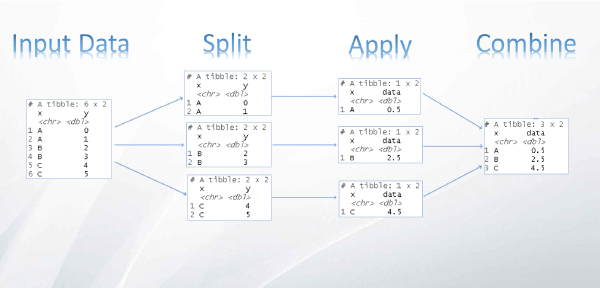
O método split-apply-combine Geralmente em uma análise de dados precisamos compreender, além do comportamento geral dos dados, o seu comportamento de acordo com alguns segmentos.
No famoso paper The Split-Apply-Combine Strategy for Data Analysis, Hadley Wickham descreve a abordagem “split-apply-combine” (dividir-aplicar-combinar) como uma das mais comuns em uma análise de dados. Em R essa tarefa pode ser feita por diversos caminhos, veja alguns dos modos de se fazer utilizando funções base do R e abordagens mais antigas:
⚠️ Nota de atualização (2026): Este post usa Ubuntu 16.04 LTS (EOL desde 2021), RStudio Server (renomeado para Posit Workbench) e Shiny Server na instância f1-micro do Google Cloud. Os passos gerais ainda funcionam, mas o Ubuntu mínimo recomendado hoje é o 22.04 LTS e os pacotes de instalação do RStudio/Posit mudaram de URL. Para instâncias novas, consulte a documentação atual do Posit Workbench.
Objetivo do post Uma das várias maneiras de se implementar o RStudio Server e o Shiny Server é através de serviços de nuvem que fornecem máquinas virtuais. Empresas gigantes no mercado como Amazon Web Services (AWS), Microsoft, Google, IBM, Oracle etc têm investido pesado nestes serviços e a escolha de qual cloud utilizar deve ser feita de acordo com a necessidade do usuário pois cada uma delas oferecem diferentes preços com diferentes custos/benefícios.
Perguntas Estudar em outra cidade têm suas vantagens e desvantagens, durante toda a graduação atravessei Baía de Guanabara pela Ponte Presidente Costa e Silva, (popularmente conhecida como Ponte Rio–Niterói) assim como todas as pessoas que fazem esse trajeto diariamente e diante de tanta beleza natural com a vista panorâmica da Baía como os espetáculos proporcionados pelo pôr do sol, os pássaros ou a beleza inegável do Pão de Açúcar também é notável a beleza fruto da maior habilidade humana: a criatividade. Temos o cristo, todos aqueles grandes barcos, o Porto do Rio de Janeiro com todas aquelas obras de Engenharia, ou até mesmo a própria Ponte, que por si só já é intrigante.
Kaggle Segundo o Wikipédia: “Kaggle é a maior comunidade mundial de cientistas de dados e machine learning.” Aprendo muito estudando as resoluções de alguns competidores pois lá é possível conferir tanto as metodologias utilizadas pelos competidores quando os códigos e é notável o cuidado dos participantes para que seja possível a reprodutibilidade dos resultados, o que pode impulsionar o aprendizado.
O Kaggle trabalha com a ideia de gamificação, que é um assunto do qual já escrevi em um post sobre gamificação e porque aprender R é tão divertido e gosto deste conceito de se criar jogos para motivar e engajar as pessoas em atividades profissionais e a ideia de se estar em um jogo possibilita doses de motivação especialmente a quem gosta de competir.
Brasil vs Argentina e Text Mining A copa do mundo esta ai novamente e como não poderia ser diferente, com ela surgem novos quintilhões de bytes todos os dias, saber analisar esses dados é um grande desafio pois a maioria dessa informação se encontra de forma não estruturada e além do desafio de captar esses dados ainda existem mais desafios que podem ser ainda maiores, como o de processá-los e obter respostas deles.
Google Trends O Google Trends é uma ferramenta gratuita, muito poderosa e que pode ser implementada para ajudar em nossas estratégias de análises.
Através dele temos acesso a uma gigantesca base de dados que reúne os temas mais pesquisados na plataforma da Google possibilitando acessar dados de busca desde o ano de 2004.
Através de suas séries temporais podemos avaliar a presença de pedrões, obter noções de tendência, sazonalidade e até mesmo arriscar algumas previsões.
Relatórios de alta qualidade só com \(\LaTeX\)? Como já mencionei no post sobre tabelas incríveis com R, a tarefa de um estatístico (ou Data Scientist, em sua versão diluída e mais comercial) vai muito além do planejamento, análises, inferência, sumarização e interpretação de observações para fornecer a melhor informação possível a partir do dados disponíveis. A produção final dos relatórios é fundamental e na grande maioria das vezes utiliza-se a linguagem \(\LaTeX\), mas será que ela é realmente a única opção?
Você costuma ler o manual? Quando éramos crianças, geralmente não tínhamos o costume de ler o manual das coisas, não é mesmo? Particularmente eu sempre gostei de aprender como as coisas funcionavam diretamente com a prática para poder usá-las depois. Adorava buscar entender como as coisas se encaixavam ao montar os brinquedinhos do kinder-ovo sem ler as instruções ou criar diferentes combinações com lego customizados, por exemplo. Acredito que isso seja da natureza de toda criança!
Onde estão os blocos? Fevereiro começando e o carnaval já está ai, especialmente se você mora no Rio de Janeiro já deve ter passado por algum bloco e a pergunta que todo mundo faz no carnaval pelo menos uma vez é: “Onde tem bloco?”.
TL;DR
Usamos ggmap para geocodificar (transformar endereço em latitude/longitude) os blocos de carnaval. O pacote leaflet (com leaflet.extras) plota tudo num mapa interativo. A limpeza de texto usa a função ajustar_nomes() do post sobre manipulação de strings. Baseado nessa pergunta resolvi fazer esse post especial, vamos utilizar os pacotes ggmap e leaflet para buscar as coordenadas geográficas do endereço dos blocos e representa-los num mapa agradável de navegar
Importância da apresentação dos dados O trabalho de quem analisa dados vai muito além de planejar, resumir e interpretar observações: apresentar bem os resultados é parte essencial de qualquer projeto ou pesquisa. Não é à toa que já existe até uma área dentro da ciência de dados focada nisso, com o título de "Data Artist".
Além dos pacotes que ajudam a apresentar as figuras geradas nas análises (como mostrei nos posts sobre a qualidade do ajuste de modelos e sobre avaliar o ajuste pela abordagem bayesiana), contamos com pacotes que apresentam tabelas de forma elegante e até interativa.
Além da limpeza da base de dados, das análises e da aplicação de metodologias estatísticas, escrever relatórios é uma tarefa indispensável e que ocupa boa parte do tempo de quem trabalha com dados. Como disse Khalil Gibran, é preciso transformar em palavras aquilo que já conhecemos em pensamentos. O problema é que ninguém quer gastar tempo precioso de análise brigando com a formatação do documento.
É aí que entram os templates. O pacote tufte, disponível no CRAN, resolve isso para quem escreve em RMarkdown: ele traz um layout pronto, elegante e focado no conteúdo, para você formatar menos e analisar mais. Este post mostra o que é esse estilo, como instalar e como usar os recursos que o tornam diferente.
O pacote dplyr A análise exploratória dos dados é uma tarefa de bastante relevância para entendermos a natureza dos dados e o tempo de análise é sempre muito precioso. É necessária bastante curiosidade e criatividade para fazer uma boa análise exploratória dos dados pois é difícil receber aqueles dados bonitinhos igual aos nativos do banco de dados do R.
A manipulação de dados é uma das etapas que mais consomem tempo em qualquer projeto, como comento no panorama da ciência de dados que escrevi para quem está começando. Aqui o foco é numa das ferramentas centrais para essa tarefa.
⚠️ Nota (2026): Este post foi reescrito. A versão original usava o pacote rdrop2, que dependia da API v1 do Dropbox — descontinuada desde setembro de 2023. O conteúdo abaixo mostra a abordagem atual com httr2 + API v2. A versão original foi preservada em index-old.html neste mesmo bundle para consulta.
Armazenar arquivos na nuvem é prática comum, e o Dropbox é um dos serviços mais usados para isso. Saber interagir com esses arquivos por código é uma habilidade valiosa para quem trabalha com dados: automatizar o vai e vem de arquivos economiza tempo, elimina erro manual e permite integrar fontes de dados externas em pipelines reprodutíveis.